OSTROŚĆ WIDZENIA
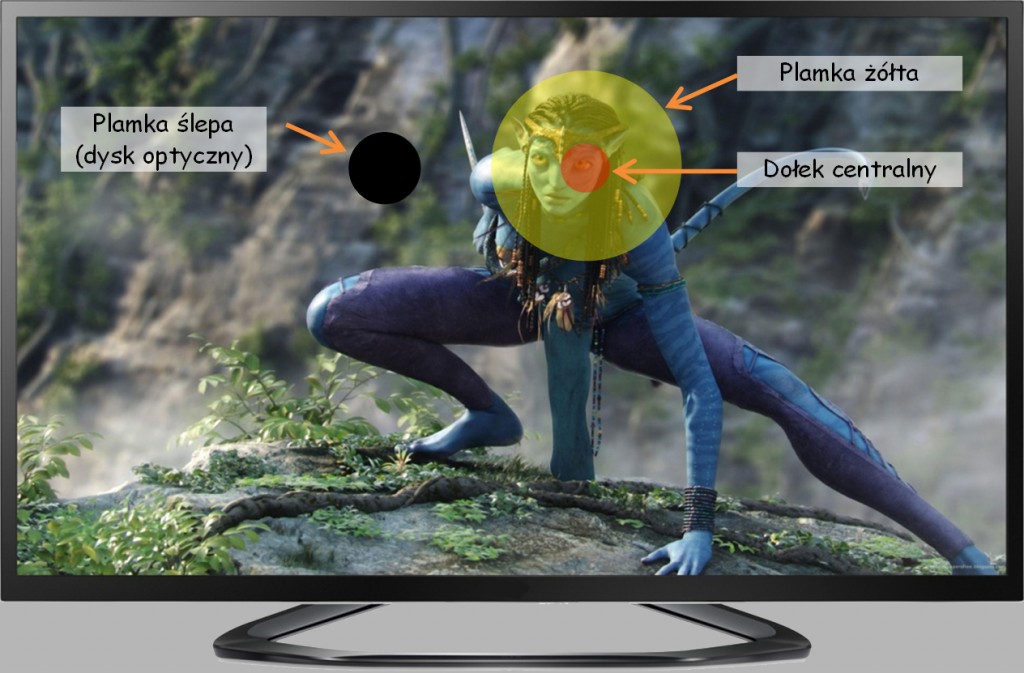
Zakres widzenia dołkiem centralnym
Jakie znaczenie dla widzenia ma opisany w poprzednich rozdziałach nierównomierny rozkład czopków na powierzchni siatkówki, czyli taki, że w jej środkowej części, a zwłaszcza w plamce żółtej, jest ich najwięcej, a na peryferiach – niewiele? Żeby odpowiedzieć na to pytanie przede wszystkim trzeba pamiętać, że dołek centralny obejmuje zaledwie 1,25o kąta pola widzenia (maksymalnie 2o), a cała plamka żółta – nie więcej niż 5,5o (Hendrickson, 2009; Duchowski, 2007). Oznacza to, że na odległość wyciągniętej ręki dołek centralny pokrywa powierzchnię nie większą niż paznokieć kciuka, o czym można się bardzo łatwo przekonać stosując jeden ze wzorów z poprzedniego rozdziału (Henderson i Hollingworth, 1999):
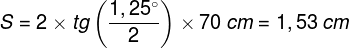
Można to sobie wyobrazić jeszcze inaczej. Przypuśćmy, że z odległości 2 m oglądamy film na telewizorze LCD 40” o powierzchni ekranu 5814 cm2:
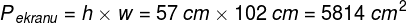
gdzie h to wysokość a w to szerokość prostokątnego obrazu. Obraz wyświetlony na ekranie jest rzutowany na całą siatkówkę oka, ale na plamkę żółtą pada tylko niewielki wycinek tego obrazu równy mniej więcej okręgowi o średnicy ok. 19 cm:
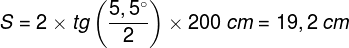
Znając średnicę okręgu łatwo możemy policzyć jego powierzchnię:
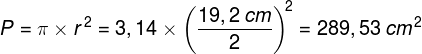
co mniej więcej odpowiada 5%, czyli 1/20 powierzchni całego ekranu:
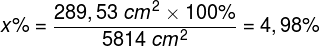
Jeszcze mniejszy fragment ekranu jest rzutowany na dołek centralny, równy okręgowi o średnicy ok. 4,4 cm:
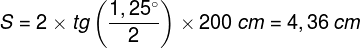
co odpowiada zaledwie 0,3% powierzchni całego ekranu telewizora:
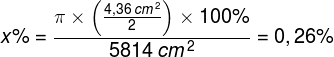
Podsumowując tę arytmetykę, w każdym punkcie fiksacji wzroku na ekranie telewizora mózg jest naprawdę przyzwoicie informowany o tym co się aktualnie znajduje tylko na bardzo małym jego fragmencie (ryc. 55). Reszta ekranu jest widziana z nieporównywalnie mniejszą dokładnością. Łatwo będzie można się o tym przekonać, gdy zostaną przeanalizowane jeszcze inne właściwości siatkówki.
Fotoreceptory i pole recepcyjne komórki zwojowej
Polskie słowo „siatkówka”, podobnie, jak jego angielski odpowiednik „retina” wywodzą się od słowa „sieć” (rete, to po łacinie „sieć”). Siatkówka jest skomplikowaną, pięciowarstwową strukturą złożoną z komórek nerwowych, wyścielających dno oka. Na przeważającym obszarze, oprócz warstwy czopków i pręcików, w siatkówce występują jeszcze cztery inne warstwy komórek: horyzontalnych (horizontal cells), dwubiegunowych (bipolar cells), amakrynowych (amacrine cells) i zwojowych (ganglion cells).
Każda warstwa komórek pełni specyficzne funkcje. Niektóre z tych funkcji są dobrze rozpoznane i opisane, o innych wciąż wiemy bardzo mało. Najogólniej rzecz ujmując, czopki i pręciki reagują na światło wpadające do oka, komórki dwubiegunowe, horyzontalne i amakrynowe zajmują się wstępnym opracowaniem danych o pobudzeniu fotoreceptorów, natomiast komórki zwojowe przesyłają do mózgu wyniki tych opracowań (Dowling, 2009).
Już w siatkówce oka zachodzi pierwszy etap przetwarzania danych wzrokowych. Chociaż na jej powierzchni znajduje się ok. 100 milionów fotoreceptorów, to informacja o ich aktywności jest przekazywana do mózgu tylko za pomocą 1 miliona komórek zwojowych (Wróbel, 2010). Oznacza to, że mózg, a dokładniej, kora mózgu, nie otrzymuje danych o stanie każdego fotoreceptora. Przeciwne, zdecydowana większość komórek światłoczułych jest połączona ze sobą w mniejsze lub większe grupy za pomocą komórek horyzontalnych, dwubiegunowych i amakrynowych. Grupa takich połączonych ze sobą fotoreceptorów jest z kolei związana z komórką zwojową, tworząc, tzw. pole recepcyjne komórki zwojowej (receptive field of the ganglion cell).
Nietrudno policzyć, że skoro wszystkich fotoreceptorów jest ponad 100 mln a komórek zwojowych ok. 1 mln, to średnio na jedną komórkę zwojową przypada ok. 100 fotoreceptorów. Liczebność czopków i pręcików na jednym milimetrze kwadratowym siatkówki zależy jednak od ich odległości od dołka centralnego. Podobnie, ich liczba jest różna w poszczególnych polach recepcyjnych w zależności od tego czy znajdują się bliżej czy dalej od dołka. Oznacza to, że im dalej od środka siatkówki tym większe są pola recepcyjne pojedynczych komórek zwojowych. Powyżej 20o kąta pola widzenia wielkość pól recepcyjnych jest już mniej więcej taka sama. Na ogół obejmują one powierzchnię ok. 1 mm2 siatkówki i łączą ze sobą po kilkaset fotoreceptorów (Młodkowski, 1998).
Najmniejsze pola recepcyjne pojedynczych komórek zwojowych znajdują się na obszarze plamki żółtej i obejmują od kilku lub kilkunastu czopków. W samym dołku centralnym pola recepcyjne tworzą już tylko pojedyncze czopki. W tym obszarze nie ma bowiem komórek horyzontalnych i amakrynowych, a informacja z fotoreceptora jest przekazywana za pomocą komórki dwubiegunowej bezpośrednio do komórki zwojowej. To miejsce, z którego informacja o obrazie rzutowanym na powierzchnię siatkówki jest przesyłana do mózgu z dokładnością do średnicy jednego czopka, czyli 3 μm! (= 0,003 milimetra) (Hendrickson, 2009).
Ostrość widzenia dołkiem centralnym i peryferiami siatkówki
Bezpośrednią konsekwencją zróżnicowanej wielkości pól recepcyjnych w zależności od ich umiejscowienia na siatkówce jest spadek dokładności widzenia w części peryferycznej, w której dominują wyłącznie duże pola recepcyjne. Gorsza dokładność widzenia wyraża się zmniejszeniem wrażliwości siatkówki na różnicowanie szczegółów obrazu rzutowanego na obszar zbudowany z dużych pól recepcyjnych. Z każdego pola recepcyjnego płynie bowiem do komórki zwojowej pojedynczy sygnał, który jest swego rodzaju uśrednieniem aktywności wszystkich czopków i/lub pręcików tworzących to pole. Im większa jest powierzchnia siatkówki, z której uśredniany jest sygnał, tym łatwiej o zagubienie szczegółów. Proces uśredniania sygnału można porównać do swego rodzaju „paczkowania” danych wzrokowych w mniejsze, bardziej syntetyczne formy (Troy, 2009).
Warto w tym miejscu przypomnieć, że duże pola recepcyjne znajdują się na tym obszarze siatkówki, w którym liczba czopków jest ustabilizowana na minimalnym poziomie oraz stopniowo zmniejsza się liczba pręcików. Stosunkowo niewielka liczba fotoreceptorów na obszarze peryferyjnym (tj. powyżej 10o kąta pola widzenia w warunkach dobrego oświetlenia i powyżej 20o – po zmroku), które są połączone ze sobą w duże pola recepcyjne powodują, że na znacznym obszarze siatkówki dokładność, z jaką mózg jest informowany o rzutowanym na nią obrazie jest stosunkowo niska (ryc. 56).
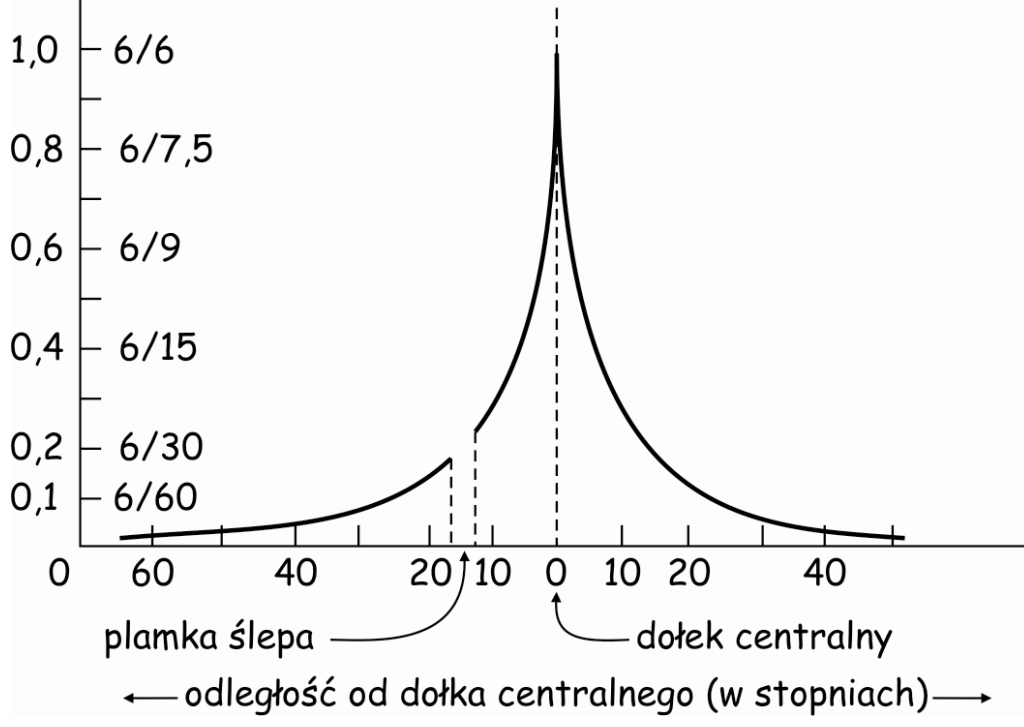
Żeby dobrze rozumieć wykres na ryc. 56 trzeba przypomnieć trochę historii badań nad ostrością widzenia. Oszacowanie ostrości widzenia opiera się na metodzie opracowanej przez duńskiego oftalmologa Hermanna Snellena w połowie XIX wieku. Zaproponował on, żeby ostrość wzroku określać jako stosunek odległości, z jakiej osoba badana patrzy na tzw. optotyp, do odległości, z jakiej powinien on być poprawnie rozpoznany (Niżankowska, 2000). Optotyp to, np. czarna litera E na białym tle widziana z takiej odległości, że jej elementy są różnicowane pod kątem 1’ (1/60 stopnia kątowego; ryc. 57).
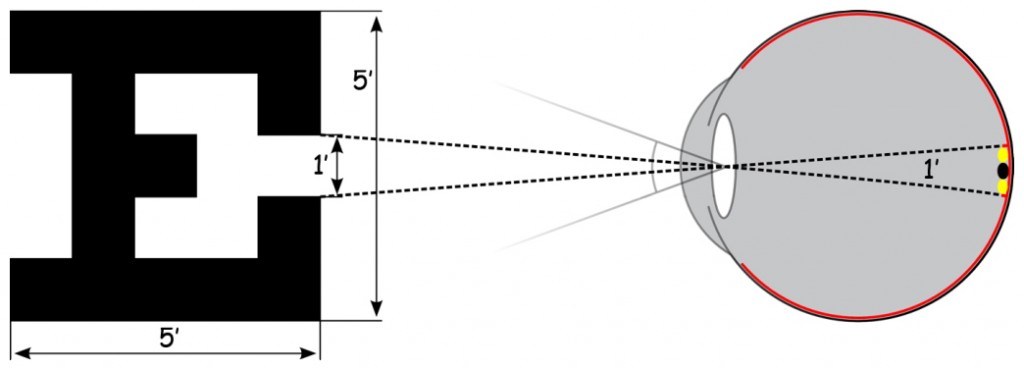
Idea jest prosta. Chodzi o to, żeby sprawdzić czy system wzrokowy osoby badanej jest w stanie zróżnicować dwa punkty na optotypie (np. odległość między szeryfami w literze E; ryc. 57). Jest to równoznaczne z pobudzeniem dwóch czopków w dołku centralnym, między którymi znajduje się jeden czopek niepobudzony. Wiadomo, że średnica jednego czopka wynosi ok. 0,003–0,004 mm (czyli ok. 3–4 µm). Biorąc pod uwagę odległość czopków od środka układu optycznego oka w soczewce można obliczyć kąt pod jakim światło musiałoby wpaść do wnętrza gałki ocznej, żeby oświetlić te dwa skrajne czopki. Ten kąt wynosi właśnie 1’.
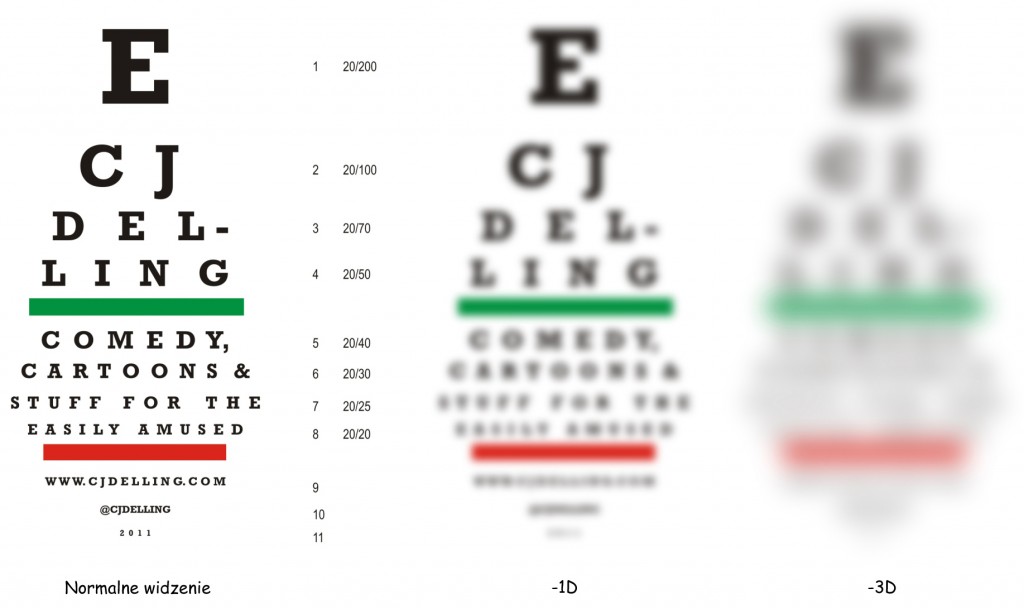
W celu standaryzacji badania ostrości wzroku Snellen opracował powszechnie znaną z gabinetów okulistycznych tablicę zawierającą litery o różnej wysokości, ułożone w 11 rzędach (ryc. 58, z lewej strony). Zapis dwóch liczb, np. 20/200, znajdujący się przy jednym z rzędów liter oznacza stosunek dwóch odległości: dystansu z jakiego przeprowadzany jest pomiar ostrości wzroku (tj. 20 stóp, czyli ok. 6 m) do dystansu, z jakiego litera w danym rzędzie powinna być poprawnie rozpoznawana za pomocą zdrowych oczu (tj. 200 stóp, czyli ok. 60 m). Innymi słowy, jeśli ktoś ma normalny wzrok to powinien rozpoznać literę E w pierwszym rzędzie z odległości 60 m.
Z wykresu na ryc. 56 wynika, że maksymalna ostrość widzenia za pomocą w pełni sprawnie funkcjonującego oka wynosi 1,0. Taką sprawność posiada wyłącznie jeden, niewielki obszar siatkówki, czyli dołek centralny (oznaczony wertykalną linią przerywaną w punkcie 0). Ostrości widzenia równej 1,0 odpowiada zdolność prawidłowego rozpoznawania liter w podkreślonym na czerwono ósmym rzędzie tablicy Snellena z odległości 20 stóp (20/20 stóp = 6/6 metrów).
Przypuśćmy, że najmniejsze litery, jakie osoba badana poprawnie rozpoznaje z odległości 20 stóp (6 m) to są litery C i J w drugim rzędzie tablicy Snellena (ryc. 58). Powinny one być poprawnie rozpoznane już z odległości 100 stóp (ok. 30 m). Oznacza to, że poziom nieostrości widzenia tej osoby wynosi 0,2 (20/100 = 0,2) i zdecydowanie wymaga szkieł korygujących tę wadę wzroku. Kiedy raz jeszcze spojrzymy na ryc. 56, to zauważymy, że wskaźnik ostrości widzenia równy lub mniejszy niż 0,2 odpowiada ostrości widzenia obrazu rzutowanego na siatkówkę powyżej 15o, czyli przypadający na jej obszar leżący daleko poza plamka żółtą.
Innymi słowy, jeżeli przyjmiemy, że maksymalna, czyli równa 1,0 ostrość widzenia jest związana z dołkiem centralnym, to powyżej 15o kąta pola widzenia wynosi ona już tylko 20%, czyli jest pięciokrotnie mniejsza i z każdym następnym stopniem kątowym jeszcze się zmniejsza.
Najsłynniejszy uśmiech świata
Zróżnicowana rozdzielczość kodowania obrazu w różnych częściach siatkówki oka może znacząco wpływać na sens obrazu. Neurobiolog, Margaret Livingstone (2000), pod wpływem sugestii Ernsta Gombricha (2005) dostrzegła, że oglądając Mona Lisę Leonarda da Vinci, w zależności od tego, na której części obrazu koncentrowała wzrok, miała wrażenie, że Mona Lisa uśmiecha się do niej inaczej. Kluczowa okazała się odległość oglądanego fragmentu od ust modelki Leonarda. Im dalej był położony ów fragment od jej ust (np. tło lub dłonie) tym bardziej jej uśmiech stawał się pogodny. Zdaniem Livingstone, odpowiedź kryje się w różnicy między obrazem rozmytym (nieostrym) a obrazem wyrazistym. Im bardziej oddalamy wzrok od ust Mona Lisy, tym bardziej stają się gładkie, pełne i zmysłowe.
Za pomocą komputerowego programu graficznego, Livingstone odtworzyła obraz twarzy Mona Lisy wtedy, gdy jest ona widziana wyraźnie, za pomocą czopków znajdujących się w dołku centralnym oraz gdy jej obraz jest rzutowany na dwie różne części peryferyczne siatkówki. Technicznie wyglądało to tak, że najpierw rozmywała obraz za pomocą funkcji gausowskiej (Gaussian blur), a następnie podnosiła kontrast przetworzonego zdjęcia, symulując w ten sposób utratę rozdzielczości, charakterystyczną dla widzenia peryferycznego. Powtórzyłem tę procedurę i jej efekty można zobaczyć na ryc. 59.

Livingstone (2000) zasugerowała, że jej hipoteza wyjaśniająca tajemniczy uśmiech Mona Lisy w zależności od odległości oglądanego fragmentu obrazu od jej ust jest co najmniej równie prawdopodobna, jak odwołanie się do stosowanej przez Leonarda da Vinci techniki zacierania krawędzi malowanych obiektów i ich części (sfumato). Do tej techniki jeszcze powrócę w dalszej części tej książki, ponieważ pozwala ona lepiej zrozumieć rolę, jaką kontury widzianych rzeczy odgrywają w ich interpretacji.
O widzeniu centralnym i peryferycznym w malarstwie i fotografii
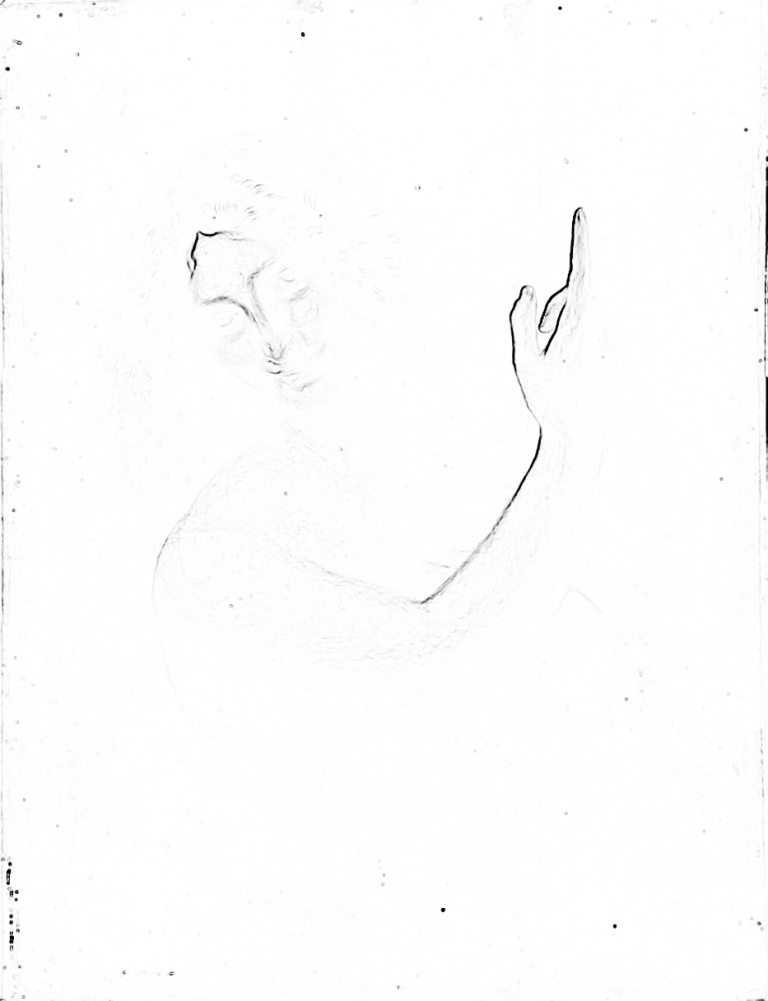
W odniesieniu do większości obrazów malarskich i fotograficznych można powiedzieć, że niemal cała ich powierzchnia jest wypełniona równie wyrazistymi obiektami. Wyjątek stanowią – i to nie zawsze – np. odległe plany w krajobrazie, bliżej nieokreślone tła lub efekty uzyskiwane poprzez zmniejszanie głębi ostrości. Są jednak również i takie przykłady obrazów, których kompozycja jest podkreślona przez wyrazistość jednych fragmentów i niemal całkowity brak wyrazistości innych. Kiedy przyjrzymy się niektórym autoportretom Rembrandta odkryjemy, że właściwie tylko twarz artysty została namalowana z dużą dbałością o szczegóły a obecność innych fragmentów jest zaledwie zasygnalizowana (np. dłonie) (ryc. 60 i ryc. 61).




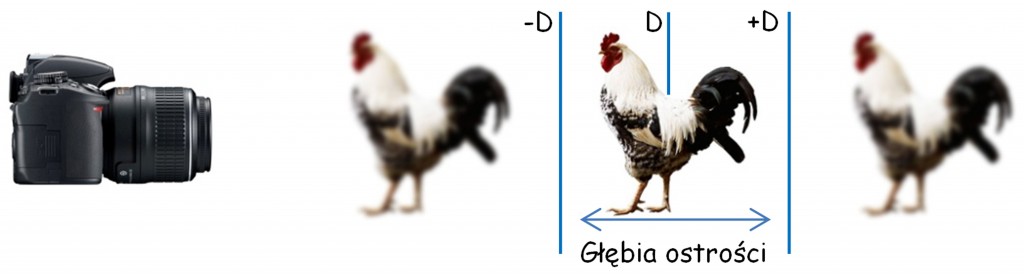
Efekty zaprezentowane na przedstawionych obrazach malarskich można również uzyskać metodą fotograficzną, poprzez manipulację tzw. głębią (tolerancją) ostrości (depth of field) (ryc. 64).

Głębia ostrości jest odległością między dwoma płaszczyznami widzenia znajdującymi się przed i za płaszczyzną pola widzenia D, na którą nastawiony jest układ optyczny aparatu fotograficznego lub oka (ryc. 65). Wszystkie obrazy rzutowane na płaszczyzny leżące między ‑D i +D są rejestrowane z niemal taką samą wyrazistością, jak obraz w płaszczyźnie D. Głębia ostrości nie zależy od akomodacji soczewki, ale od wielkości przesłony lub źrenicy. Im jest ona mniejsza tym głębia ostrości jest dłuższa, tzn. pozwala na wyraziste rejestrowanie większej liczby elementów leżących na wymiarze w głąb. Efekt ten jest znacznie łatwiej osiągalny i wykorzystywany w fotografii niż malarstwie.
Na koniec tego rozdziału chciałbym przywołać jeszcze jeden przykład malarza, którego surrealistyczne obrazy są wypełnione obiektami i przestrzeniami programowo przedstawionymi z różną wyrazistością (ryc. 66A). Chris Berens, współczesny malarz holenderski, zafascynowany twórczością Fransa Halsa, Jana Vermeera i Rembrandta Harmenszoona van Rijna, wypracował oryginalną technikę malarską. W odróżnieniu od swoich mistrzów, maluje tuszami kreślarskimi na papierze. Twierdzi, że ich własności są podobne do farb olejnych a jednocześnie pozwalają na uzyskiwanie zupełnie nowych efektów wizualnych. I rzeczywiście, oglądając jego obrazy można odnieść wrażenie, że coś niedobrego dzieje się z naszym wzrokiem. Wygląda to tak, jakby układ optyczny aparatu fotograficznego dysponował nie jedną, ale wieloma głębiami ostrości naraz.

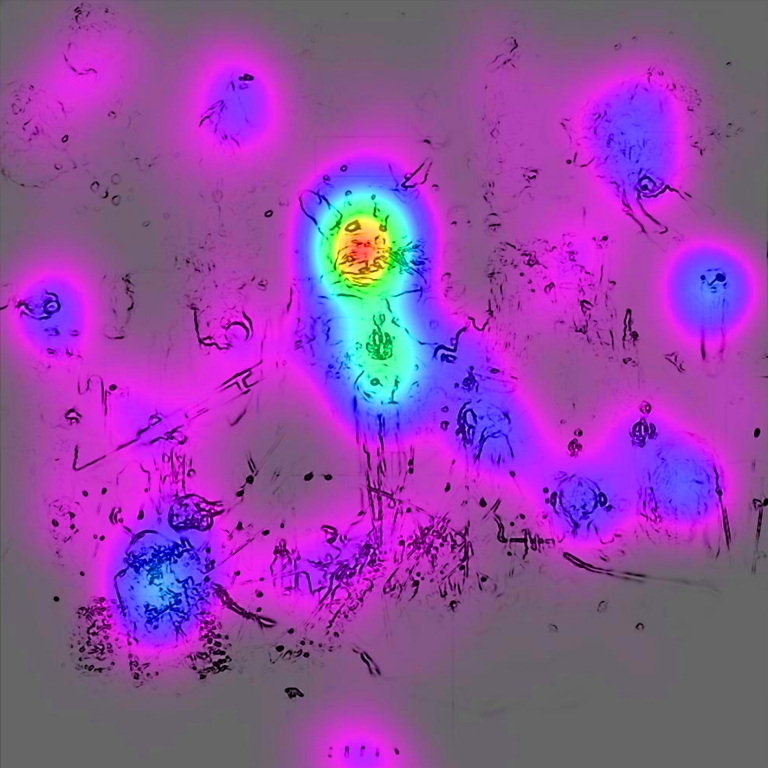
Obraz na ryc. 66B składa się z nałożonych na siebie dwóch obrazów. Na pierwszym z nich widać tylko czarne nieregularne kreseczki. Jest to wynik analizy graficznej, której celem było ustalenie krawędzi leżących na styku najbardziej kontrastującymi ze sobą miejsc na ryc. 66A, czyli – innymi słowy – tych, które charakteryzują się największą wyrazistością. W miejscach rozmytych lub niewyraźnych na obrazie nie ma żadnych śladów krawędzi.
Z kolei drugi obraz to mapa uwagi, czyli graficznie przedstawiony zapis ruchu gałek ocznych osób badanych. Barwne plamy wskazują na to, jak często badani spoglądali na różne części obrazu i jak długo zatrzymywali na nich wzrok. Barwa czerwona jest wskaźnikiem największej uwagi poświęcanej danemu fragmentowi obrazu, dalej żółta, zielona, jasnoniebieska, ciemnoniebieska i liliowa. Miejsca pozbawione barwy to te, na które osoby badane praktycznie nie zwracały uwagi. Obie techniki analizy graficznej obrazów i danych okoruchowych przedstawię dokładniej w następnym rozdziale.
Tutaj wystarczy tylko zauważyć, że istnieje ścisły związek między położeniem czarnych krawędzi a uwagą wzrokową poświęcaną danemu fragmentowi obrazu. Im wyrazistszy jest fragment tym chętniej mu się przyglądamy. Nie jest tak zawsze, ale z pewnością oglądanie każdej sceny wizualnej zaczynamy od tych miejsc, które pozwalają nam trafnie odczytać jej sens.
Podsumowując, w odniesieniu do wszystkich przedstawionych w tym rozdziale ilustracji można postawić pytanie, co sprawia, że niektóre ich części widzimy wyraźnie, a inne nie. Otóż utrata wyrazistości danego fragmentu obrazu lub zdjęcia wiąże się przede wszystkim ze zmniejszeniem się wyrazistości konturów malowanych lub fotografowanych obiektów i ich części. Innymi słowy, widzimy niewyraźnie ponieważ granice leżące na styku dwóch płaszczyzn różniących się jasnością przenikają się tonalnie, są rozmyte i nie pozwalają stwierdzić, gdzie się kończy jedna płaszczyzna a zaczyna druga. Widzenie konturów nie tylko pozwala nam na zobaczenie obiektu, ale również na oddzielenie go od innych obiektów obecnych w scenie wizualnej. Wyodrębnianie przedmiotów i ich części na podstawie kształtów wyznaczonych przez ich kontury jest podstawową funkcją wzroku (Marr, 1982; Ratliff, 1971). Właśnie tym zagadnieniem zajmę się w następnym rozdziale.
KONTURY WIDZIANYCH RZECZY
What happens at the borders is the only information you need to know: the interior is boring (Hubel, 1988)
Luminancja obrazu i kontury
Jeśli będziemy oglądali zdjęcie pod lupą, na ogół niewiele dostrzeżemy na nim linii konturowych, czyli kresek, które obwodząc leżące obok siebie fragmenty sceny wizualnej wyznaczają kształty znajdujących się w niej obiektów i ich części. Na ryc. 67 znajduje się powiększony 32 razy prawy kącik lewego oka, wyraźnie sfotografowanej dziewczyny z drugiego planu z poprzedniego rozdziału.Trudno tutaj doszukać się linii konturowych, a jednak patrząc na małe zdjęcie z lewej strony na ryc. 67 nie mamy wątpliwości, gdzie się znajdują wyraźnie zarysowane krawędzie oczu, ust lub włosów sfotografowanej dziewczyny, gdzie kończy się twarz a zaczyna tło. W znacznym stopniu decyduje o tym szerokość pasa tonalnego, który oddziela od siebie różnie oświetlone płaszczyzny malowanych lub fotografowanych obiektów i ich części oraz wielkość różnicy w zakresie jasności (luminancji) tych płaszczyzn. Im węższy jest pas tonalny rozdzielający dwie płaszczyzny oraz im większa jest różnica w zakresie jasności tych płaszczyzn tym łatwiej jest zidentyfikować ich granice, czyli kontur. Ale w jaki sposób system wzrokowy wyznacza tę granicę?

Według Davida Marra i Ellen C. Hildreth (1980), twórców jednego z matematycznych algorytmów, które symulują proces wykrywania krawędzi przez ludzkie oko, kontur rzeczy jest przejawem tzw. nieciągłości luminancji. Luminancja ciągła jest typowa dla płaszczyzn, których oświetlenie zmienia się stopniowo na stosunkowo dużej przestrzeni. Z kolei identyfikacja konturów jest tym bardziej możliwa im mniejsza jest przestrzeń, w której zmienia się oświetlenie powierzchni. Obecnie większość programów komputerowych, które służą do obróbki zdjęć ma wbudowane algorytmy detekcji krawędzi. Z punktu widzenia poruszanej tutaj problematyki detekcji konturów warto przyjrzeć się uważniej, w jaki sposób one działają.
Po wyizolowaniu kanału luminancji z barwnej reprodukcji obrazu Pierre-Auguste Renoira Madame Henriot, zobaczymy obraz w pełnej skali szarości, od bieli do czerni (ryc. 68A). Jeżeli teraz poddamy go analizie, której celem jest wyłonienie granic między płaszczyznami o największym zróżnicowaniu w zakresie jasności, wówczas zobaczymy zarys tych konturów twarzy i ubioru modelki, które w oryginalnym obrazie spostrzegamy jako najwyraźniejsze (ryc. 68B). Innymi słowy, wrażenie wyrazistości jakiegoś fragmentu obrazu mamy dlatego, że dostrzegamy znajdujące się na nim kontury. Usta, nos, zarys włosów, a zwłaszcza oczy Madame Henriot są wyraźnie podkreślone przez linie konturowe. Z kolei pozostałe części jej ciała i ubioru, które znajdują się poniżej twarzy widzimy nieostro ponieważ na podstawie nielicznych fragmentów linii konturowych powstałych w wyniku analizy krawędzi nie można wyodrębnić sensownych kształtów. Są jednak dwa wyjątki. Jeden znajduje się mniej więcej w środku dekoltu Madame i jak się domyślamy jest zarysem biżuterii. Drugi, nieco na lewo to podpis Renoira.
Według Davida Marra i Ellen C. Hildreth (1980), twórców jednego z matematycznych algorytmów, które symulują proces wykrywania krawędzi przez ludzkie oko, kontur rzeczy jest przejawem tzw. nieciągłości luminancji. Luminancja ciągła jest typowa dla płaszczyzn, których oświetlenie zmienia się stopniowo na stosunkowo dużej przestrzeni. Z kolei identyfikacja konturów jest tym bardziej możliwa im mniejsza jest przestrzeń, w której zmienia się oświetlenie powierzchni. Obecnie większość programów komputerowych, które służą do obróbki zdjęć ma wbudowane algorytmy detekcji krawędzi. Z punktu widzenia poruszanej tutaj problematyki detekcji konturów warto przyjrzeć się uważniej, w jaki sposób one działają.
Po wyizolowaniu kanału luminancji z barwnej reprodukcji obrazu Pierre-Auguste Renoira Madame Henriot, zobaczymy obraz w pełnej skali szarości, od bieli do czerni (ryc. 68A). Jeżeli teraz poddamy go analizie, której celem jest wyłonienie granic między płaszczyznami o największym zróżnicowaniu w zakresie jasności, wówczas zobaczymy zarys tych konturów twarzy i ubioru modelki, które w oryginalnym obrazie spostrzegamy jako najwyraźniejsze (ryc. 68B). Innymi słowy, wrażenie wyrazistości jakiegoś fragmentu obrazu mamy dlatego, że dostrzegamy znajdujące się na nim kontury. Usta, nos, zarys włosów, a zwłaszcza oczy Madame Henriot są wyraźnie podkreślone przez linie konturowe. Z kolei pozostałe części jej ciała i ubioru, które znajdują się poniżej twarzy widzimy nieostro ponieważ na podstawie nielicznych fragmentów linii konturowych powstałych w wyniku analizy krawędzi nie można wyodrębnić sensownych kształtów. Są jednak dwa wyjątki. Jeden znajduje się mniej więcej w środku dekoltu Madame i jak się domyślamy jest zarysem biżuterii. Drugi, nieco na lewo to podpis Renoira.
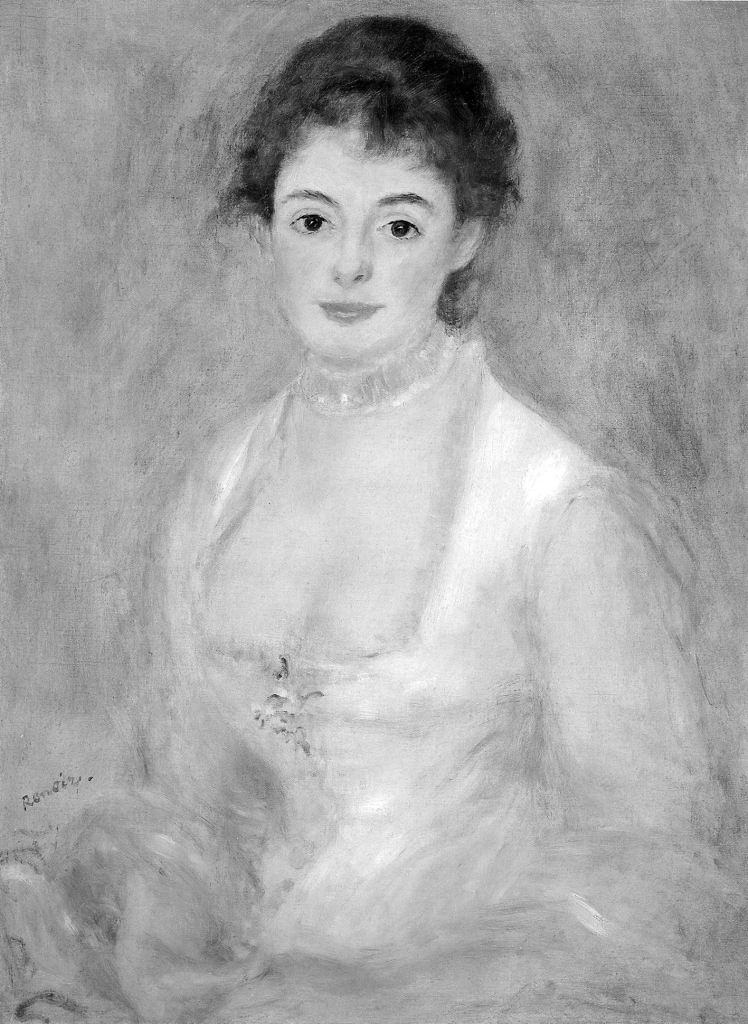


Porównując zapisy na ryc. 68 A i ryc. 69 łatwo zauważyć, że największe zainteresowanie osób badanych wzbudziła twarz oraz wspomniane dwa elementy, które wyróżniają się wyższą kontrastowością, czyli broszka w dekolcie sukni i podpis artysty. Warto dodać, że kolorowa mapa uwagi na ryc. 69 zawiera uśrednioną informację zarówno o liczbie punktów chwilowego zatrzymania wzroku na danym fragmencie obrazu, jak i o czasie tych fiksacji, dla wszystkich osób badanych razem.
Skoro miejsca o podwyższonej kontrastowości między leżącymi obok siebie płaszczyznami budzą znacznie większe zainteresowanie, niż inne miejsca na obrazie warto odpowiedzieć na pytanie, jaki neurofizjologiczny mechanizm odpowiada za ten efekt.
Pasma Ernsta Macha
W 1865 roku austriacki fizyk, filozof i psycholog, Ernst Mach, opublikował artykuł, w którym zaproponował koncepcję wyjaśniającą iluzję wzrokową polegającą na tym, że wzdłuż krawędzi leżących obok siebie płaszczyzn o różnej jasności można dostrzec dodatkowe cienkie, ale wyraźne pasy: jaśniejszy po stronie płaszczyzny jaśniejszej i ciemniejszy po stronie płaszczyzny ciemniejszej (ryc. 70 A).
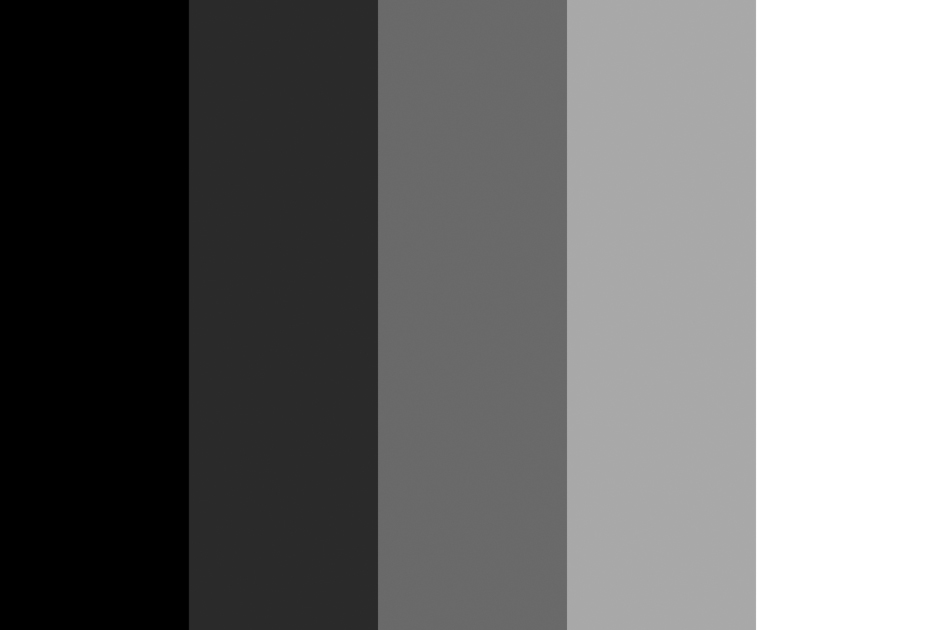

Przyglądając się chwilę jednolicie białej powierzchni prostokąta na ryc. 70 A zauważymy wąską, nieco jaśniejszą linię znajdującą się tuż przed krawędzią szarego prostokąta. Sprawia ona wrażenie, jakby była jeszcze bielsza niż biel całego prostokąta. W rzeczywistości nie ma tam żadnej jaśniejszej linii o czym łatwo można się przekonać poddając obraz analizie w programie do cyfrowej obróbki zdjęć. Podobny efekt występuje również po stronie czarnej powierzchni pierwszego prostokąta z lewej strony, choć nieco trudniej go dostrzec. Paradoksalnie, chociaż czerń płaszczyzny jest 100-procentowa, to pionowy pas wydaje się jeszcze „czarniejszy”. Żeby go dostrzec wystarczy nieco dłużej zatrzymać wzrok w miejscu, gdzie czarna płaszczyzna zaczyna się rozjaśniać a linia ujawni się w całej pełni. Opisana iluzja wzrokowa znana jest jako pasma (bands) lub wstęgi Macha. Dla porównania, gdy przejście między czernią a bielą jest ciągłe, jak na ryc. 70 B, wówczas nie można zobaczyć dodatkowych pasów oddzielających ciemne fragmenty płaszczyzny od jasnych.
Jednym z najwybitniejszych znawców koncepcji Ernsta Macha był psychofizjolog i biofizyk, Floyd Ratliff (1919–1999), który przez wiele lat prowadził badania nad iluzjami optycznymi, zwłaszcza związanymi z kontrastem koloru i jasności. Był także miłośnikiem twórczości Neoimpresjonistów między innymi dlatego, że fascynowało ich przedstawianie zjawiskowości świata, w taki sposób, w jaki jawi się on w subiektywnych aktach percepcji wzrokowej (Ratliff, 1992).
Analizując obraz Śniadanie. Jadalnia, namalowany przez Paula Signaca, Ratliff (1971) zauważył, że artysta – świadomie lub nieświadomie – namalował niektóre obiekty z uwzględnieniem iluzji pasów Macha (ryc. 71 A).



Czy zatem pasma Macha są tylko ciekawą iluzją optyczną?
Bynajmniej, okazuje się, że są one przejawem aktywności jednego z najważniejszych mechanizmów wzrokowych, którego celem jest identyfikacja konturów widzianych rzeczy poprzez podnoszenie kontrastu między leżącymi obok siebie powierzchniami o różnej jasności. Dzięki temu łatwiej jest wyróżnić części składowe w jednym przedmiocie i oddzielić jedne przedmioty od drugich. W szczególności mechanizm ten jest użyteczny w odniesieniu do tych fragmentów obrazu, które są rzutowane na peryferyczne części siatkówki, położone z dala od dołka centralnego.
A zatem raz jeszcze o budowie siatkówki: kanały ON i OFF
Żeby dobrze zrozumieć, jak działa mechanizm odpowiedzialny za wzmacnianie konturów oglądanych rzeczy, trzeba wejść w głąb siatkówki oka i przyjrzeć się jej skomplikowanej budowie (Dacey, 2000). Tak jak zostało to już wcześniej zasygnalizowane, składa się ona z pięciu warstw komórek: (1) światłoczułych pręcików i czopków, (2) komórek horyzontalnych, (3) komórek dwubiegunowych, (4) komórek amakrynowych i (5) komórek zwojowych (ryc. 73). Komórki światłoczułe, czyli fotoreceptory (warstwa 1) reagują na światło wpadające do oka. Komórki horyzontalne (warstwa 2) i amakrynowe (warstwa 4) łączą ze sobą fotoreceptory w tzw. pola recepcyjne i pośrednio lub bezpośrednio oddziałują na aktywność komórek dwubiegunowych (warstwa 3). Te z kolei przekazują sygnały zarówno z fotoreceptorów, jak i z pól recepcyjnych do komórek zwojowych (warstwa 5). W końcu komórki zwojowe, za pośrednictwem swoich długich aksonów przesyłają sygnały elektryczne w głąb mózgu.
Jak widać, kora mózgu jest informowana o rozkładzie światła w scenie wizualnej nie tylko na podstawie pobudzenia samych fotoreceptorów, ale również na podstawie aktywności połączonych z nimi komórek tworzących całą siatkówkę oka.
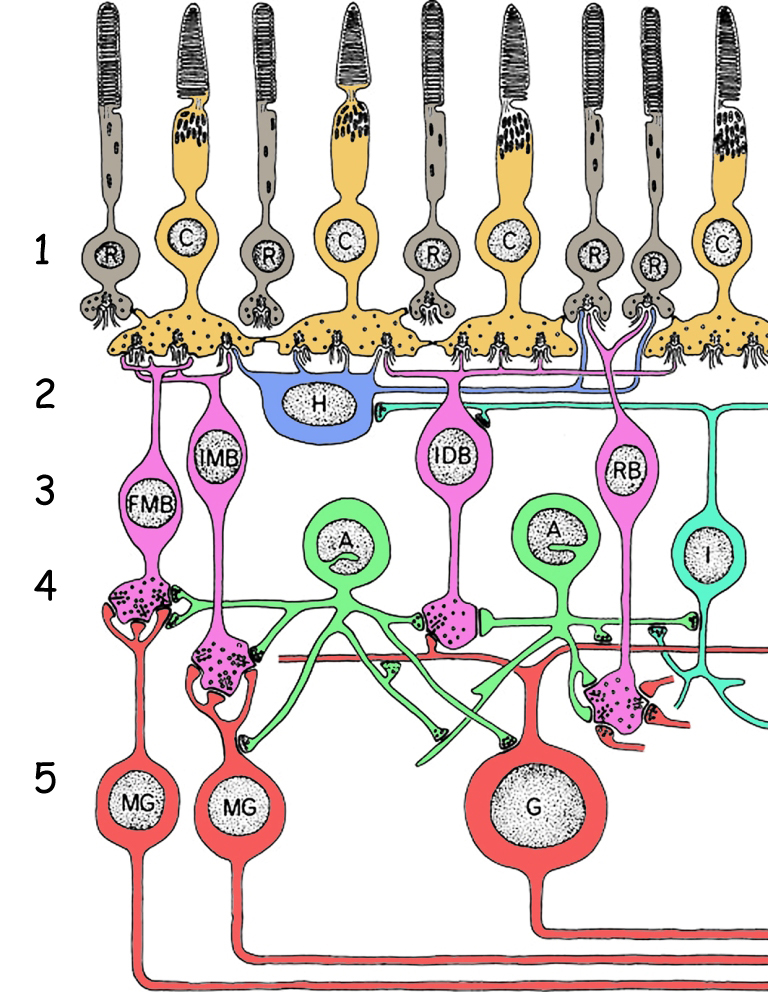
Komórki horyzontalne znajdują się tuż pod fotoreceptorami i łączą z nimi za pomocą sieci wypustek, zwanych dendrytami (ryc. 74). Połączone ze sobą fotoreceptory za pomocą jednej komórki horyzontalnej tworzą jej pole recepcyjne. Jedna taka komórka może połączyć ze sobą od kilku do kilkudziesięciu fotoreceptorów.
Z kolei każdy fotoreceptor może łączyć się nie tylko z jedną, ale co najmniej z dwoma komórkami horyzontalnymi. Taki układ połączeń między komórkami światłoczułymi i horyzontalnymi powoduje, że w siatkówce oka tworzą się duże zgrupowania powiązanych ze sobą fotoreceptorów. Każda taka grupa w połączeniu z pojedynczą komórką zwojową za pośrednictwem komórki dwubiegunowej tworzy pole recepcyjne tej komórki zwojowej.
Warto w tym miejscu uświadomić sobie, że dane o stanie pobudzenia poszczególnych fotoreceptorów w siatkówce oka – za wyjątkiem niewielkiego obszaru dołka centralnego – nie są przekazywane do kory mózgu. Przeciwnie, informacja na wyjściu z siatkówki jest co najmniej o dwa rzędy wielkości uboższa, niż na wejściu.
Część fotoreceptorów, które znajdują się w środkowej części pola recepcyjnego komórki zwojowej łączy się nie tylko z komórką horyzontalną, ale także bezpośrednio z komórką dwubiegunową. Jest to o tyle ważne, że informacja o stanie pobudzenia fotoreceptorów tworzących całe pole recepcyjne jest przekazywana do komórki zwojowej tylko za pośrednictwem komórek dwubiegunowych. Najlepiej widać tę sieć połączeń na przekroju pola recepcyjnego komórki zwojowej (ryc. 75). Fotoreceptory znajdujące się w środkowej części pola recepcyjnego komórki horyzontalnej są ze sobą dodatkowo połączone za pomocą dendrytów komórki dwubiegunowej.
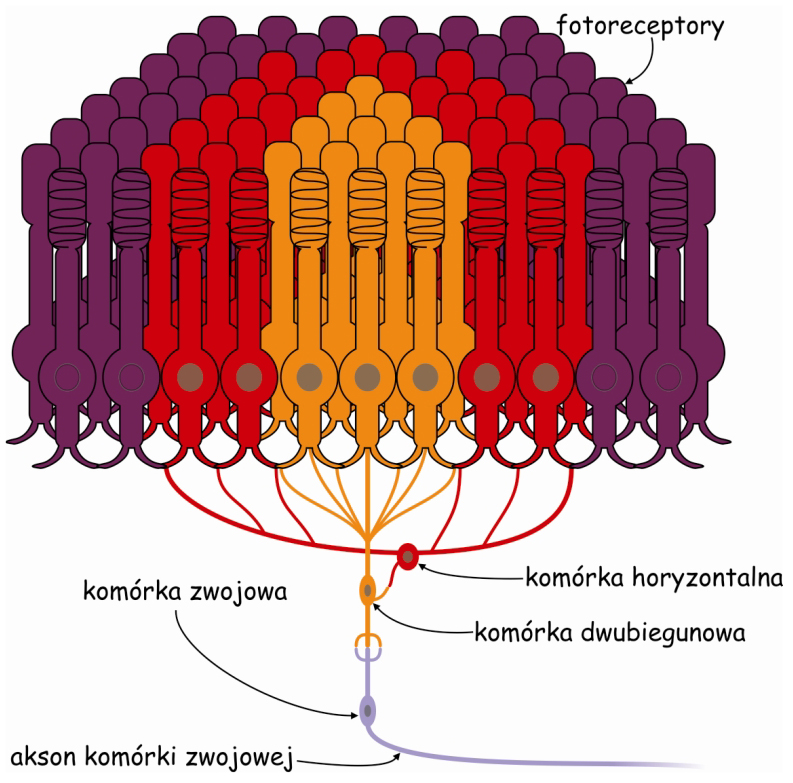
Podsumowując, pole recepcyjne komórki zwojowej utworzone przez sieć powiązanych ze sobą komórek horyzontalnych można podzielić na dwa obszary: centralny, w którym fotoreceptory są obsługiwane zarówno przez komórkę horyzontalną, jak i dwubiegunową oraz część peryferyczną, tzw. otoczkę, w której fotoreceptory są powiązane ze sobą tylko za pomocą komórki horyzontalnej. Informacja o jasności obrazu rzutowanego na pole recepcyjne jest uzależniona od tego ile fotoreceptorów zostało pobudzonych w części środkowej, a ile w peryferycznej i na dodatek, jak intensywnym światłem (Matthews, 2000). Zależy ona także od pewnej szczególnej własności komórek dwubiegunowych i zwojowych.
W siatkówce oka znajdują się bowiem dwa rodzaje komórek dwubiegunowych, tzw. włączeniowe (ON) i wyłączeniowe (OFF). Każdy rodzaj komórki dwubiegunowej jest związany z odpowiadającą jej komórką zwojową, także typu włączeniowego (ON) i wyłączeniowego (OFF). Połączenie: fotoreceptor (lub fotoreceptory) → komórka dwubiegunowa typu ON → komórka zwojowa typu ON nazywa się kanałem włączeniowym lub kanałem typu ON, natomiast połączenie: fotoreceptor (lub fotoreceptory) → komórka dwubiegunowa typu OFF → komórka zwojowa typu OFF nazywa się kanałem wyłączeniowym lub kanałem typu OFF (Longstaff, 2002).
Jeżeli światło o natężeniu większym niż średnie oświetlenie w danej okolicy siatkówki pada na fotoreceptor (lub fotoreceptory) połączone bezpośrednio z kanałem typu ON, czyli na środek pola recepcyjnego, wówczas komórka zwojowa zinterpretuje ten sygnał jako informację o pobudzeniu światłem tego fotoreceptora lub ich grupy. Reakcja komórki zwojowej będzie tym silniejsza, im więcej będzie pobudzonych fotoreceptorów znajdujących się w środku pola recepcyjnego i im mniej, leżących na jego peryferiach (ryc. 76, wiersz (a), kolumna: ON).
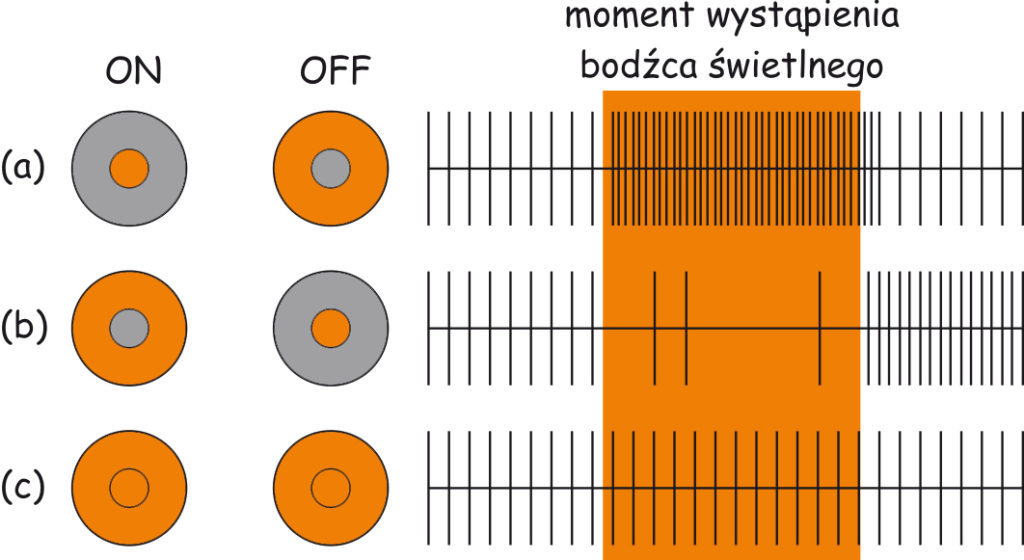
Bardzo podobnie zareaguje komórka zwojowa typu OFF wtedy, gdy na fotoreceptory umieszczone w centrum jej pola recepcyjnego padnie światło o mniejszej intensywności niż średnia intensywność oświetlenia w danej okolicy siatkówki. Wówczas komórka zwojowa przekaże do mózgu informację, że obraz rzutowany na tę okolicę siatkówki jest ciemny (ryc. 76 wiersz (a), kolumna: OFF).
Podsumowując, kanał typu ON przekazuje do mózgu informacje o położeniu jasnych miejsc w obrazie, a kanał typu OFF o położeniu ciemnych miejsc.
Jeżeli centralna część pola recepcyjnego komórki zwojowej typu OFF zostanie oświetlona, a jego otoczka pozostanie w cieniu, wówczas komórka zwojowa nie zareaguje. Podobnie będzie wówczas gdy nieoświetlona pozostanie centralna część pola recepcyjnego komórki zwojowej typu ON, a oświetlona będzie tylko otoczka (ryc. 76, wiersz (b), kolumny: ON i OFF). Chociaż w obu przypadkach komórki zwojowe nie zareagują, to dla mózgu to także jest wartościowa informacja, bowiem mówi ona coś na temat jasności różnych punktów obrazu rzutowanego na siatkówkę oka. Ponieważ liczba kanałów typu ON i OFF w siatkówce oka jest taka sama i są one mniej więcej równomiernie rozłożone obok siebie, dlatego mózg jest stale informowany o pobudzeniu fotoreceptorów, niezależnie od tego czy pada na nie intensywne światło czy też znajdują się w cieniu (Harris i Humphreys, 2002).
Nieco mniej „interesująca” dla mózgu jest sytuacja, gdy wszystkie fotoreceptory w polu recepcyjnym komórki zwojowej zarejestrują światło o podobnej intensywności, bez względu na jego jasność. Wówczas siła sygnału przenoszonego zarówno przez kanał typu ON, jak i OFF zostanie zrównoważona i komórka zwojowa zareaguje z umiarkowaną intensywnością, typową dla jej spontanicznej aktywności (ryc. 76, wiersz ©, kolumny: ON i OFF). Z punktu „widzenia” mózgu informacja o jednolitej jasności większego fragmentu obrazu oznacza tyle, że na dane pole recepcyjne jest rzutowany fragment powierzchni (a nie krawędzi) jakiegoś obiektu lub tła. Zdaniem Davida Hubela (1988), wnętrza płaszczyzn o jednolitej intensywności oświetlenia są dla mózgu po prostu nieciekawe.
Hamowanie oboczne, jako mechanizm zwiększania kontrastu
Czas powrócić do wyjaśnienia iluzorycznych pasm Macha. Zgodnie z jego hipotezą, jaśniejsze i ciemniejsze pasy widoczne na styku powierzchni o różnej jasności są związane z działaniem mechanizmu hamowania obocznego, polegającego na wzajemnym zmniejszaniu aktywności połączonych ze sobą komórek. Oczywiście Mach nie miał technicznych możliwości, żeby empirycznie zweryfikować tę hipotezę, ale jego intuicja była trafna.
Chociaż pole recepcyjne komórki zwojowej grupuje nawet po kilkaset fotoreceptorów to i tak jego powierzchnia nie przekracza 1 mm². Podobnie jak komórki horyzontalne tworzą sieci połączeń w ramach pola recepcyjnego pojedynczej komórki zwojowej, tak też pola recepcyjne różnych komórek zwojowych nie działają w odosobnieniu lecz są ze sobą powiązane. Szczególną rolę w łączeniu ze sobą pól recepcyjnych komórek zwojowych odgrywają komórki amakrynowe, a także inne interneurony (zob. warstwa 4 na ryc. 73). Obydwa rodzaje komórek wiążą się z komórkami dwubiegunowymi na wyjściu, tzn. tuż przed ich połączeniem z komórką zwojową. Dzięki takiemu miejscu połączenia z komórką dwubiegunową, komórki amakrynowe dysponują pełną „wiedzą” dotyczącą tego, jaki sygnał jest przekazywany z danego pola recepcyjnego do komórki zwojowej. Jest to też ostatni moment, żeby z tym sygnałem jeszcze coś zrobić. Można go bowiem albo wzmocnić, albo wyhamować.
Wiele komórek amakrynowych zajmuje się wyłącznie hamowaniem aktywności komórek dwubiegunowych. Nie jest to jednak takie całkiem bez sensu. Przeciwnie, stanowi podstawę detekcji konturów widzianych rzeczy. Najprościej mechanizm hamowania obocznego (lateral inhibition) – tak bowiem nazywa się aktywność komórek, które hamują niejako „z boku” poziom pobudzenia sąsiadujących ze sobą komórek dwubiegunowych – można wyjaśnić za pomocą prostego rysunku (ryc. 77).
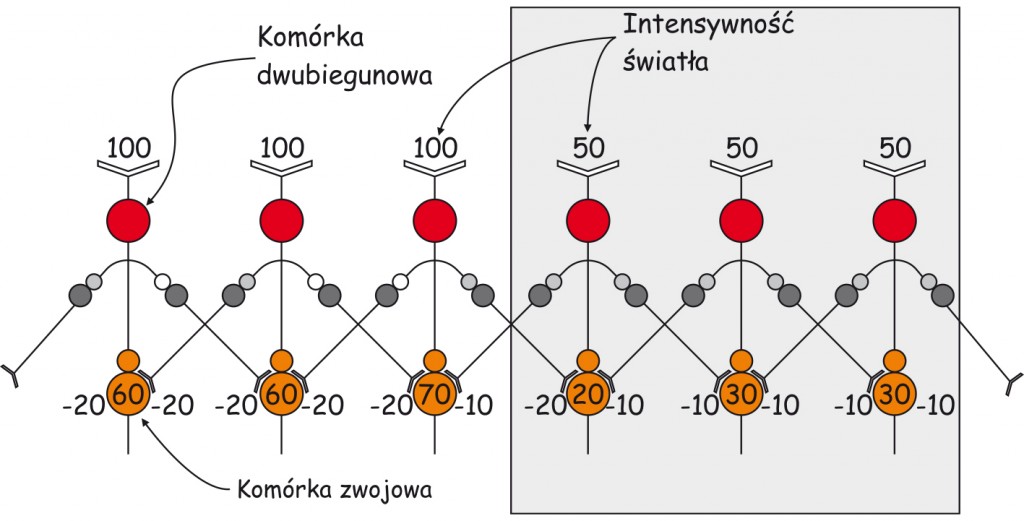
Schemat na ryc. 77 przedstawia hipotetyczne reakcje sześciu komórek zwojowych leżących na styku dwóch obszarów o różnej jasności. Komórki zwojowe są związane z sześcioma polami recepcyjnymi, ułożonymi prostopadle do krawędzi tych obszarów. Powierzchnia z lewej strony jest oświetlona (biała) a z prawej, znajduje się w cieniu (szara).
Dla zilustrowania działania mechanizmu hamowania obocznego przyjmujmy za Garym G. Matthewsem (2000) następujące założenia: (1) jasność płaszczyzny obrazu po prawej stronie jest o połowę mniejsza na umownej skali jasności światła, niż jasność płaszczyzny po lewej stronie, (2) hamujący wpływ komórek amakrynowych na sygnał przekazywany przez komórkę dwubiegunową do komórki zwojowej wynosi 20% intensywności światła w danym rejonie, tzn. w obszarze oświetlonym przez 100 jednostek komórka amakrynowa obniża poziom sygnału w komórce dwubiegunowej o 20 jednostek, a w obszarze oświetlonym przez 50 jednostek, sygnał jest obniżany o 10 jednostek oraz (3) każda komórka dwubiegunowa jest połączona za pomocą komórek amakrynowych z dwoma sąsiadującymi z nią komórkami dwubiegunowymi. Reszta to już prosta arytmetyka.
Dwie pierwsze komórki dwubiegunowe z lewej strony odbierają z fotoreceptorów sygnał o jasności pobudzającego je światła na poziomie 100 jednostek. Tuż przed połączeniem z komórką zwojową, sygnał przekazywany przez komórkę dwubiegunową jest hamowany, czyli obniżany przez dwie komórki amakrynowe o 40 jednostek (po 20 jednostek przez komórkę amakrynową z prawej i z lewej strony). W rezultacie obie komórki zwojowe otrzymują z komórek dwubiegunowych informację, że ich pola recepcyjne zarejestrowały światło o intensywności 60 jednostek (100 – 20 – 20 = 60). Podobne procesy zachodzą w dwóch komórkach dwubiegunowych z prawej strony wykresu. Ponieważ są one oświetlone mniej intensywnym światłem (50 jednostek), dlatego pobliskie komórki amakrynowe obniżają przekazywany przez nie sygnał tylko o 10 jednostek, każda (20% z 50 jednostek). W rezultacie komórki zwojowe otrzymują informację o jasności tych obszarów na poziomie 30 jednostek (50 – 10 – 10 = 30).
Najciekawsze są jednak wyniki odejmowania wartości reprezentujących wielkość sygnału przekazywanego przez komórki dwubiegunowe w okolicy krawędzi między obiema płaszczyznami o różnej intensywności oświetlenia. Chociaż komórka dwubiegunowa, która znajduje się po jasnej stronie płaszczyzny odbiera z fotoreceptorów informację o 100 jednostkach światła, to sumaryczny poziom jej hamowania przez dwie komórki amakrynowe wynosi nie 40, ale 30 jednostek. Bierze się to stąd, że najbliżej leżąca po stronie cienia komórka dwubiegunowa jest hamowana przez jedną komórkę amakrynową na poziomie 10, a nie 20 jednostek światła, bowiem pole recepcyjne z którym jest związana jest pobudzane światłem o intensywności 50 jednostek, a nie 100. W sumie do komórki zwojowej dociera informacja, że jej pole recepcyjne jest nasycone światłem o wartości 70 jednostek (100 – 20 – 10 = 70), a nie 60 jednostek, jak są informowane komórki zwojowe leżące bardziej na lewo od niej. I to jest właśnie owo jaśniejsze pasmo Macha po stronie intensywniej oświetlonej płaszczyzny obrazu.
Wystarczy tylko wyobrazić sobie kilkadziesiąt szeregów pól recepcyjnych, analogicznych jak na ryc. 77, które leżą prostopadle do granicy światła i z jednego jaśniejszego punktu mamy cały ich ciąg układający się wzdłuż jasnej krawędzi oświetlonej powierzchni.
Analogiczna jest kalkulacja w odniesieniu do pierwszego pola recepcyjnego leżącego po stronie cienia. Tu również komórka dwubiegunowa jest inaczej hamowana przez komórki amakrynowe leżące z jej prawej i z lewej strony. Skutkiem tego do komórki zwojowej dociera informacja o ciemniejszym pasie niż cała powierzchnia po prawej stronie obrazu (50 – 20 – 10 = 20). I to jest właśnie ciemniejsze pasmo Macha po stronie zacienionej płaszczyzny obrazu.
Spostrzeganie różnic w zakresie jasności w pobliżu krawędzi dwóch płaszczyzn o różnej luminancji ilustruje także wykres na ryc. 78. Po jaśniejszej stronie krawędzi widać wyraźne wzmocnienie subiektywnie spostrzeganej jasności powierzchni obrazu natomiast po ciemnej stronie krawędzi – równie wyraźne obniżenie jasności.
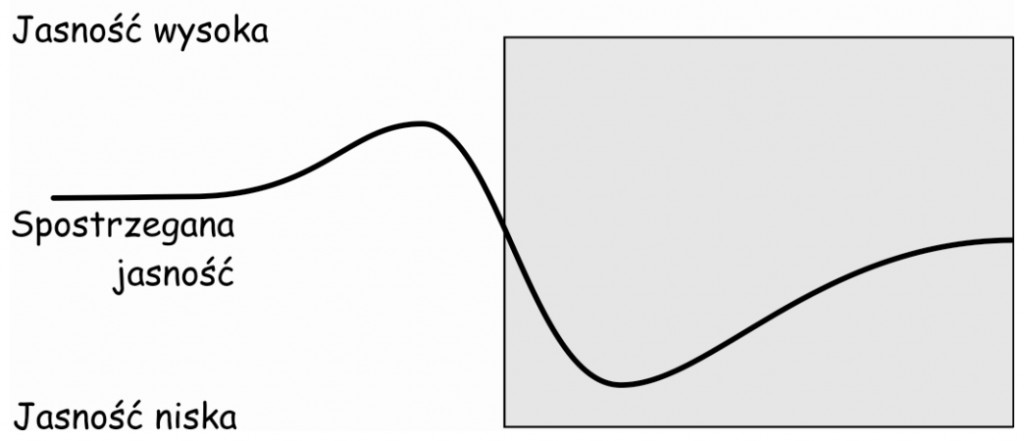
Oczywiście trzeba pamiętać o tym, że detekcja krawędzi między dwoma płaszczyznami o różnej jasności jest możliwa w wyniku pojawienia się w komórkach zwojowych w tym samym czasie podobnego sygnału z leżących obok siebie kilku lub kilkunastu pól recepcyjnych. Warto w tym miejscu dodać, że mechanizm czasowego grupowania podobnych sygnałów płynących z siatkówki do mózgu odgrywa bardzo ważną rolę również w wykrywaniu orientacji przestrzennej zidentyfikowanych krawędzi. Jak pamiętamy analizą tej cechy krawędzi oglądanych rzeczy zajmują się komórki tworzące kolumny w pierwszorzędowej korze wzrokowej w mózgu.
Na koniec warto raz jeszcze przypomnieć trzy sprawy.
Po pierwsze pasma Macha są iluzją, tzn. w rzeczywistości nie istnieją na obrazie rzutowanym na siatkówkę oka. Jeżeli były nanoszone na obraz (np. przez Paula Signaca, ryc. 72) to tylko dlatego, żeby podkreślić ich obecność w subiektywnym doświadczeniu widzenia.
Po drugie, pasma Macha są przejawem działania neurofizjologicznego mechanizmu służącego do podnoszenia kontrastu między leżącymi obok siebie powierzchniami o różnym nasyceniu światła.
I wreszcie po trzecie, stanowią one przeciwwagę dla nieostrego widzenia tych fragmentów obrazu, które są rzutowane zwłaszcza na peryferyczne części siatkówki, przez co zwiększają prawdopodobieństwo dostrzeżenia w tych miejscach konturów rzeczy w oglądanej scenie wizualnej.
Kontur – fundament i szkielet obrazu
Wykorzystanie konturu do obrazowania widzianych rzeczy jest najbardziej naturalną i najstarszą umiejętnością człowieka. Świadczą o tym zarówno ilustracje zwierząt i ludzi sprzed 20–30 tysięcy lat, znajdujące się na ścianach jaskiń w Altamirze, Lascaux lub Chauvet (ryc. 79), naskalne ryty w Gobustanie (ryc. 80A), jak również rysunki dzieci (ryc. 80B). Interesujące jest to, że chociaż widziane rzeczy najczęściej nie mają konturów, to usiłując przedstawić ich kształty na obrazie natychmiast kreślimy je za pomocą linii, które oznaczają krawędzie. Narysowana linia konturowa skontrastowana z tłem jednoznacznie odcina od siebie płaszczyzny, które należą do widzianych rzeczy i do tła, lub które wyznaczają istotne fragmenty tych rzeczy. Jednocześnie wykreślenie konturu zwalnia system wzrokowy z przeprowadzenia skomplikowanych operacji podbijania kontrastu przez mechanizm hamowania obocznego. Kontur jest bowiem rzutowanym na płaszczyznę obrazu wynikiem działania tego mechanizmu. Jest artystyczną stylizacją efektów hamowania obocznego. Rysując kontur na płaszczyźnie obrazu przedstawiamy świat zarejestrowany na wyjściu z siatkówki oka w kierunku mózgu.
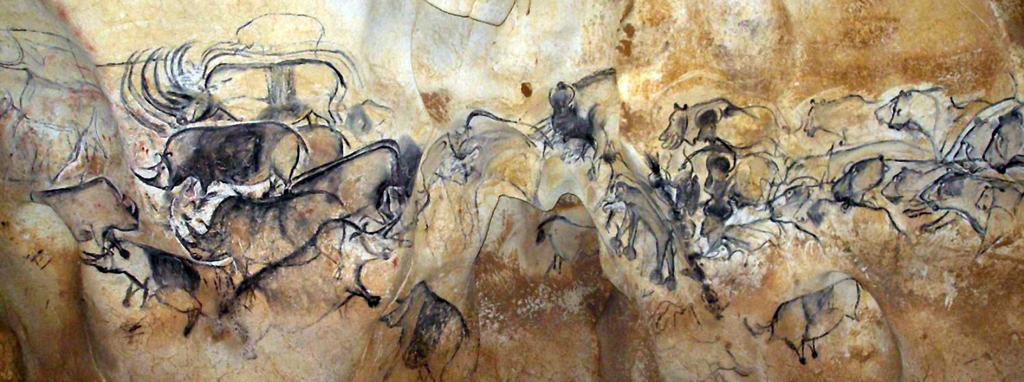
Warto w tym miejscu uświadomić sobie wagę odkrycia konturu, jako podstawowego narzędzia obrazowania. Zanim pojawiły się pierwsze rysunki lub ryty naskalne, nasi przodkowie wyłącznie rzeźbili obiekty przestrzenne. Najczęściej były to postaci kobiet lub zwierząt i instrumenty muzyczne.


Gdzieś ok. 30 000 lat przed nasza erą, a być może nawet jeszcze trochę wcześniej, człowiek odkrył, że obiekty trójwymiarowe, nawet jeśli nie posiadają konturu mogą być przedstawione na płaskiej powierzchni za pomocą nadpalonego kawałka drzewa lub błota nałożonego na palec. Uważam, że to odkrycie, będące wyrazem genialnej intuicji naszego praprzodka należy do kanonu kamieni milowych w historii cywilizacji człowieka, na równi z opanowaniem ognia i ukształtowaniem się zrębów języka werbalnego, opartego na wykorzystaniu znaków konwencjonalnych. Trudno bowiem wyobrazić sobie, na jakim etapie rozwoju cywilizacyjnego bylibyśmy obecnie, gdyby nasi przodkowie nie opanowali umiejętności przedstawiania świata na płaskim obrazie. Chyba wciąż jeszcze czekalibyśmy w swoich jaskiniach na genialnego Leonarda z Chauvet.
Między górnym paleolitem a współczesnością
Chociaż historia sztuki dostarcza wielu przykładów użycia linii konturowej jako środka wyrazu artystycznego, tym niemniej w malarstwie zachodnioeuropejskim przez wiele stuleci korzystano z niej niemal wyłącznie w celu wykonania szkicu, który później skrzętnie ukrywano pod warstwą farby. Dopiero rewolucja w sztuce z przełomu XIX i XX wieku sprawiła, że kontur przestał być tylko elementem rysunku pomocniczego, ale został włączony do arsenału tzw. nowoczesnych środków wyrazu. Artyści, tacy jak Paul Cezanne, Henri Matisse, Pablo Picasso czy Roy Lichtenstein, a także wielu, wielu innych współczesnych im twórców nie tylko nie ukrywali konturów malowanych rzeczy i ich części, ale przeciwnie, mocnymi pociągnięciami pędzla wyraźnie oddzielali je od siebie, uzyskując zupełnie nową jakość artystyczną (ryc. 81A, B, C i D).




Z daleka czy z bliska: Camille Pissarro vs Pieter Bruegel Starszy
Przedmioty oglądamy z różnych odległości. Z bliska dostrzegamy więcej ich szczegółów, z daleka – mniej lub w ogóle. Spadek wyrazistości szczegółów, jako pochodna odległości od oglądanego przedmiotu jest znacznie dotkliwiej odczuwany w odniesieniu do tych fragmentów obrazu, które są rzutowane na peryferyczne obszary siatkówki niż na dołek centralny. Ta niewątpliwa słabość systemu wzrokowego bynajmniej nie stanowi jednak zasadniczego ograniczenia dla twórców obrazów. Wręcz przeciwnie. Eksperymenty wizualne, w których artyści wykorzystują zmienną rozdzielczość oczu w celu komunikowania odbiorcom różnych treści, wcale nie są rzadkością. Świadczą o tym dzieła wielu artystów wywodzących się z różnych okresów i tradycji malarskich.
Na początek warto skonfrontować ze sobą dwa obrazy, które dzieli ponad 300 lat doświadczeń i refleksji nad sztuką wizualną. Pierwszy, bliższy naszym czasom, powstał w stylistyce impresjonistycznej, drugi należy do wczesnorenesansowej tradycji malarstwa flamandzkiego.
Obraz Pissarra (ryc. 82) jest przykładem malarstwa impresjonistycznego z typowym brakiem dbałości o kształty przedstawianych obiektów, ostro znaczonymi błyskami światła i grubo kładzioną farbą. Co przedstawia ten obraz?

W odniesieniu do dzieła Pissarra zachodzi interesujące zjawisko wizualne. Paradoksalnie bowiem, szczegóły przedstawionej na nim sceny wyłaniają się tym wyraźniej z im mniejszą rozdzielczością jest ona rejestrowana (oczywiście w granicach zdrowego rozsądku, ponieważ z odległości, np. 500 metrów prawdopodobnie z trudem dostrzegalibyśmy jakikolwiek obraz na ścianie). Rozwiązanie tego paradoksu tkwi nie w obrazie, ale w głowie obserwatora.
Zobaczmy, jak wygląda analizowany obraz z bliska. Na ryc. 83 A znajduje się jego dolny lewy fragment w pewnym zbliżeniu. Kiedy spojrzymy na ten fragment w kontekście całego obrazu (czyli z pewnego oddalenia), wówczas raczej nie mamy wątpliwości, że przedstawia on kawałek chodnika, tłum przechodniów, rozświetlone witryny sklepów i budkę telefoniczną z zapaloną wewnątrz żarówką.
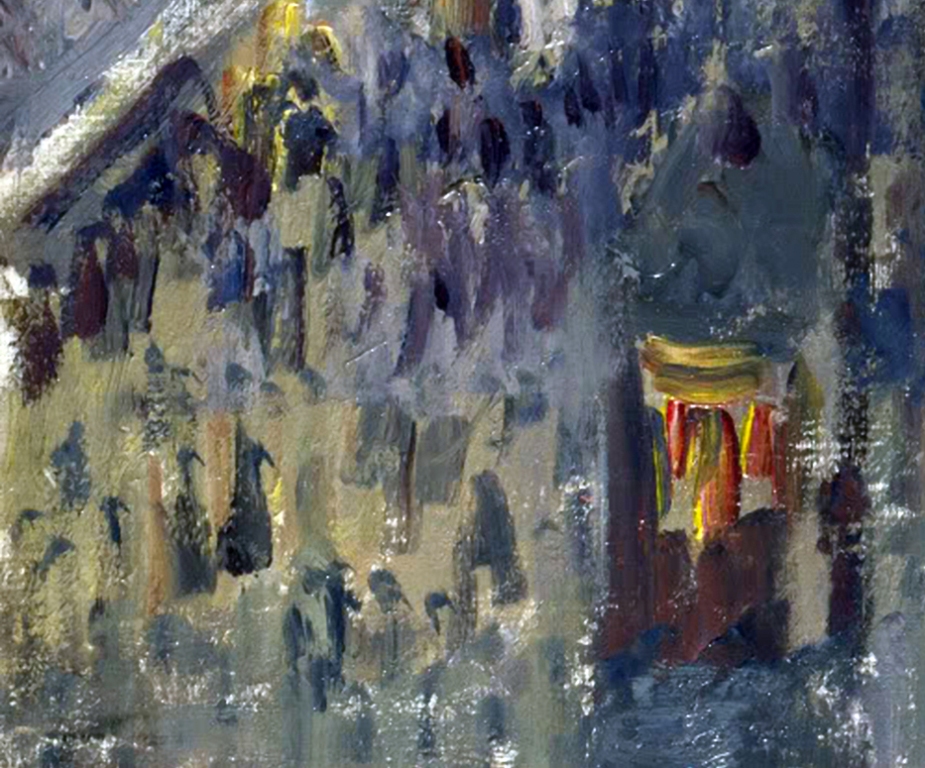
Po zbliżeniu i detekcji konturów na podstawie jasności przylegających do siebie płaszczyzn możemy stwierdzić, że kształt żadnego obiektu znajdującego się w tym fragmencie obrazu w niczym nie przypomina człowieka (ryc. 83 B). Dostrzeżenie tutaj ludzi, a także wszystkich innych wymienionych rzeczy bez odniesienia do całego obrazu jest po prostu niemożliwe. Widzimy tylko nieregularne plamy otoczone konturami, które bynajmniej nie pozwalają na skonstruowanie z nich jakieś sensownej sceny.

Chociaż można nie zgadzać się z założeniem Davida Marra (1982), że wszystkie dane umożliwiające rozpoznanie oglądanych rzeczy są dostępne z poziomu siatkówki, to niewątpliwie wiele z nich dostarcza użytecznych wskazówek pozwalających na interpretację tej sceny. Oglądanie obrazu Pissarra z większej odległości z pewnością nie poprawia ostrości widzenia szczegółów pojedynczych przedmiotów. Większy dystans pozwala natomiast dostrzec ogólne zarysy porządku rzeczy przedstawionych na obrazie. Poprzez zacieranie się szczegółów coraz bardziej zlewają się ze sobą większe partie namalowanego obrazu, które tworzą regularne struktury, wyznaczone przez iluzoryczne linie perspektywy (ryc. 84).

Odwrotną stroną Bulwaru Montmartre nocą Pissarra jest Doga krzyżowa namalowana przez Petera Bruegela Starszego. Na powierzchni mniejszej niż 1 m² malarz umieścił ponad 500 ludzkich postaci i bez mała setkę różnych zwierząt i przedmiotów (ryc. 85).



Od manieryzmu do mozaika.com
Na marginesie rozważań dotyczących wyrazistości obrazów oglądanych z różnych dystansów warto zwrócić uwagę jeszcze na kilka innych przykładów dzieł sztuki wizualnej. Łączy je to, że w odróżnieniu od dzieł Pissarra i Bruegla, przedstawiają one zasadniczo odmienne treści wtedy, gdy są oglądane z bliska lub z daleka. Ich fragmenty widziane z niewielkiej odległości są równie sensowne, jak postaci na obrazach Bruegla, ale wraz z oddalaniem się od obrazu rozmywają się i przekształcają w nowe treści, jak u Pissarra. Trochę w tym magii i iluzji, ale przede wszystkim są one przejawem eksperymentowania z możliwościami ludzkiego oka przez „nieświadomych neurobiologów” (por. Ramachandran i Hirstein, 1999; Zeki, 1999).
Za jednego z prekursorów surrealizmu uznaje się włoskiego manierystę, Giuseppe Arcimboldo’ego. Jego pasją było malowanie obrazów w taki sposób, że oglądane z bliska przedstawiały martwe natury złożone z warzyw, owoców, liści i kwiatów, a oglądane z pewnego dystansu przedstawiały portrety lub sceny rodzajowe. Arcimboldo przykładał równie wielką wagę do możliwe wiernego przedstawienia elementów składowych portretowanych postaci, jak i do uwypuklenia specyficznych rysów ich twarzy (ryc. 87 A i B).


Podobne eksperymenty nad zmiennorozdzielczym widzeniem obrazów prowadzi meksykański artysta Octavio Ocampo, surrealista i prekursor współczesnego malarstwa polimorficznego. Podobnie, jak w obrazach Arcimboldo’ego również u Ocampo można dostrzec dwie, a czasem nawet więcej warstw treściowych odkrywanych w zależności od odległości, z jakich są one oglądane. Prawie sześciometrowej długości fresk na ścianie Centrum Informacji Instytutu Technologicznego w Celaya w Meksyku daje ku temu szczególna okazję (ryc. 88). Niemal natychmiast dostrzegane z dystansu trzy twarze: prehistorycznego hominidy, człowieka homo sapiens i Alberta Einsteina, dopiero w bliższym kontakcie zamieniają się w grupę biegaczy, symbolizujących ewolucję człowieka.


Dane okulograficzne zebrane podczas wspomnianych już w tym rozdziale badań prowadzonych w naszym laboratorium (zob. opis do ryc. 69) dostarczają jeszcze jednej interesującej wskazówki odnośnie do percepcji twarzy ludzkiej, a w szczególności oczu. Reprodukcję fresku Ocampo pokazaliśmy naszym osobom badanym i zarejestrowaliśmy ruch ich gałek ocznych podczas oglądania. Okazało się, że rozpoznanie twarzy natychmiast kieruje uwagę osób badanych w stronę oczu, które stają się najważniejszymi elementami obrazu (ryc. 90; strzałki zwrócone w prawo).

O tym jak silny jest mechanizm detekcji oczu w scenie wizualnej świadczą jeszcze dwie niebieskawe plamy. Pierwsza, w lewym górnym rogu obrazu, w miejscu, gdzie znajduje się „Boskie oko” i druga w środkowej części obrazu (ryc. 90; strzałki zwrócone w lewo). Interesujące jest zawłaszcza zainteresowanie osób badanych kształtem w środkowej części obrazu, ponieważ faktycznie w tym miejscu nie ma oka, ale kształt zarysowującej się tam figury, w połączeniu z obrazem twarzy sugeruje taką możliwość.
Podobny pomysł kilka lat wcześniej zrealizował Salvador Dalí. Na ścianie swojego teatru-muzeum namalował on portret swojej nagiej żony – Gali, wyglądającej przez okno. To znakomite dzieło, w jednej z jego kilku wersji, łączy w sobie obie koncepcje korzystania z różnych zakresów rozdzielczości widzenia, w zależności od odległości, z jakiej jest oglądane (ryc. 91).






W 2008 roku na użytek pierwszej kampanii prezydenckiej Baraka Obamy, fotografka, Anne C. Savage przygotowała poster-mozaikę, złożony z 6000 kolorowych zdjęć twarzy (ryc. 94). W ten sposób chciała wyrazić swoje wrażenia związane z wiecami Obamy, w których uczestniczyły niezliczone tłumy słuchaczy. Zasada opracowania tego plakatu jest taka sama, jak za pomocą programu Mozaika. Jeśli zatem ktoś chce, może spróbować odnaleźć swoje zdjęcie wśród innych, np. w okolicach oczu Wodza (ryc. 95).


I wreszcie na koniec unikatowa mozaika zaprojektowana z okazji beatyfikacji papieża Jana Pawła II (ryc. 96). Jego portret beatyfikacyjny został wydrukowany na płótnie o wymiarach 55 x 26 m (1400 m²) i 1 maja 2011 roku zawieszony na fasadzie świątyni Opatrzności Bożej na warszawskim Wilanowie. Niezwykłe w tym wizerunku jest przede wszystkim to, że powstał on ze złożenia 105 tys. zdjęć przesłanych przez Polaków na tę okoliczność. Na stronie internetowej portretjp2.com.pl można z bliska obejrzeć tę mozaikę, a nawet odszukać miejsce swojego zdjęcia (o ile oczywiście zostało przekazane na ten cel i mamy naprawdę dużo szczęścia).

Kontury rzeczy i światłocień
Po wycieczce w mozaikowy świat obrazów oglądanych z bliska i z daleka czas powrócić do rozważań nad spostrzeganiem konturów rzeczy, a w szczególności przedmiotów trójwymiarowych. Wzrok jest nam dany przede wszystkim po to, aby rozpoznawać rzeczy na podstawie konturów i adekwatnie się wobec nich zachowywać. Sam ich kontur jednak nie wystarcza, ponieważ tam gdzie jest światło, tam jest też i cień, który także ma swój kontur. Dla systemu wzrokowego powstaje zatem problem zróżnicowania konturu rzeczy od konturu rzucanego przezeń cienia. Na drodze do rozpoznania przedmiotu wzrok musi sobie zatem poradzić również i z tą komplikacją.
Obiekty są widziane dzięki padającemu na nie światłu, które odbija się od nich i wpada do wnętrza oka, kładąc na jego tylnej ścianie ich wizerunek. To, jaki obraz pojawi się na ekranie siatkówki zależy nie tylko od intensywności światła, ale również od jego długości i kierunku. Światło może być bowiem rozproszone lub kierunkowe oraz może być skierowane na obiekt z różnych stron. Wszystkie te czynniki mają bezpośredni wpływ na kontrastowość sceny wizualnej, a w konsekwencji na wyrazistość konturów oglądanych przedmiotów i ich rozpoznanie.
Tych kilka oczywistych zdań uświadamia, z jakimi zadaniami musi uporać się najpierw oko, a po nim mózg, żeby trafnie rozpoznać scenę wizualną. Jedną z przeszkód stanowi cień rzucany przez przedmioty. Obiekt przedstawiony na ryc. 97A, to uszkodzona oś z kółkami samochodziku-zabawki.

Obiekt został oświetlony od tyłu, światłem kierunkowym o średniej intensywności. Ponieważ koła są czarne, podobnie, jak rzucany przez nie cień, dlatego na pierwszy rzut oka niełatwo jest rozpoznać co to za przedmiot. Podstawę tej trudności znakomicie ilustruje zarys konturów ustalony zgodnie z procedurą przyjętą we wszystkich tego typu analizach w niniejszej książce (ryc. 97B). Przedmiot i jego cień zlewają się w jeden, wyrazisty, aczkolwiek zupełnie nieznany kształt. Dopiero odrzucenie hipotezy, że cały kontur obrysowuje jeden przedmiot, ukierunkowuje uwagę na inne elementy tego obrazu (np. odblaski światła na kołach i łączącej je stalowej osi, których nie ma na cieniu). Stawianie i weryfikowanie hipotez percepcyjnych to jest już jednak zupełnie inna historia, która wybiega daleko wprzód naszych rozważań, w rejony wyższych procesów umysłowych.
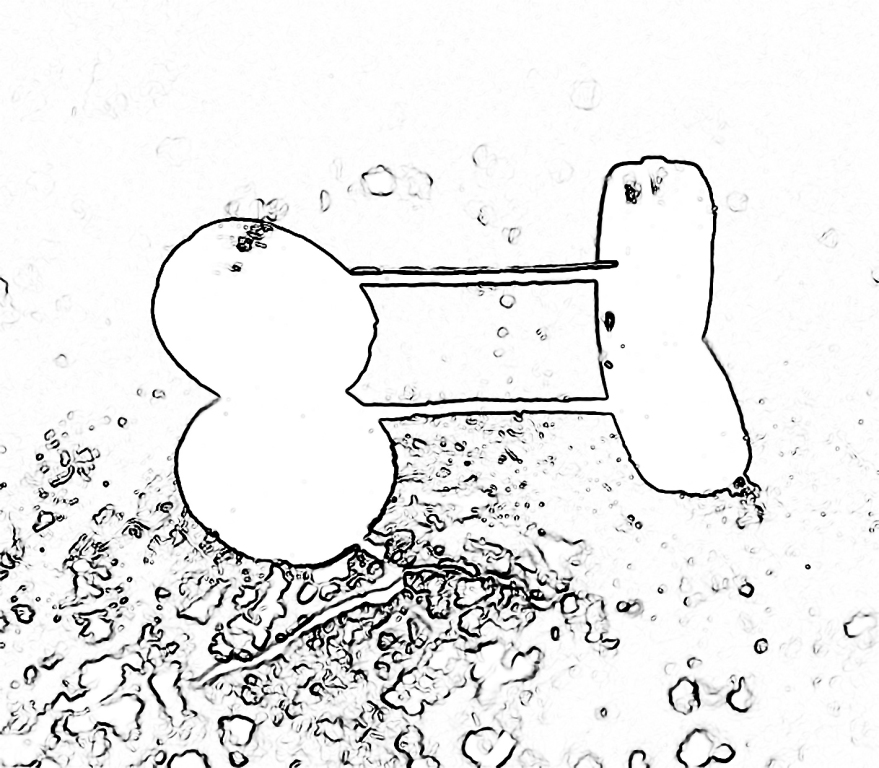


Dodam tylko, że jeżeli na zdjęcie z kubkiem na ryc. 98 spojrzelibyśmy nie przez pryzmat stabilnej fotografii, ale codziennego doświadczenia oglądania rzeczy w trzech wymiarach, a tym samym będąc w ruchu, wówczas problem konturów faktycznych i iluzorycznych rozwiązuje się niemal natychmiast. Wystarczy bowiem spojrzeć na ten obiekt z różnych punktów widzenia i szybko dostrzeżemy nowe jego kontury. Ruch obserwatora, a także ruch przedmiotu pełnią bowiem niezwykle ważną funkcję w trafnym rozpoznawaniu przedmiotów. Płaski obraz uniemożliwia przeprowadzenie tego rodzaju analizy i dlatego wymaga stosowania specjalnych sztuczek, których celem jest podkreślenie przestrzenności rzeczy.
Wykorzystanie cienia jest jednym z ważniejszych elementów języka obrazów. To właśnie nieodłączny cień rzucany przez brwi na oczy Don Vito Corleone (Marlon Brando) w filmie Ojciec chrzestny nadał jego twarzy wyraz tajemniczości, a na fotografii rowerzystów, pozwolił na odwrócenie naturalnego porządku rzeczy. W tym przypadku to cień rzuca obiekt (ryc. 99 A i B).


Iluzoryczne kontury
Problem oddzielenia krawędzi obiektu od krawędzi jego cienia jest, co najmniej równie skomplikowany, jak problem rozpoznania obiektu, którego obraz został pozbawiony jakiegoś fragmentu konturu, np. przez nadmierne oświetlenie (zob. prawa część kubka na ryc. 98), podobną jasność lub barwę w stosunku do innych jego części albo tła, na którym się znajduje. Wówczas obecności i położenia linii konturowych możemy się jedynie domyślać. Pomimo tego, że oko jest wyposażone w znakomite mechanizmy służące do wyodrębniania kształtów widzianych rzeczy, tym niemniej bez mechanizmów leżących na dalszych etapach szlaku wzrokowego, niemożliwe byłoby rozwiązanie tego problemu. Rüdiger von der Heydt, Esther Peterhans i Günter Baumgartner (1984), von der Heydt i Peterhans (1989) oraz Peterhans i Von der Heydt (1989) stwierdzili, że te same grupy komórek w korze V2 małp reagują podobnie na łatwo identyfikowalne, jak i na iluzoryczne kontury. Wyniki analogicznych badań nad ludźmi ujawniły, że spostrzeganie iluzorycznych konturów angażuje znacznie więcej obszarów mózgu, niż u małp (zob. Mendola, Dale, Fischl, Liu i in., 1999).
Ciekawą ilustrację iluzorycznych konturów można znaleźć, np. na plakatach Hansa Rudi’ego Erdta (por. Zelanski i Fisher, 2011; ryc. 100 A i B). Wiele elementów ubioru, części ciała lub twarzy osób przedstawionych na tych plakatach nie jest oddzielonych od innych części, a jednak nie mamy wątpliwości, co do ich kształtów. Ogromną rolę odgrywa tutaj także wcześniejsze doświadczenie wizualne, które podpowiada, gdzie powinny znajdować się linie konturowe.


Jeszcze bardziej wyrafinowane eksperymenty nad domyślnymi konturami w obrazie prowadził wspomniany już Octavio Ocampo (ryc. 101). W jego kompozycjach nie tylko brakuje wielu linii konturowych. Ta surrealistyczna wizja niemal swobodnie rozrzuconych na obrazie obiektów (kwiatów, motyli, ptaków i drzew) nie przeszkadza w dostrzeżeniu zarówno iluzorycznych konturów, jak i subtelnych, dziewczęcych rysów namalowanych twarzy.


Sfumato: od Leonarda da Vinci do Wojciecha Fangora
Studia nad konturami malowanych rzeczy doprowadziły Leonarda da Vinci do opracowania ulubionej przez niego techniki malarskiej, zwanej sfumato. Włoskie słowo „sfumato”, znaczy tyle, co zadymione, mgliste. Technika ta polega na zacieraniu granic między jasnymi i ciemnymi płaszczyznami obrazu. Z jednej strony powoduje to, że krawędzie przedmiotów są niewyraźne, a czasem wręcz niemożliwe do zidentyfikowania. W rezultacie system wzrokowy odpowiedzialny za detekcję konturów nie może oddzielić płaszczyzn należących do różnych obiektów od siebie. Ale z drugiej strony, niejednoznaczne granice między obiektem a jego tłem lub między jego częściami pozwalają na mniej skrępowaną interpretację tego, co widać.
W pewnym sensie brak jednoznacznych konturów ożywia obraz, czyni go bardziej tajemniczym i metaforycznym, a przez to bardziej interesującym. Między innymi, Ernst Gombrich (2005), Robert L. Solso (1996) i Mengfei Huang (2009) w ten sposób tłumaczą tajemniczość uśmiechu Mona Lisy (ryc. 102 A), której usta i oczy nie mają wyraźnych krawędzi, lecz zaledwie ich szczątki pozwalające na różne ich interpretacje. „Czasami zdaje się z nas drwić, innym razem wydaje się, że w jej uśmiechu dostrzegamy jakby smutek. Wszystko to brzmi dość tajemniczo i tak właśnie jest; takie bowiem wrażenie wywierają często wielkie dzieła sztuki”, pisze Gombrich o swoich wrażeniach z kontaktów z Lizą (2005, s. 300).


Znakomitym przykładem zastosowania techniki sfumato przez Leonardo da Vinci, który jeszcze lepiej ujawnia własności tej techniki, jest obraz Świętego Jana Chrzciciela, namalowany między 1513 a 1516 rokiem (ryc. 103 A). Leonardo był przywiązany do tego obrazu nie mniej, niż do umiłowanej Mona Lisy. Nigdy go nie sprzedał i chciał go mieć przy sobie na łożu śmierci.



Jak światło tworzy kontur u Georgesa Seurata
Georges Seurat również zabawiał się z linią konturową oglądanych rzeczy. Właściwie nie posługiwał się on konturem przedmiotu w znaczeniu linii oddzielającej go od tła lub innych obiektów w scenie. Poprzez subtelną zmianę barwy, nasycenia lub jasności, pracowicie stawianych obok siebie tysięcy kolorowych punktów, sygnalizował zaledwie obecność nowego przedmiotu. W ten sposób jasnobrązowe drzewo odcina się na tle niebieskiej wody Sekwany, zaś biel żagli, na tle jej piaszczystego brzegu (zob. ryc. 105 A).
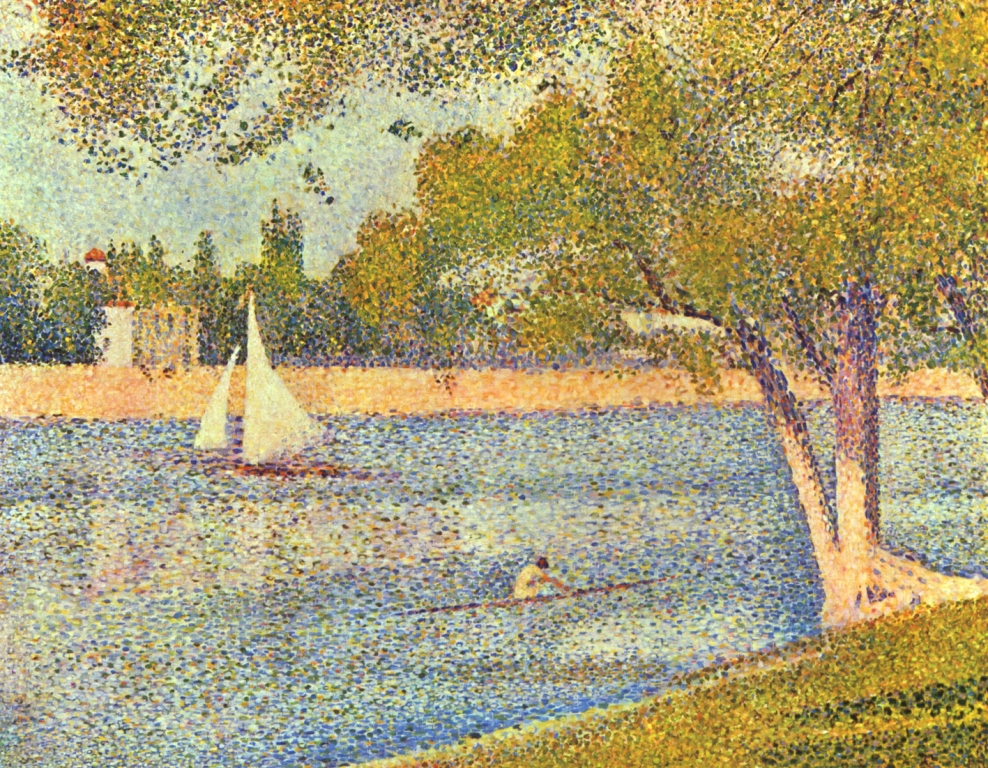

Efekt znikania kajakarki w wersji konturowej, chociaż jest ona znakomicie widoczna w wersji oryginalnej spowodował, że również i ten obraz znalazł się na liście bestsellerów pokazywanych trzydziestu ośmiu osobom badanym w przywoływanym już w tym rozdziale eksperymencie okulograficznym, jaki przeprowadziliśmy z Anną Szpak. Wyniki badania ujawniły interesującą prawidłowość. Okazało się bowiem, że kajakarka jest najchętniej oglądanym obiektem na obrazie (ryc. 106). Być może jest to tylko efekt zainteresowania jedyną w scenie postacią ludzką. Niewykluczone jednak, że oprócz detekcji konturów na podstawie kontrastów jasności, system wzrokowy jest jeszcze uzbrojony w inny mechanizm kodowania kształtów. Jest nim detektor barw, który w przypadku tego obrazu dostarcza nieco innych informacji niż analizator luminancji.
