Zjawiska umysłowe, wszelkie świadome i nieświadome zjawiska psychiczne, doznania wzrokowe czy słuchowe, doznania bólu, łaskotki, swędzenie, myśli, z pewnością całość naszego życia psychicznego, są efektem procesów zachodzących w naszym mózgu (Searle, 1995)
Ogólna budowa szlaku wzrokowego
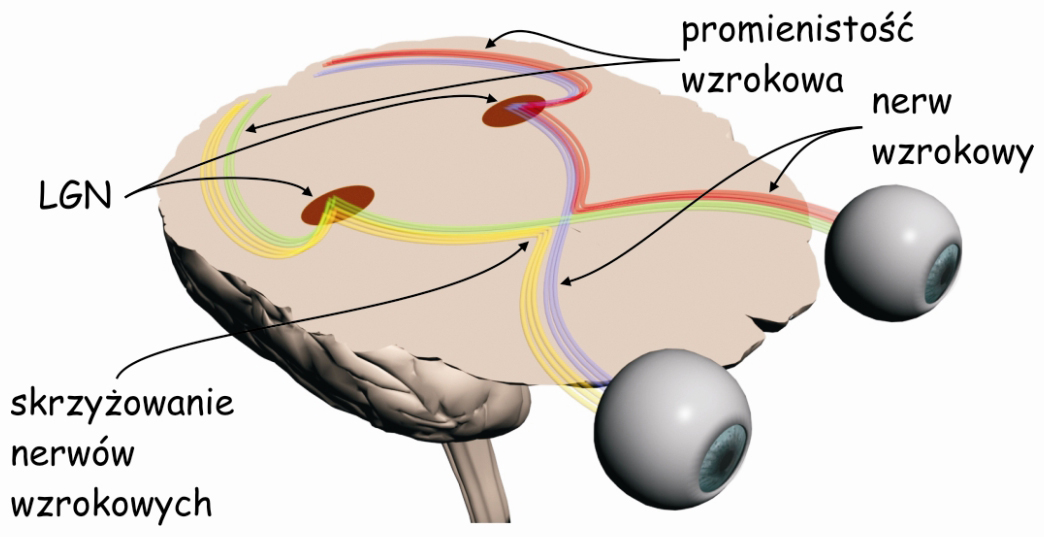
Mózgowe procesy leżące u podłoża doświadczenia widzenia są realizowane przez sieci neuronów, tworzących tzw. szlak wzrokowy. Jest to skomplikowana funkcjonalnie i anatomicznie struktura biologiczna, która w największym uproszczeniu składa się z trzech modułów. Pierwszy moduł, to oczy, a ściślej ich układy optyczne i siatkówki. Na drugi moduł składają się wszystkie struktury podkorowe, leżące między oczyma a korą mózgu, zwłaszcza w płacie potylicznym. I trzeci moduł, najbardziej skomplikowany, najmniej poznany a zarazem, jak się wydaje, najważniejszy dla widzenia to połączone ze sobą korowe obszary w różnych płatach mózgu (ryc. 4).
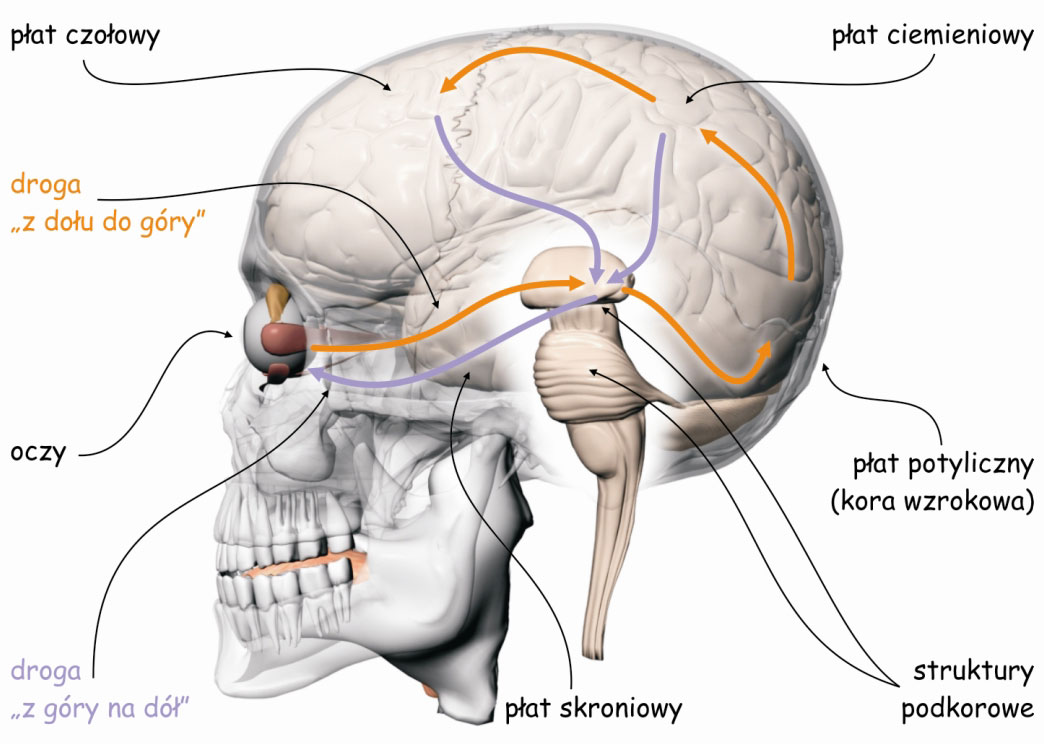
Podział szlaku wzrokowego na trzy części wynika z ujętych zgrubnie funkcji realizowanych przez struktury znajdujące się w ramach każdej z nich. Pierwszy moduł – oczy – jest odpowiedzialny za rejestrację światła i wstępną organizację danych sensorycznych. W drugim module, dane te są porządkowane i kategoryzowane. Obydwie te części tworzą tzw. wczesny etap szlaku wzrokowego. W trzecim module, najbardziej skomplikowanym funkcjonalnie i strukturalnie, dane sensoryczne są analizowane, a następnie integrowane i syntetyzowane. Współpracujące ze sobą struktury mózgu tworzące ten blok określa się jako wyższe lub późne etapy przetwarzania danych sensorycznych. Finalnym efektem pracy wszystkich tych modułów jest subiektywne doświadczenie widzenia.
Procesy oddolne i odgórne
Kierunek przepływu impulsów nerwowych na szlaku wzrokowym został zasygnalizowany na ryc. 4 za pomocą strzałek. Pomarańczowe strzałki wskazujące kierunek od oczu przez struktury podkorowe do kory mózgu oznaczają tzw. oddolne procesy przetwarzania danych sensorycznych lub inaczej – z dołu do góry (bottom-up). Zgodnie z tym kierunkiem przepływu danych sensorycznych, do płatów kory mózgu przekazywane są dane o rozkładzie światła docierającego do oczu obserwatora w takim zakresie, w jakim fotoreceptory je rejestrują, a połączone z nimi komórki nerwowe – przekażą wyżej. Oznacza to, że jeśli jakaś część sceny wizualnej jest, np. jaśniejsza niż inna, to intensywniej oświetlone receptory zareagują z większą siłą, proporcjonalnie do jej jasności i taką też informację przekażą do góry, w kierunku centrali, czyli różnych części kory mózgu.
Na pozór mogłoby się wydawać, że jeśli mówimy o percepcji wizualnej to oddolny kierunek przetwarzania danych sensorycznych jest jedynym możliwym sposobem poznawania świata za pomocą wzroku. Oczy, niczym aparat fotograficzny lub kamera wideo, rejestrują światło a mózg interpretuje jego rozkład, tworząc treść subiektywnego doświadczenia widzenia. W rezultacie obserwator ma poczucie, że wie, co znajduje się przed jego oczyma. Nic jednak bardziej mylnego. Codzienne doświadczenie podsuwa tysiące przykładów, które przeczą zasadzie mechanicznej rejestracji wideo, za pośrednictwem oczu-kamer lub oczu-aparatów fotograficznych. Nie znaczy to bynajmniej, że nie ma żadnych podobieństw między oczyma i mechanicznymi środkami rejestracji obrazu. Ale jedna różnica jest zasadnicza, aparaty nie mają nic do pomyślenia o świecie, który rejestrują. Co najwyżej mogą zasygnalizować, że w kadrze znajduje się, np. ludzka twarz. Nie mają jednak zielonego pojęcia do kogo ona należy, a także co łączy nas z jej właścicielem lub właścicielką.
Chociaż zakres obuocznego pola widzenia człowieka w płaszczyźnie horyzontalnej wynosi ok. 180° a w płaszczyźnie wertykalnej ok. 130°, to przecież nie jest tak, że z taką samą wyrazistością spostrzegamy wszystkie obiekty znajdujące się w tym obszarze. Ponadto, obecności niektórych rzeczy możemy w ogóle nie dostrzec, jeśli będą nietypowe lub nieistotne z punktu widzenia aktualnie wykonywanego zadania. Możemy, np. przeoczyć goryla przechadzającego się po boisku między koszykarzami, którzy podają do siebie piłkę wtedy, gdy skoncentrujemy się na zliczaniu tych podań (Simons i Chabis, 1999). Te własności systemu wzrokowego intuicyjnie wykorzystują mistrzowie kinematografii, z Alfredem Hitchcockiem na czele.
Możemy również błędnie domyślać się obecności jakiś przedmiotów w scenie wizualnej, tylko dlatego, że często widywaliśmy je w podobnych sytuacjach. Na przykład, możemy być pewni, że widzieliśmy włącznik światła na ścianie obok drzwi, choć faktycznie go tam nie było. Krótko mówiąc, mózg aktywnie przetwarza dane sensoryczne i ocenia ich przydatność ze względu na aktualnie wykonywane zadanie. Efektem tego procesu może być równie dobrze zignorowanie całkiem sporej grupy danych sensorycznych lub przeciwnie, wzbudzenie mięśni sterujących ruchami gałek ocznych w celu przeniesienia wzroku w inną część sceny, by sięgnąć po nowe dane. Wszystkie te procesy określa się ogólną nazwą procesów odgórnych lub inaczej – z góry na dół (top-down). Na ryc. 4 ten kierunek został zaznaczony strzałkami skierowanymi w dół w kolorze fioletowym.
Procesy odgórne zarządzają przetwarzaniem danych sensorycznych, w tym sensie, że filtrują je ze względu na rodzaj aktualnie wykonywanego zadania, intencję, potrzeby, nastawienie, przekonania, wiedzę lub oczekiwania obserwatora. Ich wyniki mają wpływ na ruch gałek ocznych, ukierunkowując osie widzenia na te elementy obrazu, które wymagają głębszej analizy. Wszechstronne badania eksperymentalne dotyczące roli nastawienia rozumianego, jako uogólniony stan gotowości do określonej formy reagowania, również w zakresie percepcji wizualnej, były prowadzone już w latach 60. XX wieku przez uczniów Dymitra Uznadzego, w ramach tzw. gruzińskiej szkoły psychologicznej (Bżaława, 1970; Prangiszwili, 1969; Uznadze, 1966).
Podsumowując, subiektywne doświadczenie widzenia jest wynikiem przetwarzania danych sensorycznych za pomocą procesów, które w porządku z dołu do góry organizują je i „przepychają” w kierunku wyższych pięter mózgu oraz procesów odgórnych, które selekcjonują i modyfikują te dane w zależności od aktualnych potrzeb, przekonań lub wiedzy obserwatora, a także odgórnie wpływają na kadrowanie następnych fragmentów sceny wizualnej.
Systemy analizy zawartości i kadrowania sceny wizualnej
Na ryc. 4 zaznaczono wiele różnych struktur mózgowych, które biorą udział w przetwarzaniu danych sensorycznych na wczesnych i późnych etapach szlaku wzrokowego. Struktury te są połączone ze sobą w nieprzypadkowy sposób, podobnie jak nieprzypadkowo połączone są ze sobą tranzystory na płytce drukowanej radioodbiornika. Poszczególne struktury mózgu (zwane jądrami, obszarami, płacikami, bruzdami, zakrętami itd.) są powiązane ze sobą za pomocą aksonów komórek nerwowych, czyli przewodów, po których z ciała jednej komórki biegną impulsy nerwowe do innej. W tym biologicznym układzie są takie struktury, które tylko przesyłają impulsy nerwowe do innych, ale są i takie, które zarówno wysyłają, jak i bezpośrednio lub pośrednio otrzymują od innych struktur informacje zwrotne. Co więcej, wewnątrz poszczególnych struktur mózgu również istnieją skomplikowane połączenia między tworzącymi je neuronami. Sieć wszystkich tych połączeń jest naprawdę skomplikowana. Jednak ze względu na funkcje, jakie pełnią różne sieci współpracujących ze sobą skupisk neuronów, biorących udział w przetwarzaniu danych wzrokowych, można wyróżnić dwa główne systemy. Są to: system kadrowania i system analizy zawartości sceny wizualnej.
Każde doświadczenie widzenia obejmuje tylko fragment większej całości. Widzimy, jakby w ramkach (kadrach). Nie możemy jednocześnie widzieć wszystkiego, co dzieje się z każdej strony głowy. Oglądanie czegokolwiek jest więc sekwencją kadrów, czyli widoków rzeczy, ograniczonych polem widzenia. Chcąc zobaczyć niewidoczne fragmenty sceny trzeba zmienić miejsce, z którego jest ona aktualnie oglądana lub pozostając w tym samym miejscu, zmienić położenie oczu lub głowy. Tę funkcję realizuje neuronalny system kadrowania sceny wizualnej, który kieruje ruchem gałek ocznych (a także ruchem głowy i całego ciała), fiksując osie widzenia na najbardziej interesujących częściach sceny wizualnej.
Jak nietrudno się domyślić różnica między oglądaniem dowolnej sceny wizualnej a oglądaniem obrazu polega na tym, że niezależnie od naturalnych ograniczeń zakresu pola widzenia, obraz ma również swoje granice. W obrazach muzealnych wyznaczają je ramy, odcinające zamalowaną powierzchnię dzieła od ściany. Ramami obrazu równie dobrze mogą być krawędzie ekranu kinowego, monitora telewizyjnego, komputera, obrys zdjęcia w gazecie, a także kurtyna teatralna, czy nawet bardziej umowne, a przecież również istniejące granice, w ramach których realizowane jest przedstawienie w przestrzeni miejskiej lub sali widowiskowej. Oglądanie obrazu wymaga ignorowania tego, co znajduje się poza jego granicami, zwłaszcza, gdy naturalny zakres pola widzenia obejmuje również tę przestrzeń. Barwa czy faktura ściany, na której wisi obraz nie należą do niego. Oglądanie obrazu domaga się zatem przede wszystkim respektowania wyznaczonych przezeń ograniczeń przestrzennych. Oglądać obraz i widzieć ten obraz w przestrzeni, np. muzeum, to jakościowo zupełnie różne dwa akty widzenia.
Drugą ważną cechą widzenia jest to, że kadr wyznaczony przez zakres pola widzenia lub ramy obrazu zawsze ma jakąś treść. Składają się nań rzeczy tworzące scenę, ich barwy, tło, kompozycja przestrzenna, ruch. Zrozumienie sceny wizualnej wymaga, aby jej cechy zostały przeanalizowane i skonfrontowane z posiadaną wiedzą i doświadczeniem wizualnym. Jest to realizowane przez neuronalny system analizy zawartości obrazu. Podstawową funkcją tego systemu jest doprowadzenie do subiektywnego doświadczenia widzenia chociaż niekoniecznie musi to być równoznaczne z rozumieniem tego, co jest właśnie widziane.
Wiele osób, które po raz pierwszy miało okazję zobaczyć ponad czterometrowej długości płótno Marka Rothko (ryc. 5) zadaje sobie pytanie: „O co tu chodzi?”, lub w wersji bardziej radykalnej: „Dlaczego to w ogóle jest traktowane jako dzieło sztuki?”. Brak wiedzy, często nie tylko wizualnej, może być poważnym ograniczeniem poziomu i głębokości rozumienia obrazu. Niezależnie jednak od tego czy trafnie rozumiane jest to, co widać na obrazie, bez wątpienia neuronalny system analizy zawartości sceny wizualnej zawsze dąży do nadania sensu widzianemu.

SYSTEM ANALIZY ZAWARTOŚCI OBRAZU
Cechy sceny wizualnej
Minimalnym warunkiem subiektywnego doświadczenia widzenia jest zarejestrowanie (spostrzeżenie) kształtu figury płaskiej (dwuwymiarowej) lub trójwymiarowego obiektu w przestrzeni znajdującej się w polu widzenia obserwatora. Nie rozstrzygam tutaj, czy najpierw widzimy rzeczy w dwóch czy w trzech wymiarach, ponieważ spór w tej sprawie wciąż nie jest rozstrzygnięty (np. Marr, 1982; Pizlo, 2008). Niezależnie jednak od tego, ów kształt, równie dobrze może być prosty, np. punkt lub kontur figury geometrycznej, jak i złożony, np. przejeżdżający samochód.
W naturalnych warunkach niezwykle rzadko mamy do czynienia z sytuacją, w której nie widzimy żadnego kształtu w polu widzenia, czyli czegoś, co granicząc z czymś innym, ujawnia swoją odrębność. Przebywanie w gęstej, nieprzeniknionej ciemności lub we mgle może prowadzić do wniosku, że nic nie widzimy. Owo „nic” oznacza to po prostu nieobecność jakiegokolwiek kształtu. Kształt jest podstawową cechą definicyjną każdej figury lub obiektu i ich części, a także cechą tła i przestrzeni, w jakiej się one znajdują, czyli cechą definicyjną każdej sceny wizualnej (Bagiński i Francuz, 2007; Francuz i Bagiński, 2007). Kształty widzianych rzeczy są najważniejszym kryterium ich kategoryzacji (Francuz, 1990) oraz stanowią podstawę wiedzy o wyglądach świata (Barsalou, 1999). Mogą wyznaczać granice rzeczy nazwanych, ale również nienazwanych.
O ile doświadczenie nieobecności jakichkolwiek kształtów w polu widzenia w naturalnych warunkach jest raczej dość rzadkie, o tyle sztuka współczesna dostarcza wielu modelowych przykładów obrazów, które stawiają odbiorcę wobec takiego doświadczenia.
W 1951 roku Robert Rauschenberg wystawił serię prowokacyjnych obrazów zatytułowanych Białe płótna, na których nie było po prostu nic namalowane (ryc. 6). Nawet granice obrazów były wyznaczone tylko przez cienie rzucane na ścianę przez blejtramy.

Drugą własnością każdej sceny wizualnej jest barwa (color), czyli konkretna jakość zmysłowa, która przysługuje figurze lub obiektowi wyznaczonemu przez jego kształt albo tłu. Barwę można opisać za pomocą trzech wymiarów: odcienia (hue), czyli inaczej tego, co na ogół rozumiemy pod pojęciem koloru czerwonego lub niebieskiego, jasności (lightness, brightness, value), zwanej także luminancją (luminance) lub walorem barwy (color value), charakteryzującym jej jasność na kontinuum między czernią a bielą oraz nasycenia (saturation, chroma), czyli tego, co odbieramy jako intensywność barwy. Czasem dodaje się jeszcze połysk (gloss), który jest pochodną charakteru powierzchni lub materiału pokrytego barwą. Spostrzegane różnice między płaszczyznami obrazu w zakresie jasności (luminancji) oraz odcienia są ważnymi wskazówkami dotyczącymi kształtów figur lub obiektów w scenie wizualnej. Oprócz wymienionych własności zmysłowych, barwom przypisywane są także różne wartości symboliczne, które mogą modyfikować znaczenia widzianych rzeczy (Gage, 2010; Popek, 2012; Zieliński, 2008).
Trzecią charakterystyką sceny wizualnej jest jej przestrzenna organizacja w dwóch lub w trzech wymiarach. Jeżeli konstytutywną cechą sceny jest spostrzeżenie w niej co najmniej jednego kształtu, który sugeruje obecność jakiejś rzeczy i oddziela ją od tła, to naturalnie ta rzecz musi znajdować się w określonym miejscu w przestrzeni. Odwołanie się do pojęcia miejsca rzeczy w scenie wizualnej uświadamia, że jest ona przedstawieniem oglądanym z jakiegoś punktu widzenia oraz, że jest ona ograniczona przez zakres pola widzenia obserwatora lub ramy obrazu.
Określenia miejsca rzeczy takie jak, np. „z prawej” lub „z lewej strony”, „wyżej” lub „niżej”, a także „bliżej” lub „dalej” zarówno od obserwatora, jak i od siebie nawzajem, zawsze są zrelatywizowane do punktu, z jakiego dany układ rzeczy jest widziany oraz do ram kadru. W takim samym stopniu dotyczy to całych scen wizualnych, jak i obrazów. Waga pozycji obserwatora w stosunku do widzianej przez niego sceny jest tak duża, że można nawet mówić o jego egocentrycznej pozycji w świecie oglądanych rzeczy (Goodale i Milner, 2008). Owo uprzywilejowanie bierze się z faktu, że w scenie wizualnej obserwator nie tylko widzi rzeczy, ale widzi również relacje między nimi. Spostrzegane w płaszczyźnie prostopadłej do osi widzenia relacje między rzeczami w scenie wizualnej i w obrazie są intuicyjnie ustalane w odniesieniu do stron ciała obserwatora i naturalnych ram, wyznaczonych przez zakres jego pola widzenia, a także przez ramy obrazu. Z kolei dostrzeżenie relacji między rzeczami wzdłuż linii równoległych do osi widzenia, czyli w głąb, nie jest już tak oczywiste i wymaga stosowania specjalnych procedur przetwarzania danych siatkówkowych i wiedzy o wskaźnikach głębi, w celu ich uchwycenia.
Czwartą i zarazem ostatnią cechą sceny wizualnej jest jej dynamika. Jest ona pochodną szybkości, zmienności, przyspieszenia i trajektorii ruchu, zarówno przedmiotów wewnątrz sceny wizualnej, jak i obserwatora. Ruch rzeczy znajdujących się w scenie wizualnej destabilizuje relacje przestrzenne między nimi. Dodatkowo obserwator może zmieniać swoje położenie względem danej sceny, zmieniając tym samym punkt jej widzenia. I nie chodzi tu tylko o przemieszczanie się obserwatora w przestrzeni (np. oglądanie wystaw sklepowych podczas spaceru), ale również o ruch jego oczu, który powoduje przenoszenie osi widzenia na różne fragmenty sceny. Krótko mówiąc, ruch przedmiotów w scenie wizualnej i ruch obserwatora podczas jej oglądania w najwyższym stopniu komplikują analizę subiektywnego doświadczenia widzenia. Zgodnie z wcześniejszą zapowiedzią, zagadnienie ruchu w obrazie, czyli wewnątrz kadru nie jest przedmiotem tej książki, natomiast ruch obserwatora, a w szczególności ruch jego gałek ocznych podczas oglądania obrazu, oczywiście – tak.
Wymienione cztery cechy sceny wizualnej: kształt, barwa, organizacja przestrzenna i dynamika, w gruncie rzeczy dają się sprowadzić do dwóch kategorii, chociaż nie są to kategorie rozłączne. Pierwszą, stanowią te własności sceny, które pozwalają obserwatorowi rozpoznać znajdujące się w niej przedmioty i orzec coś o ich formach i barwach. Jest to kategoria rzeczy. Percepcyjna analiza egzemplarzy tej kategorii na ogół nie zależy ani od tego, gdzie się one znajdują w stosunku do obserwatora, ani też od tego czy znajdują się one w ruchu czy też są ustabilizowane.
Z kolei organizacja przestrzenna i ruch obiektów w scenie wizualnej niemal zawsze odnoszą się do czegoś, o czym możemy powiedzieć, że ma jakiś kształt i barwę. Dostrzeżenie rzeczy, jako znajdującej się, np. z prawej strony sceny wizualnej wynika z jej położenia względem ciała obserwatora. Cechy te mają jednak nie tylko wyraźny związek z reprezentacją jego ciała, ale także z motoryką. Ogólnie rzecz biorąc organizacja przestrzenna i ruch obiektów w scenie wizualnej tworzą kategorię relacji.
Wymienione kategorie cech sceny wizualnej nie są rozłączne, ponieważ istnieją takie doświadczenia wizualne, które leżą na ich styku. Bardzo szybko poruszający się obiekt lub obserwator, poprzez całkowite zatarcie się linii konturowych, a nawet barw rzeczy znajdujących się w scenie wizualnej, mogą wywołać doświadczenie widzenia ruchu, który nie jest ruchem rzeczy o określonym kształcie. Ze względu na dużą szybkość, z jaką obserwator może się poruszać, jak również ze względu możliwości w zakresie kreowania obrazów za pośrednictwem mediów elektronicznych, liczba takich doświadczeń stale rośnie. Jak dotąd ewolucja nie wykształciła sprawnych mechanizmów radzenia sobie z takimi sytuacjami. Najlepszym tego przejawem są niewyjaśnione mechanizmy wielu iluzji optycznych w zakresie percepcji ruchu, wytworzone za pomocą cyfrowych technik wizualizacji (zob. np. strona Michaela Bacha, Optical Illusions & Visual Phenomena), a także złudzenia, jakim ulegają, np. piloci samolotów odrzutowych (Bednarek, 2011).
Widzenie, jako akt kreacji
Znakomite wprowadzenie do problematyki funkcjonowania neuronalnego systemu analizy zawartości sceny wizualnej zawiera artykuł Margaret Livingstone i Davida Hubela (laureata nagrody Nobla z dziedziny fizjologii i medycyny w roku 1981), opublikowany w 1988 roku w Science. Chociaż od jego wydania minęło już ćwierćwiecze, a wyniki badań w dziedzinie neuronauki poznawczej zweryfikowały większość formułowanych w nim hipotez, dotyczących przetwarzania danych wzrokowych, to nadal stanowi on aktualne i wiarygodne źródło informacji na temat struktury i funkcji poszczególnych elementów składowych szlaku wzrokowego.
Podstawowym ustaleniem dotyczącym funkcji szlaku wzrokowego w formowaniu się subiektywnego doświadczenia widzenia jest stwierdzenie, że poczynając od komórek nerwowych znajdujących się w siatkówkach obu oczu obserwatora, a kończąc na różnych strukturach jego mózgu, wymienione w poprzednim paragrafie cechy sceny wizualnej takie, jak: kształt, barwa, orientacja przestrzenna dwu- i trójwymiarowa oraz ruch, są analizowane przez cztery, częściowo niezależnie od siebie ścieżki (podsystemy) neuronalne. Stwierdzenie to ma fundamentalne znaczenie dla zrozumienia, w jaki sposób dochodzi do powstania doświadczenia widzenia sceny i znajdujących się w niej rzeczy. Otóż wynika z niego, że zarejestrowane przez fotoreceptory dane dotyczące rozkładu światła wpadającego w danym momencie do oka, na przeważającej części szlaku wzrokowego są przedmiotem częściowo niezależnych od siebie analiz, prowadzonych przez cztery wyspecjalizowane podsystemy nerwowe. Celem ich aktywności jest zinterpretowanie tych danych ze względu na cechy przedmiotów i/lub ich fragmentów, które aktualnie znajdują się w polu widzenia obserwatora w świetle posiadanych doświadczeń wizualnych.
Doświadczenie widzenia kompletnej sceny wizualnej nie jest efektem prostego odzwierciedlenia obrazu rzutowanego na siatkówkę oka (jak, np. w camera obscura), ale zachodzi w dwóch zasadniczych fazach: (1) dekompozycji, polegającej na analitycznym i względnie niezależnym od siebie badaniu wymienionych cech sceny wizualnej, po uprzednim wyabstrahowaniu ich z siatkówkowego obrazu oraz (2) kompozycji, czyli integrowaniu (syntetyzowaniu) wyników analiz przeprowadzonych w fazie pierwszej, z uwzględnieniem danych zapisanych już uprzednio w pamięci wizualnej.
Obecność obu wymienionych faz w każdym akcie widzenia prowadzi do wniosku, że wynik integracji sensorycznej zawsze (w mniejszym lub większym stopniu) odbiega od zarejestrowanych danych źródłowych. Oznacza to, że treści doświadczenia wizualnego są stale raczej wytwarzane przez system wzrokowy, a nie – jak mogłoby się wydawać – odtwarzane z obrazów siatkówkowych. W tym sensie widzenie jest aktem kreacji, podczas którego dochodzi do skonstruowania obrazu rzeczywistości zarejestrowanej przez system fotoreceptorów, znajdujących się w siatkówkach oczu obserwatora.
Wczesny system analizy zawartości sceny wizualnej
Fotoreceptory umieszczone w siatkówce wewnątrz oka rejestrują rozkład wpadającego doń światła. Jest to pierwszy etap procedury analizy zawartości sceny wizualnej. Najważniejsze struktury neuronalne, które biorą udział w rejestracji i organizacji danych sensorycznych na wczesnych etapach szlaku wzrokowego zostały przedstawione na ryc. 7.
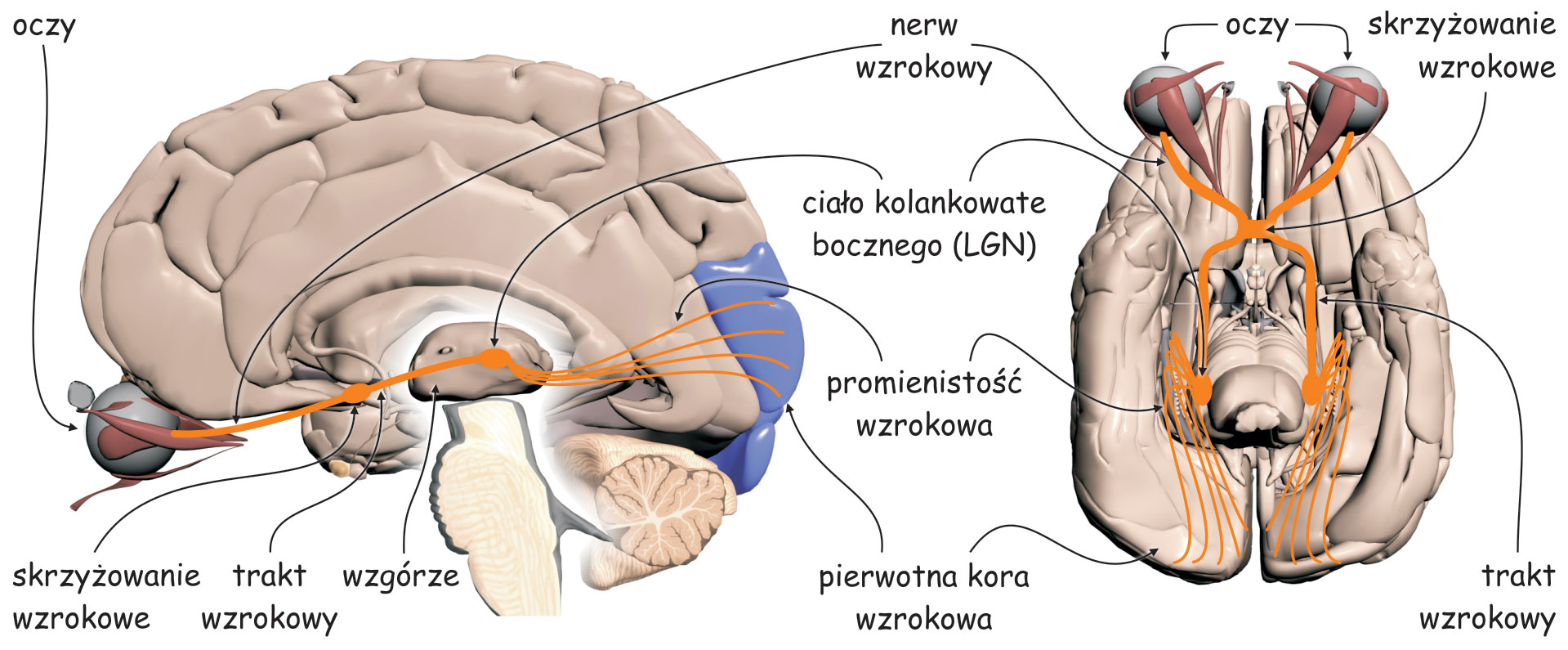
Wczesny system analizy zawartości sceny wizualnej zasadniczo składa się z dwóch odrębnych struktur: oka (eye), a w szczególności układu optycznego, czyli soczewki, która znajduje się w przedniej jego części i siatkówki (retina), zlokalizowanej na tylnej ścianie, wewnątrz oka oraz ciała kolankowatego bocznego (lateral geniculate nucleus; LGN), leżącego mniej więcej w połowie drogi między oczyma a korą mózgu, w miejscu zwanym wzgórzem (thalamus).
W siatkówkach oczu znajdują się między innymi tzw. komórki zwojowe (ganglion cells). Ich aksony, czyli wypustki, po których jak po drucie telefonicznym biegną sygnały nerwowe w głąb mózgu, tworzą nerw wzrokowy (optic nerve). Na odcinku między oczyma a LGN, znajduje się skrzyżowanie wzrokowe (optic chiasm), miejsce, w którym wiązka aksonów odprowadzających sygnały nerwowe z każdego oka rozdziela się na dwie części. Połowa aksonów z lewego oka łączy się z połową aksonów z prawego oka (podobnie druga połowa aksonów komórek zwojowych wychodząca z jednego i z drugiego oka) i dalej biegną razem do prawej i do lewej półkuli mózgu. Odcinek między skrzyżowaniem wzrokowym a LGN nazywa się traktem wzrokowym (optic tract).
Z LGN impulsy nerwowe są przekazywane do tzw. pierwotnej kory wzrokowej (primary visual cortex lub striate cortex) w płacie potylicznym mózgu za pośrednictwem aksonów dużej grupy komórek, których ciała znajdują się w LGN. Ten odcinek nazywa się promienistością wzrokową (optic radiation) i z grubsza domyka on pierwszy etap przesyłania i przetwarzania danych sensorycznych na szlaku wzrokowym.
Oko – metafora aparatu fotograficznego
Pod wieloma względami budowa oka i aparatu fotograficznego są do siebie podobne. Zanim wskażę na zasadnicze różnice między nimi, warto przyjrzeć się tej analogii (ryc. 8).
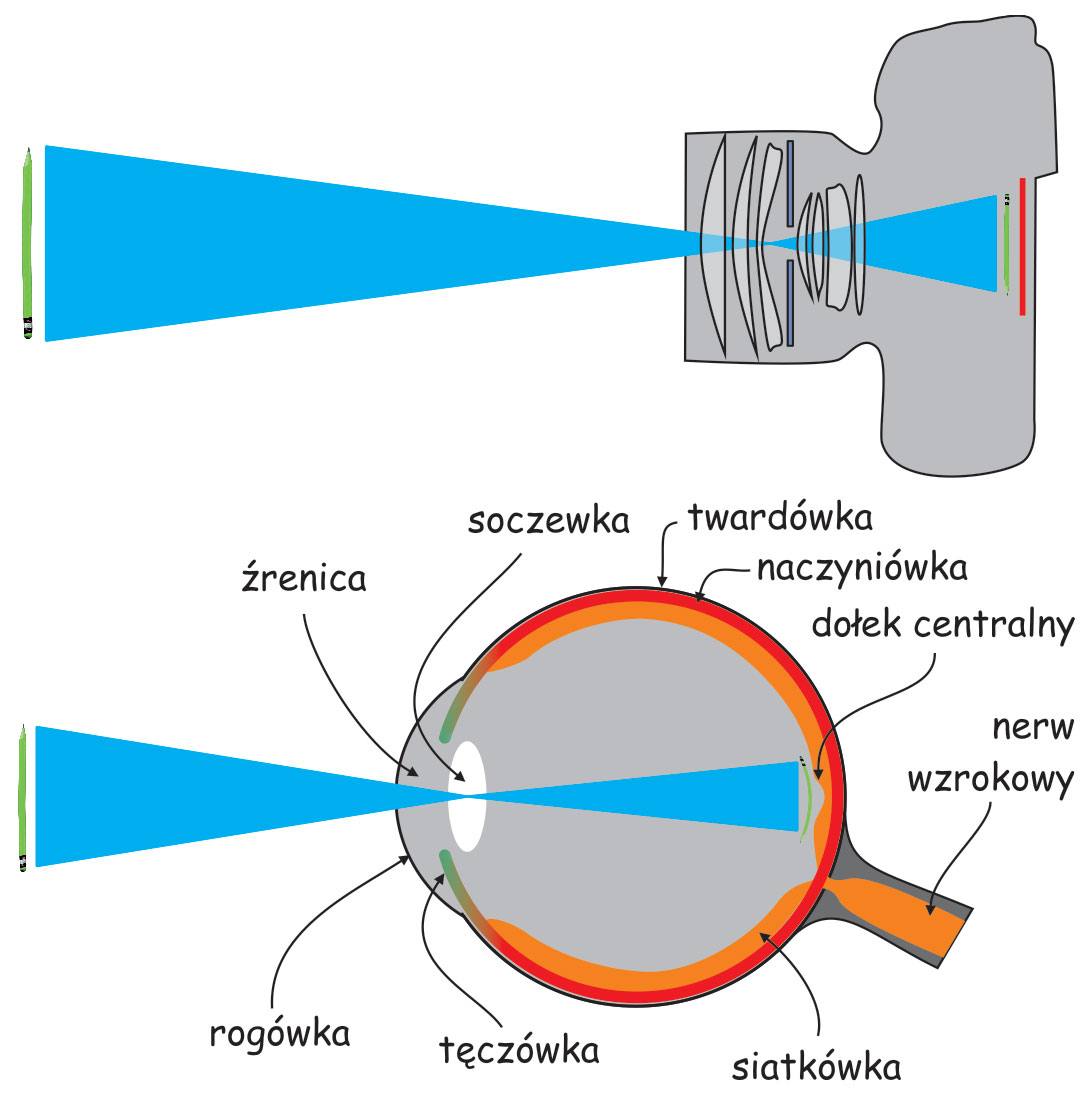
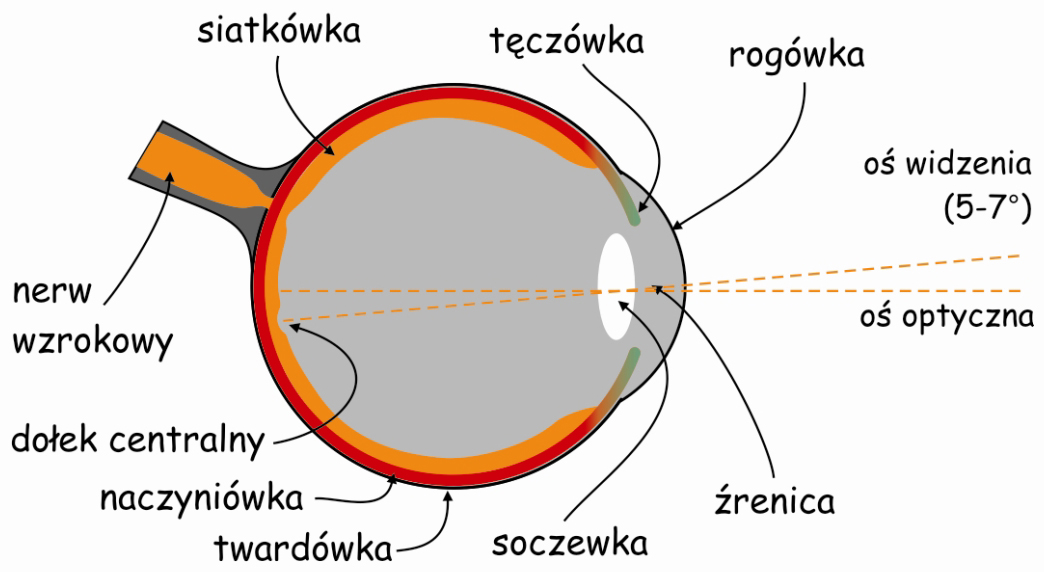
Szlak wzrokowy rozpoczyna się w oku. Podobnie, jak aparat fotograficzny, oko składa się ze szczelnej i sztywnej obudowy. W oku nazywa się ją twardówką (sclera). Jej funkcją jest ochrona gałki ocznej przed uszkodzeniami mechanicznymi oraz stabilizacja jej kształtu.
W przedniej części oka znajduje się układ optyczny, czyli biologiczny odpowiednik obiektywu w aparacie fotograficznym. Najbardziej na zewnątrz wysunięta jest przezroczysta rogówka (cornea), która podobnie, jak twardówka zabezpiecza oko przed uszkodzeniem mechanicznym. Pełni ona również funkcję swego rodzaju filtra ochronnego i soczewki o stałej ogniskowej. Tuż za rogówką znajduje się otwór obiektywu, zwany źrenicą (pupil), którego średnica jest regulowana za pomocą przysłony, czyli tęczówki (iris).
Nawiasem mówiąc, w odróżnieniu od przysłony w aparacie fotograficznym, tęczówka jest barwna: najczęściej brązowa (w różnych odcieniach), ale może być również szara, zielona lub niebieska (ryc. 8.1).
Za tęczówką leży zmiennoogniskowa soczewka (lens), jeden z najbardziej zdumiewających narządów w naszym ciele. Ralf Dahm (2007) nazywa ją „kryształem biologicznym”. Soczewka oka ma dwie własności, które odróżniają ją od układu optycznego w aparacie fotograficznym. Po pierwsze, ma znakomitą przezroczystość, dzięki czemu przepuszcza do wnętrza oka niemal 100% światła, oczywiście pod warunkiem, że jest w pełni sprawna. Soczewka oka jest również zmiennoogniskowa, co pozwala obserwatorowi na wyraźne oglądanie rzeczy znajdujących się w różnej odległości od niego. Mechanizm zmiany ogniskowej soczewki oka w niczym nie przypomina zmiany ogniskowej w obiektywie fotograficznym.
Utrzymywanie ostrości widzenia obiektów znajdujących się w różnej odległości od układu optycznego oka jest zagwarantowane przez możliwość zmiany kształtu soczewki oka. Im obiekt jest bliżej oczu obserwatora tym grubsza staje się soczewka, a im dalej, tym jest cieńsza (ryc. 9).
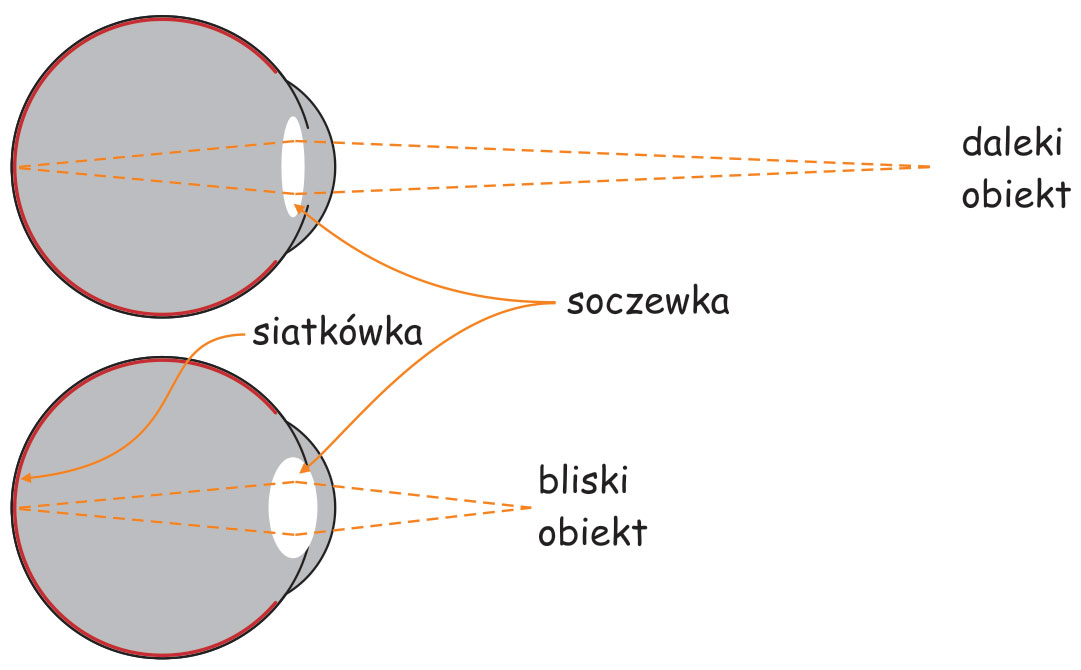
Soczewka jest przyczepiona do wewnętrznej części gałki ocznej za pomocą mięśni rzęskowych (ciliary muscles), które kurcząc się rozciągają soczewkę, przez co staje się ona cieńsza, a rozluźniając – sprawiają, że soczewka pęcznieje w środkowej części. Efekt skupiania promieni świetlnych na tylnej ścianie gałki ocznej, czyli ogniskowania, jest związany ze zmianą kąta załamywania się promieni świetlnych na soczewce o różnej grubości. Grubsza soczewka załamuje promienie świetlne pod większym kątem niż cieńsza. Zjawisko to nazywa się akomodacją (accomodiation) oka.
Na przeciwległej ścianie układu optycznego oka leży światłoczuła matryca, czyli siatkówka (retina). Wyściela ona ok. 70% wewnętrznej powierzchni gałki ocznej. Światło odbite od przedmiotów znajdujących się w scenie wizualnej lub emitowane przez nie oświetla dno oka i tworzy jej siatkówkowe odwzorowanie, Charakteryzuje się ono tym, że jest: sferyczne, pomniejszone i odwrócone „do góry nogami” w stosunku do oryginału (oczywiście zakładając, że wiemy, jak wygląda oryginał). Tak czy inaczej, dla mózgu takie zniekształcenia nie stanowią większego problemu.
Jeżeli obserwator ma w pełni sprawny układ optyczny to cały obraz sceny wizualnej jest rzutowany na powierzchnię siatkówki z bardzo dużą dokładnością. Jest ostry i wyraźny. Niestety, bynajmniej nie oznacza to, że siatkówka odzwierciedla go w każdym miejscu z taką samą jakością, z jaką jest na nią rzutowany. Ze względu na sposób, w jaki analizowany jest rozkład światła padającego na siatkówkę, można porównać ją do mocno podniszczonego ekranu kinowego, który w wielu miejscach jest pofałdowany, zanieczyszczony, a miejscami nawet podziurawiony. Krótko mówiąc, o ile ze względu na budowę, oko i aparat fotograficzny mają wiele wspólnych cech, o tyle funkcjonowanie tych urządzeń jest niemal całkowicie odmienne (Duchowski, 2007). Sensory w matrycy aparatu fotograficznego zarejestrują każdy parametr światła z taką samą jakością, fotoreceptory w siatkówce oka – nie.
W siatkówce występują dwa rodzaje fotoreceptorów, czyli komórek światłoczułych. Są to: czopki (cones) i pręciki (rods). Nazwy tych receptorów pochodzą od ich kształtów: czopki przypominają nieco stożki, a pręciki – walce (ryc. 10). Pręciki są nieporównywalnie bardziej wrażliwe na światło wpadające do oka niż czopki, dlatego czopki pracują w ciągu dnia a w nocy „zasypiają” zaadaptowane do ciemności. Z kolei pręciki, przeciwnie – „śpią” w dzień zaadaptowane do światła, a w nocy są aktywne (Młodkowski, 1998).
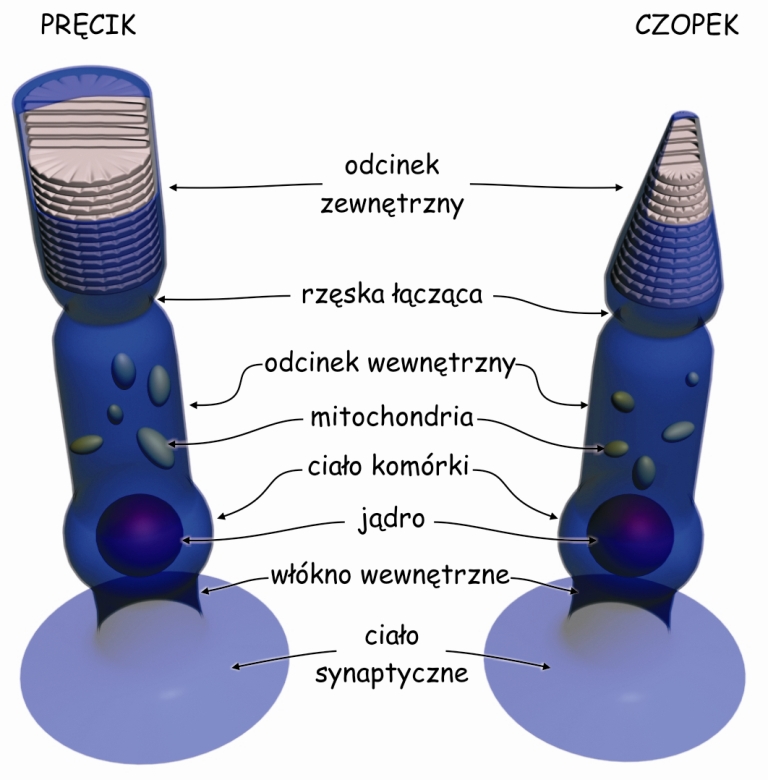
Czopki z różną siłą reagują na różne długości fal elektromagnetycznych w zakresie światła widzialnego, czyli mniej więcej od 400 do 700 nanometrów. Między długością fali elektromagnetycznej a widzeniem barw istnieje ścisła zależność (ryc. 11). Czopki reagują także na intensywność fali świetlnej. Z kolei pręciki nie różnicują barw, ale są szczególnie wyczulone na jasność (intensywność) światła. Obraz odzwierciedlany przez pręciki jest achromatyczny. Oznacza to tyle, że kiedy się ściemnia i pręciki przejmują kontrolę nad widzeniem przestajemy różnicować barwy, różnicując nadal odcienie szarości. Oczywiście zasada ta odnosi się wyłącznie do barw pokrywających powierzchnie, od których odbija się światło, a nie tych, które je emitują. W nocy widzimy kolorowe neony, ponieważ emitowane przez nie światło pobudza czopki. Możemy jednak nie dostrzec różnicy między zielenią i czerwienią lakierów dwóch stojących obok siebie samochodów w ciemnej ulicy, ponieważ w słabych warunkach oświetleniowych odbijają one mniej więcej tyle samo światła i pręciki zareagują na nie podobnie.
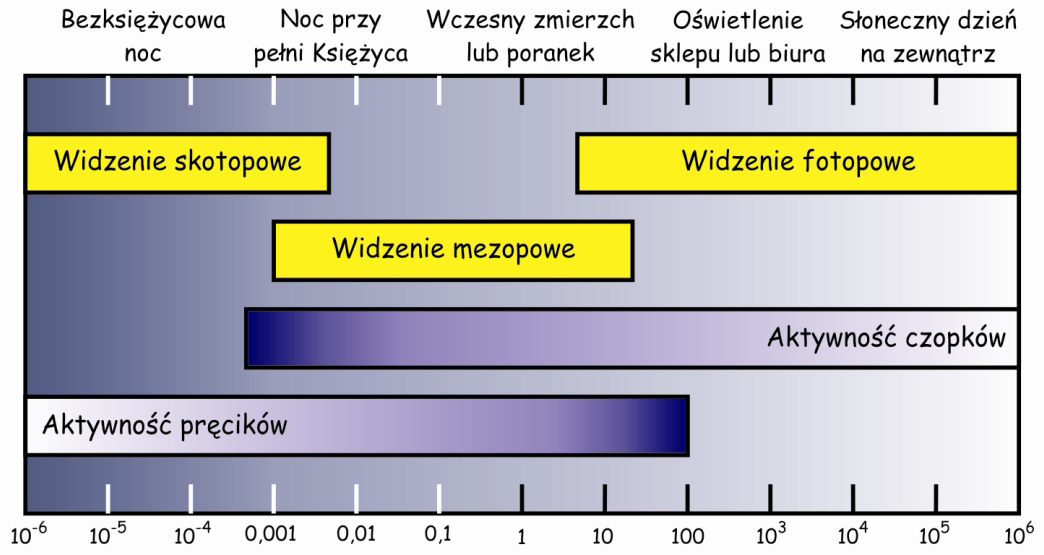
Widzenie w warunkach bardzo dobrego oświetlenia nazywa się widzeniem fotopowym (photopic) i biorą w nim udział przede wszystkim czopki, natomiast widzenie w warunkach słabego oświetlenia to widzenie skotopowe (scotopic) i jest ono wynikiem aktywności pręcików.
Podczas zmierzchu, wczesnym rankiem lub księżycową nocą pracują obydwa rodzaje fotoreceptorów. Im jest ciemniej, tym słabsza staje się reakcja czopków, a pręciki wybudzają się z dziennego letargu i reagują coraz intensywniej. Z kolei, im jest jaśniej wówczas czopki zaczynają intensywniej reagować na światło, a pręciki – coraz mniej. Mamy wówczas do czynienia z tzw. widzeniem mezopowym (mesopic) (ryc. 12). To szczególnie niebezpieczny czas dla kierowców, ponieważ żaden z systemów siatkówkowych nie działa wówczas na 100%. Jasność, która jest warunkiem aktywizacji określonego systemu widzenia wyraża się za pomocą jednostek zwanych kandelami na metr kwadratowy. Nie wchodząc w szczegóły definicyjne, jedna kandela odpowiada mniej więcej światłu o zmierzchu, już po zachodzie słońca.
Oglądanie obrazów jest możliwe przede wszystkim za pomocą czopków, które są odpowiedzialne za widzenie w dobrych warunkach oświetleniowych i dlatego im będziemy przyglądali się szczególnie uważnie.
Rozmieszczenie czopków w siatkówce
W siatkówce oka dorosłego człowieka można doliczyć się ok. 4,6 miliona czopków (Curcio, Sloan, Kalina i Hendrickson, 1990). Największe ich skupisko znajduje się w miejscu przecięcia siatkówki przez oś widzenia (visual axis). Jej drugi koniec przecina z kolei miejsce, na którym koncentrujemy wzrok. Oś widzenia jest nachylona pod kątem ok. 5° w stosunku do osi optycznej oka (optic axis), przebiegającej przez środki wszystkich elementów układu optycznego oka, czyli rogówki, źrenicy i soczewki (ryc. 13).
Punkt przecięcia osi widzenia z siatkówką to niewielki obszar w kształcie elipsy o cięciwach ok. 1,5 mm w pionie i 2 mm w poziomie oraz o powierzchni ok. 2,4 mm2 (Niżankowska, 2000). Miejsce to nazywa się plamką żółtą (macula) i jest tam upakowanych ponad pół miliona czopków, czyli ponad 200 tys./mm2. Dla porównania, na 1 mm2 powierzchni ekranu LCD o rozdzielczości 1920 x 1200 znajdują się zaledwie 3–4 piksele. To 50 tys. razy mniej niż w centralnej części oka!
Wewnątrz plamki żółtej znajduje się jeszcze mniejszy obszar o powierzchni ok. 1 mm2, zwany dołkiem centralnym (fovea). W jego środku tzw. dołeczku (foveola) liczba czopków może osiągnąć nawet 324 tys./mm2. U dorosłego człowieka jest ich w tym miejscu średnio ok. 199 tys./mm2 (Curcio i in., 1990), a im dalej od dołka centralnego tym jest ich mniej (ryc. 14).
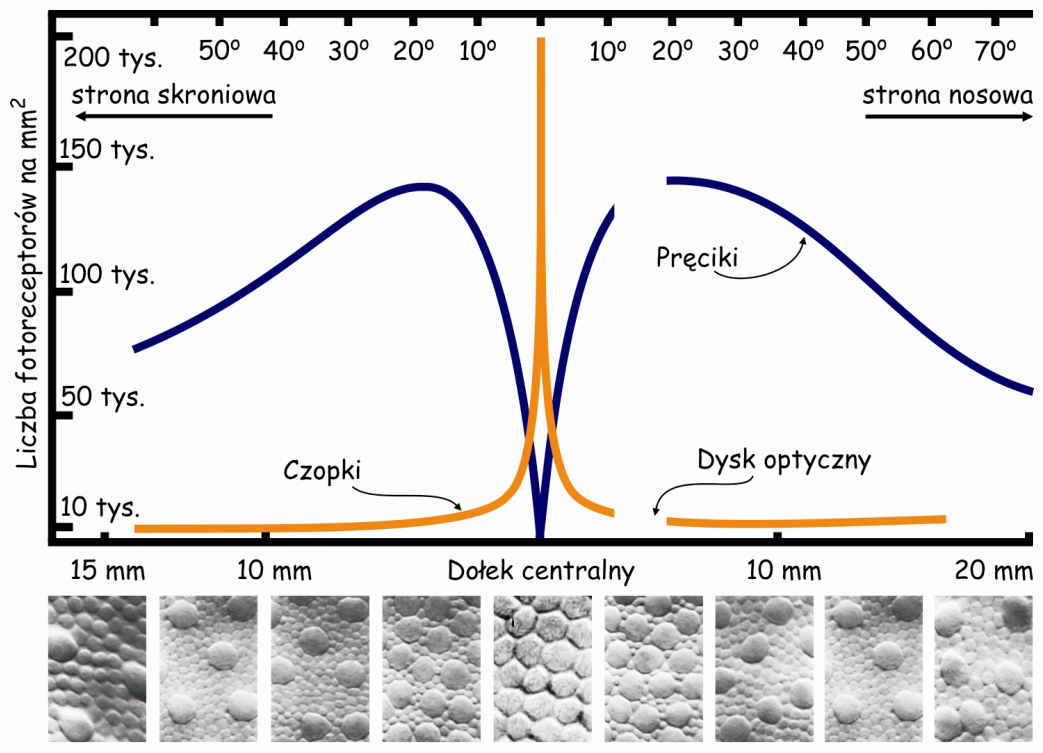
Gdyby można było wykorzystać czopki z okolicy środka dołka centralnego do zbudowania małoobrazkowej matrycy o wymiarach 36 x 24 mm z przeznaczeniem dla cyfrowego aparatu fotograficznego, to jej rozdzielczość wynosiłaby nie 12, czy nawet 30 megapikseli, ale ok. 280 Mpix! Dokładność obrazu rejestrowanego przez komórki znajdujące się w okolicy dołka centralnego jest niewyobrażalnie duża. Na ryc. 15 można zobaczyć powiększoną 900 razy powierzchnię siatkówki w okolicy środka dołka centralnego, z widocznymi czopkami w kształcie plamek (Ahnelt, Kolb i Pflug, 1987). Mniej więcej w taki sposób wygląda powierzchnia całej siatkówki-ekranu, na który rzutowany jest obraz znajdujący się naprzeciwko oka. W różnych miejscach może być tylko nieco inne zagęszczenie fotoreceptorów. To czego mózg dowiaduje się na temat świata za pośrednictwem oczu jest bezpośrednio związane z aktywnością tych niewielkich punktów ekranowych.

Powierzchnia dołka centralnego stanowi zaledwie 0,1% powierzchni całej siatkówki, zaś powierzchnia plamki żółtej – 0,3% (Młodkowski, 1998). Nie ma tam w ogóle pręcików, a znajdujące się w tym obszarze czopki stanowią 1/8 wszystkich czopków znajdujących się w siatkówce. Pozostałe 4–5 milionów czopków rozkłada się na 99,7% powierzchni siatkówki wokół plamki żółtej. Oznacza to, że na 1 mm² siatkówki poza plamką żółtą przypada ich średnio ok. 7 tys. (Hofer, Carroll i Williams, 2009). To nadal całkiem sporo, ale na przeważającej części siatkówki jest ich jednak prawie trzydzieści razy mniej niż w dołku centralnym.
Jak nietrudno się domyślić, bezpośrednią konsekwencją opisanego rozkładu fotoreceptorów na siatkówce jest to, że w zależności od miejsca jej oświetlenia, rzutowany obraz jest przetwarzany z inną rozdzielczością przestrzenną. Innymi słowy, z miejsc o większym zagęszczeniu fotoreceptorów mózg czerpie znacznie więcej danych, które pozwalają mu wyraźniej zrekonstruować obraz sceny wizualnej, niż na podstawie danych pochodzących z tych części siatkówki, które są uboższe w fotoreceptory.
Kilka zdań na temat pręcików
Jak zostało to już zasygnalizowane, oprócz czopków, w siatkówce ludzkiego oka znajdują się jeszcze inne fotoreceptory, czyli pręciki. Ich liczba waha się od 78 do 107 milionów w zależności od człowieka (średnio ok. 92 miliony). Pręcików jest zatem ponad 20 razy więcej niż czopków (Curcio i in., 1990). Oznacza to, że siatkówka jest znacznie gorzej wyposażona „hardwareowo” do oglądania świata w barwach przy pełnym oświetleniu niż monochromatycznie i w ciemności. Najprawdopodobniej jest to pozostałość po naszych drapieżnych przodkach, którym niespecjalnie zależało na oglądaniu świata w kolorach i zdecydowanie preferowali polowanie nocą niż w ciągu dnia. No cóż, widzenie barwne odziedziczyliśmy po naszych małpich przodkach, którzy woleli spożywać posiłki w ciągu dnia, uważnie przyglądając się barwie skórki od banana lub mango. Miało to decydujące znaczenie, co najmniej w kwestii niestrawności.
W dołku centralnym nie ma pręcików a pierwsze pojawiają się dopiero na obrzeżach plamki żółtej. Im dalej od plamki żółtej tym jest ich więcej, a największa liczba pręcików znajduje się w odległości ok. 20° od dołka centralnego i jest porównywalna do liczby czopków w plamce żółtej, czyli ok. 150 tys./mm2 (ryc. 14). Przesuwając się jeszcze dalej w kierunku peryferii siatkówki liczba pręcików stopniowo zmniejsza się i na jej krawędziach jest ich już o połowę mniej, czyli ok. 75 tys./mm2.
Taki rozkład pręcików powoduje, że w słabych warunkach oświetleniowych, możemy dostrzec coś w miarę wyraźnie nie patrząc wprost tylko „kątem oka”, a dokładniej, przesuwając środek układu optycznego oka o ok. 20° kątowych od miejsca, które chcemy dokładnie zobaczyć. Dopiero wtedy obraz rzutowany na siatkówkę zostanie zinterpretowany z największą możliwą rozdzielczością.
Dziura w siatkówce
Na koniec jeszcze kilka zdań, dotyczących drobnego szczegółu konstrukcyjnego siatkówki. Mniej więcej w odległości 15° od dołka centralnego, w przynosowej części siatkówki każdego oka znajduje się dosłownie „dziura” o średnicy 1,5 mm i powierzchni ok. 1,2 mm2. To miejsce nazywa się plamką ślepą (blind spot) lub tarczą nerwu wzrokowego (optic disc) i nie ma w tym miejscu ani jednego fotoreceptora. Tamtędy przechodzi nerw wzrokowy, po którym biegną sygnały o stanie pobudzenia fotoreceptorów do wnętrza mózgu, a także naczynia krwionośne, niezbędne do dotlenienia komórek wewnątrz oka. W tym miejscu obraz rzutowany na dno oka trafia w pustkę. Bardzo łatwo można się o tym przekonać. Wystarczy zamknąć prawe oko i lewym patrzeć na jeden z krzyżyków, znajdujący się po prawej stronie na ryc. 16, a następnie powoli zbliżać się i oddalać od niego. W którymś położeniu głowy stwierdzimy, że leżące po lewej stronie kółko staje się niewidoczne, a przerwa w linii znika. Dzieje się tak ponieważ obraz punktu lub przerwy w linii jest rzutowany na plamkę ślepą.

Na szczęście mamy dwoje oczu i to znacznie zmniejsza problemy związane z niewidzeniem fragmentu obrazu w obrębie plamki ślepej. Ponieważ oczy są odsunięte od siebie, dlatego na ich siatkówki w punkcie tarczy nerwu wzrokowego rzutowane są nieco inne fragmenty sceny wizualnej. W rezultacie, ten fragment, którego nie widzi jedno oko, widzi drugie i vice versa. Ostatecznie mózg i tak analizuje dane dostarczone mu równocześnie z obu oczu.
Wyspecjalizowane komórki zwojowe
Oddolna analiza zawartości sceny wizualnej na wczesnych etapach szlaku wzrokowego jest możliwa dzięki obecności w siatkówkach oczu obserwatora nie tylko fotoreceptorów, ale również różnych typów komórek nerwowych, z których szczególnie ważną rolę pełnią wspomniane już komórki zwojowe (ganglion cells). Specjalizują się one w przetwarzaniu danych, dotyczących: (1) długości fali światła widzialnego, co stanowi podstawę widzenia barw, (2) kontrastów jasności światła, dzięki czemu widzimy, m.in. krawędzie rzeczy lub ich części, czyli generalnie rzecz biorąc – kształty, (3) zmienności oświetlenia w czasie, która stanowi podstawę widzenia ruchu i (4) rozdzielczości przestrzennej, która leży u podłoża ostrości widzenia.
Wśród wielu rodzajów komórek zwojowych można zidentyfikować takie, które są szczególnie wrażliwe, np. na częstotliwość fali światła widzialnego odpowiadającego barwie zielonej. Oznacza to mniej więcej tyle, że jeżeli te komórki zwojowe wysyłają – niczym alfabetem Morse’a – impulsy nerwowe w kierunku kory mózgu, wówczas obserwator doświadcza widzenia czegoś zielonego. A jeśli zaktywizują się komórki odpowiedzialne za detekcję ruchu, to mózg „dowiaduje się”, że coś się zmienia przed oczyma obserwatora, choć na podstawie tych informacji jeszcze nie „wie” czy to coś się rusza w scenie wizualnej, czy porusza się obserwator, czy też jedno i drugie. Ale i tego szybko „się dowie” analizując dane płynące z innych zmysłów. Dość powiedzieć, że widzenie takiej czy innej własności obrazu bezpośrednio wynika z kondycji neuronalnych przetworników i przekaźników danych sensorycznych. Ich uszkodzenie może spowodować, że jakiejś cechy obrazu po prostu nie dostrzegamy, jakby jej nie było.
Kiedy przyjrzymy się budowie anatomicznej komórek zwojowych okazuje się, że zasadniczo dzielą się one na trzy grupy. Pierwszą, stanowią komórki karłowate (midget ganglion cells), o drobnych ciałach i stosunkowo niewielkiej liczbie odgałęzień, czyli drzew dendrytycznych oraz aksonu. Druga grupa to komórki parasolowe (parasol ganglion cells), o dużych ciałach i znacznie większej ilości odgałęzień (ryc. 17). Trzecią grupę tworzą komórki pyłkowe (bistratified ganglion cells), o maleńkich ciałach i nieproporcjonalnie dużych rozgałęzieniach w stosunku do wielkości ich ciała, choć i tak znacznie mniejszych niż rozgałęzienia komórek parasolowych, a nawet karłowatych (Dacey, 2000).
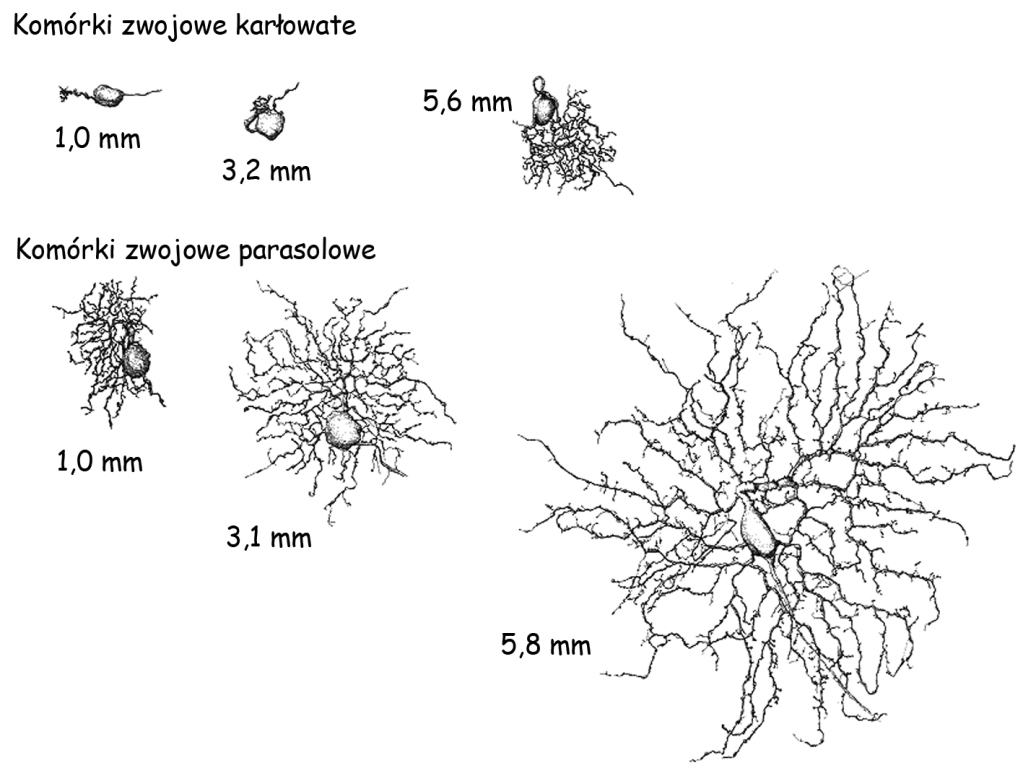
Chociaż komórki karłowate są mniejsze niż parasolowe, to ich wielkość, a zwłaszcza ilość i rozłożystość drzew dendrytycznych, które umożliwiają im odbieranie impulsów nerwowych od innych komórek, zależy od odległości, w jakiej znajdują się one od dołka centralnego. Im bliżej znajdują się dołka centralnego, tym jedne i drugie są mniejsze.
Oprócz dendrytów, każda komórka nerwowa ma również akson, czyli takie odgałęzienie, które odprowadza impulsy nerwowe z ciała danej komórki do innej. To właśnie aksony wszystkich trzech rodzajów komórek zwojowych tworzą zasadniczy zrąb nerwu wzrokowego (opitc nerve). Składa się on z ok. 1 miliona (od 770 tysięcy do 1,7 miliona) aksonów komórek zwojowych (Jonas, Schmidt, Müller-Bergh, Schlötzer-Schrehardt i in., 1992) i przypomina nieco przewód elektryczny, złożony z miedzianych drucików.
Ilość aksonów trzech wymienionych typów komórek zwojowych w nerwie wzrokowym nie jest taka sama. Najwięcej, bo ok. 80% stanowią aksony komórek karłowatych, a tylko po ok. 10% stanowią aksony komórek parasolowych i pyłkowych. Włókna komórek małych (tzn. karłowatych i pyłkowych) stanowią zatem ok. 90% wszystkich aksonów tworzących nerw wzrokowy. Oznacza to, że z jakiś powodów dane przesyłane przez mniejsze komórki zwojowe są ważniejsze dla mózgu niż dane docierające doń za pośrednictwem aksonów większych (parasolowych) komórek zwojowych.
Ciała komórek zwojowych znajdują się w siatkówce oka. Ich dendryty odbierają dane z fotoreceptorów, za pośrednictwem jeszcze innych komórek, ale nimi zajmiemy się później. W każdym razie, ze względu na mniejszą ilość dendrytów, komórki karłowate łączą się ze znacznie mniejszą ilością fotoreceptorów i innych komórek w siatkówce, niż komórki parasolowe, które mają duże drzewa dendrytyczne. Ważne jest natomiast to, że małe komórki zwojowe (karłowate i pyłkowe) łączą się przede wszystkim z fotoreceptorami znajdującymi się w centralnej części siatkówki. Są one więc znacznie wrażliwsze na rozdzielczość przestrzenną oświetlenia siatkówki niż komórki parasolowe. Dzięki komórkom karłowatym możemy zatem z wielką dokładnością odróżniać od siebie kształty jednych rzeczy od innych. Pewien problem stanowi tylko to, że największe ich skupisko pokrywa stosunkowo niewielki obszar siatkówki, a w rezultacie – niewielki zakres pola widzenia.
Inną własnością małych komórek zwojowych jest ich wrażliwość na długości fal świetlnych. Ponad 90% z nich specjalizuje się w tym zakresie, dając początek procesom widzenia i różnicowania barw. Niemal wszystkie komórki karłowate znakomicie różnicują długości fali elektromagnetycznej, odpowiadającej barwie zielonej i czerwonej, natomiast znacznie gorzej radzą sobie z opozycją barw żółtej i niebieskiej. Ale to zadanie wykonują komórki pyłkowe. To one odgrywają podstawową rolę w przetwarzaniu danych dotyczących różnicowania barwy niebieskiej i żółtej (Dacey, 2000).
W przeciwieństwie do małych komórek zwojowych, komórki zwojowe typu parasolowego nie różnicują długości fali świetlnej, ale za to są znacznie wrażliwsze na wykrywanie krawędzi między płaszczyznami o podobnej jasności, niż komórki karłowate. Są one w stanie zarejestrować 1–2‑procentową różnicę w jasności płaszczyzn leżących obok siebie, a 10–15-procentowe różnice w jasności kodują bez problemów (Shapley, Kaplan i Soodak, 1981).
Komórki karłowate wymagają znacznie większej różnicy w zakresie jasności leżących obok siebie płaszczyzn, żeby ją zarejestrować. Ponadto, komórki parasolowe pokrywają dużo większy obszar siatkówki oka niż komórki karłowate. Obie te cechy dużych komórek zwojowych znakomicie uzupełniają ograniczenia małych komórek w zakresie detekcji konturów rzeczy znajdujących się w polu widzenia obserwatora poza dołkiem centralnym oraz w odniesieniu do relacji przestrzennych między nimi.
Jest jeszcze jedna ważna różnica między komórkami małymi i dużymi. Otóż duże komórki mają znacznie grubsze aksony niż komórki małe i dlatego przesyłają impulsy nerwowe dwukrotnie szybciej, tj. z prędkością ok. 4 m/sek., niż komórki karłowate. Ta własność komórek parasolowych ma kluczowe znaczenie dla detekcji zmian w oświetleniu siatkówki, co pozwala obserwatorowi dostrzegać ruch. Wzrokowa detekcja ruchu przedmiotu (a także ruchu obserwatora) jest równoznaczna z przesuwaniem się tego samego lub podobnego układu światła i cienia po siatkówce oka w czasie. Tempo i kierunek przesunięć obrazu na siatkówce jest wskaźnikiem szybkości i kierunku ruchu.
Kończąc tę funkcjonalną charakterystykę wielkich i drobnych komórek nerwowych warto również zauważyć, że podobnie jak cechy niemal każdej sceny wizualnej również i one dają się połączyć w dwie kategorie. Otóż komórki karłowate i pyłkowe, są szczególnie wrażliwe na barwę i rozdzielczość przestrzenną światła, która stanowi podstawę widzenia kształtów rzeczy w scenie wizualnej i różnicowania ich od siebie. Można powiedzieć, że to dzięki ich aktywności mamy szansę oddzielać od siebie i od tła przedmioty, które tworzą scenę wizualną. To najbardziej podstawowa funkcja widzenia i właśnie dlatego aksony komórek karłowatych i pyłkowych są tak licznie reprezentowane w nerwie wzrokowym.
Z kolei komórki parasolowe, dzięki dużej szybkości przesyłania sygnałów oraz znacznie większej wrażliwości na różnicowanie odcieni jasności w scenie wizualnej, niż komórki małe, umożliwiają widzenie ruchu i organizacji przestrzennej oglądanej sceny, a także bardzo skutecznie wspomagają proces identyfikacji konturów rzeczy.
Tak oto z budowy anatomicznej i fizjologii komórek zwojowych wynikają określone ich funkcje, a z nich zaczynają wyłaniać się zręby subiektywnego doświadczenia widzenia obrazu. Obrazy widzimy bowiem tak jak widzimy, ponieważ taki mamy biologiczny hardware, a nie dlatego, że one takie są.
Od siatkówki do ciała kolankowatego bocznego
Pierwszą strukturą w mózgu, do której docierają informacje z siatkówek oczu jest znajdujące się we wzgórzu, ciało kolankowate boczne (LGN). Już w latach 20. XX wieku Mieczysław Minkowski, szwajcarski neurolog polskiego pochodzenia odkrył, że aksony małych i wielkich komórek zwojowych łączą się z LGN w zaskakująco uporządkowany sposób (Valko, Mumenthaler i Bassetti, 2006).
Budowa LGN przypomina ziarno fasoli, po przecięciu którego ujawnia się sześć wyraźnie oddzielonych od siebie warstw komórek nerwowych o dwóch różnych wielkościach (ryc. 18).
Ciemniejsze warstwy komórek oznaczone cyframi 1 i 2, odbierają impulsy nerwowe za pośrednictwem aksonów parasolowych komórek zwojowych. Ponieważ ciała komórek tworzących te warstwy w LGN również mają stosunkowo duże rozmiary, dlatego warstwy te są zwane – wielkokomórkowymi (magnocellular layers), typu M (magno) lub typu Y.
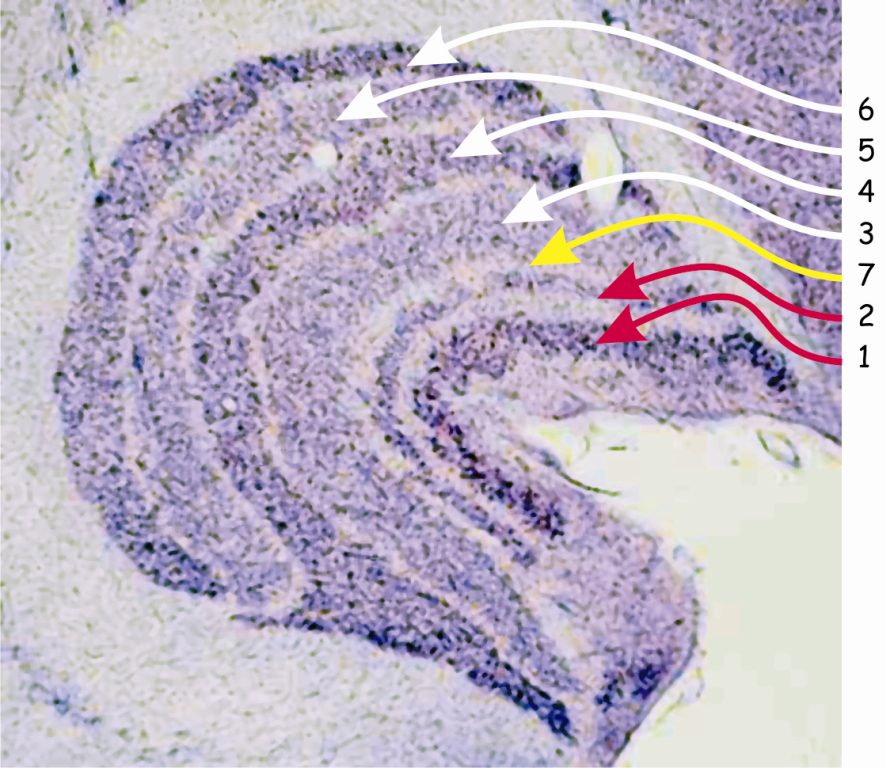
Warstwy oznaczone cyframi 3–6 odbierają sygnały z aksonów małych komórek zwojowych, a ponieważ same również składają się z komórek o niewielkich ciałach, dlatego te warstwy zwane są – drobnokomórkowymi (parvocellular layers), typu P (parvo) lub typu X. Budowa anatomiczna i cechy funkcjonalne małych i dużych komórek zwojowych zlokalizowanych w siatkówkach oczu oraz komórek tworzących poszczególne warstwy ciała kolankowatego bocznego, są niemal identyczne. Dlatego też wśród badaczy zajmujących się problematyką widzenia jest zgoda, co do tego, że parasolowe komórki zwojowe, a w dwóch warstwach LGN – komórki typu M są częścią tzw. wielkokomórkowego szlaku wzrokowego (magnocellular pathway), natomiast karłowate komórki zwojowe, a w czterech warstwach LGN – komórki typu P wyznaczają, tzw. drobnokomórkowy szlak wzrokowy (parvocellular pathway).
Na ryc. 18 zaznaczono także warstwę siódmą, która znajduje się między warstwami wielko- i drobnokomórkowymi, czyli drugą i trzecią. W tej warstwie znajdują się komórki pyłkowe (koniocellular cells) lub inaczej – typu K, które odbierają projekcje ze zwojowych komórek pyłkowych. W związku z istnieniem tej warstwy w LGN, do dwóch poprzednich, należy dodać trzeci szlak wzrokowy, tzw. pyłkokomórkowy (koniocellular pathway). Ponieważ komórki na szlaku pyłkokomórkowym stanowią zaledwie ok. 10% wszystkich komórek zwojowych oraz z uwagi na to, że pełnią one analogiczne funkcje do funkcji pełnionych przez komórki karłowate, dlatego szlak pyłkokomórkowy traktuje się jako część szlaku drobnokomórkowego.
Podsumowując własności drobno- i wielkokomórkowego szlaku wzrokowego warto rzucić okiem na poniższe zestawienie.
| Charakterystyka | Szlak wielkokomórkowy | Szlak drobnokomórkowy |
| Wielkość ciała komórek zwojowych | duże | małe |
| Wielkość pola recepcyjnego komórek zwojowych | duże | małe |
| Szybkość transmisji impulsów nerwowych | szybka | wolna |
| Ilość aksonów w nerwie wzrokowym i trakcie optycznym | mała | duża |
| Różnicowanie barw | nie | tak |
| Wrażliwość na kontrast | mała | duża |
| Rozdzielczość przestrzenna | mała | duża |
| Rozdzielczość czasowa i wrażliwość na ruch | duża | mała |
| Wrażliwość na różnicowanie jasności płaszczyzn leżących obok siebie | duża | mała |
Podział warstw w LGN ze względu na skrzyżowanie wzrokowe
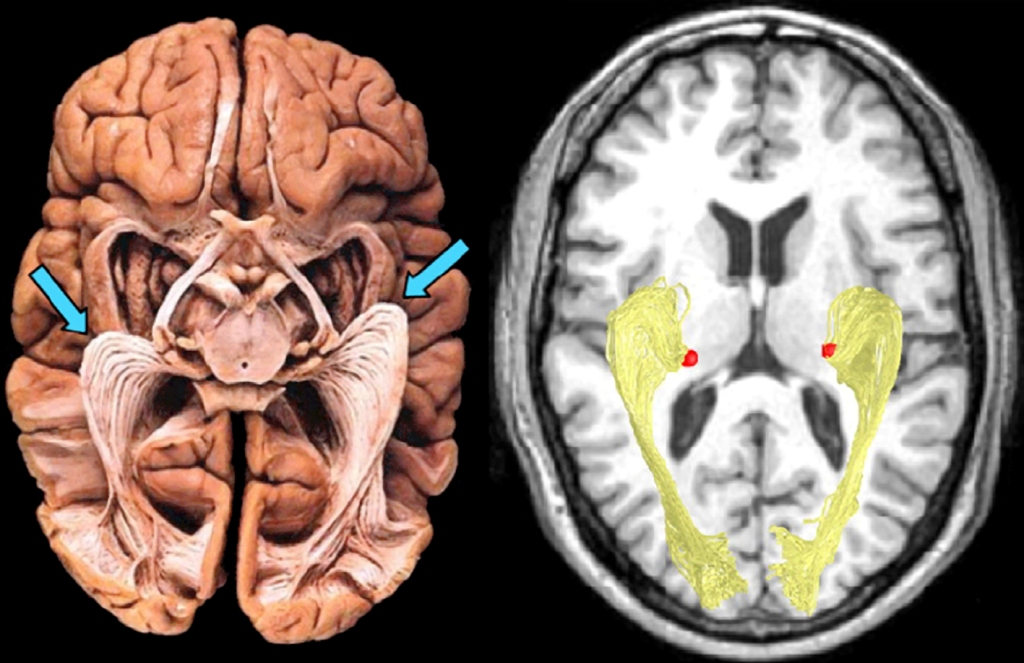
Warstwy LGN dzielą się nie tylko na pyłkowe, drobne i wielkie, ale również na prawe i lewe. Podobnie jak większość struktur mózgowych, LGN jest ciałem parzystym, tzn. występuje zarówno po prawej, jak i po lewej stronie mózgu. U naczelnych, w tym także u człowieka, między siatkówkami oczu a LGN znajduje się wspomniane już skrzyżowanie wzrokowe (ryc. 19). Jest to miejsce podziału wiązek aksonów komórek zwojowych na dwie części. To bardzo sprytny wynalazek ewolucji, ponieważ dzięki niemu utrata jednego oka nie pociąga za sobą całkowitego wyłączenia którejś części mózgu z przetwarzania danych wzrokowych. Po skrzyżowaniu się wiązek nerwu wzrokowego, do LGN, leżącego po tej samej stronie co oko, trafiają dane z zewnętrznej (skroniowej) części siatkówki tego oka oraz dane z przynosowej części siatkówki drugiego oka.
W wyniku podziału aksonów nerwu wzrokowego na dwie części, warstwy LGN oznaczone na ryc. 18 numerami 1, 4 i 6 odbierają sygnały z oka leżącego po przeciwnej stronie głowy, a warstwy 2, 3 i 5 – z oka znajdującego się po tej samej stronie głowy co LGN. Ta sama zasada dotyczy obu struktur LGN, znajdujących po prawej i po lewej stronie głowy.
Warto zapamiętać, że LGN pełni funkcję organizującą dane sensoryczne dotyczące różnych cech sceny wizualnej. Po niemal chaotycznej plątaninie dendrytów i aksonów rozlicznych komórek, z których zbudowana jest siatkówka oka, od tego miejsca już znacznie łatwiej można się zorientować, po których przewodach płyną dane źródłowe dotyczące barw, konturów rzeczy, ich ruchu i organizacji przestrzennej. Ponadto ich uporządkowanie pozwala przewidzieć, nie tylko z której strony ciała one napływają, ale także z której części oka. Widzenie jest poważnym przedsięwzięciem logistycznym dla mózgu i dlatego dobra organizacja danych jest podstawą sukcesu, czyli zbudowania trafnej reprezentacji sceny wizualnej.
Promienistość wzrokowa
Ostatni etap wczesnego szlaku przetwarzania danych wzrokowych kończy się na tzw. promienistości wzrokowej (optic radiation). Za jej pośrednictwem, dane o rozkładzie światła w scenie wizualnej są dostarczone do kory wzrokowej (visual cortex) w płacie potylicznym (occipital lobe), a ściślej mówiąc do tzw. bruzdy ostrogowej (calcarine sulcus), znajdującej się po wewnętrznej stronie tych płatów. Promienistość w istocie jest pasmem aksonów komórek, których ciała tworzą poszczególne warstwy w LGN. Swoją oryginalną nazwę bierze ze specyficznego układu włókien, które szerokim łukiem rozkładają się wśród ciasno upakowanych struktur leżących pod korą mózgu (ryc. 20).
Frenologiczny punkt widzenia na funkcje kory mózgu w procesie widzenia
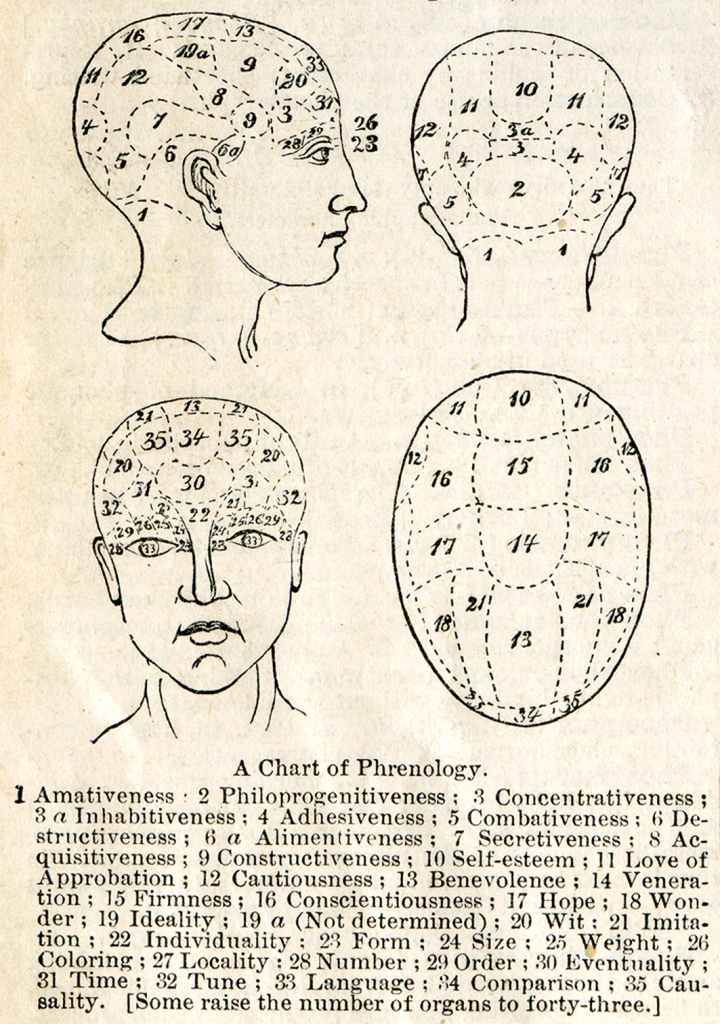
Jeszcze pod koniec XIX dominującą koncepcją neuropsychologiczną była frenologia (phrenology). Zgodnie z założeniami jej twórcy, niemieckiego fizyka Franza Josefa Galla, istnieje ścisły związek między budową anatomiczną i lokalizacją różnych struktur kory mózgu a realizowanymi przez nie funkcjami psychicznymi, czyli umysłem. Jakkolwiek obecnie frenologia jest traktowana jako pseudonauka, to w istocie była ona niezwykle trafną intuicją, która leży u podstaw współczesnej neuronauki (Fodor, 1983).
Ze względu na brak odpowiednich narzędzi diagnostycznych, a także metodologii badań neuropsychologicznych, frenologowie dość swobodnie kojarzyli funkcje psychiczne z różnymi częściami kory mózgu. W odniesieniu do widzenia nie mieli jednak wątpliwości, że jest ono realizowane przez korę czołową, nad- i okołooczodołową. Całą tę część kory określono jako percepcyjną i różnym jej fragmentom przypisano funkcje widzenia: kształtu (form, pole 23), wielkości (size, pole 24) i barwy (coloring, pole 26), a także odczuwania ciężaru (weight, pole 25). W okolicach skroniowych oczodołów lokalizowali funkcje związane z percepcją liczb (number, pole 28) i zdolnościami obliczeniowymi (order, calculation, pole 29), a w korze zaoczodołowej – funkcje językowe (language, pole 33). W strukturach czołowych znalazła również swoją lokalizację wyobraźnia (imitation, pole 21) (ryc. 21).
Frenologowie nawet się nie domyślali, że widzenie jest procesem, który angażuje najbardziej oddalone od oczu struktury kory mózgu, czyli płat potyliczny. Tym częściom mózgu byli raczej skłonni przypisać takie funkcje, jak płodność, miłość rodzicielską i miłość do dzieci w ogóle (philoprogenitiveness, pole 2), przyjaźń i przywiązanie (adhesiveness, pole 4), umiłowanie domu i ojczyzny (inhabitativeness, pole 3a), a także zdolność do koncentracji uwagi, zwłaszcza w zadaniach intelektualnych (concentrativeness, pole 3).
Interesujące są także funkcje przypisywane przez frenologów płatom skroniowym, które – jak dzisiaj już wiemy – także odgrywają istotną rolę w widzeniu. Raczej lokalizowali w nich podstawę przebojowości (combativeness, pole 5), siły (destructiveness, pole 6) i powściągliwości (secretiveness, pole 7).
Wyniki badań w obszarze neuronauki ujawniły całkowicie odmienną od frenologicznej lokalizację struktur odpowiedzialnych za różne funkcje psychiczne, a w szczególności za widzenie.
Kora wzrokowa w świetle neuronauki
Przetwarzaniem danych sensorycznych na wyższych piętrach szlaku wzrokowego, zajmuje się ok. 4–6 miliardów komórek nerwowych w płacie potylicznym, ciemieniowym, skroniowym, a nawet czołowym. W sumie, dane zarejestrowane przez fotoreceptory znajdujące się w siatkówkach oczu angażują ok. 20% całej powierzchni kory mózgu człowieka (Wandell, Dumoulin i Brewer, 2009). Ze względu na szczególnie ważną rolę, jaką w procesie widzenia odgrywają płaty potyliczne, obszar ten nazywa się także korą wzrokową (visual cortex) (ryc. 22).
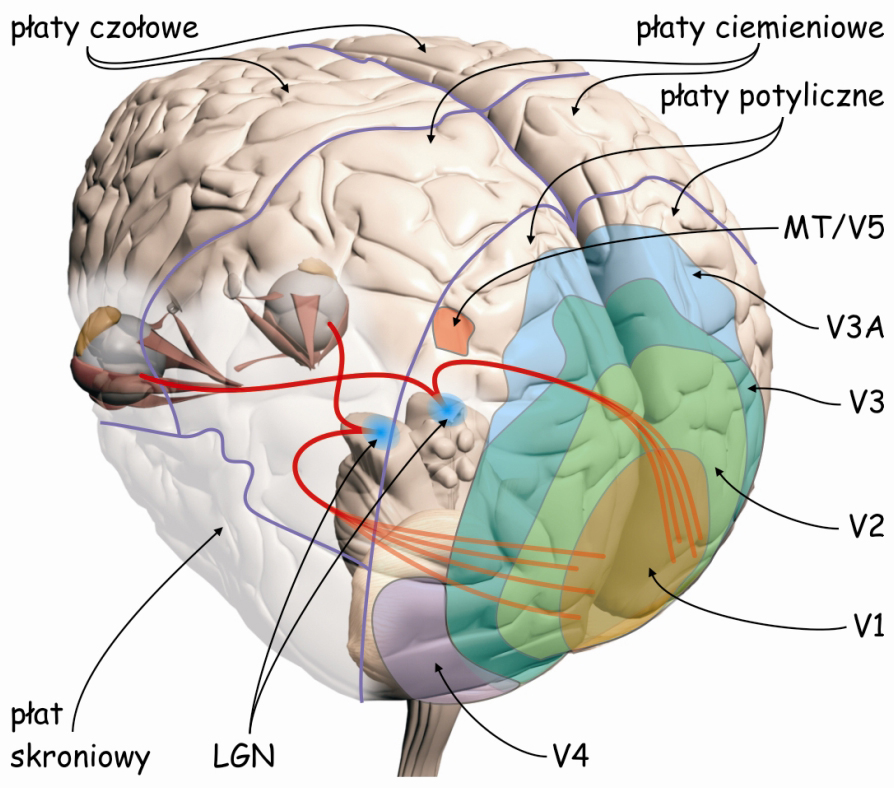
Ze względu na budowę anatomiczną, korę wzrokową można podzielić na dwie części: korę prążkową (striate cortex) i korę pozaprążkową (extrasrtriate cortex). Kora prążkowa znajduje się w miejscu, zwanym bruzdą ostrogową (calcarine sulcus), na samym końcu płata potylicznego, w jego części przyśrodkowej (ryc. 23 A). Zgodnie z klasyfikacją obszarów mózgu zaproponowaną w 1907 roku przez niemieckiego neurologa, Korbiniana Brodmanna, jest to pole 17. Oprócz bruzdy ostrogowej obejmuje ono także fragment zewnętrznej części płata potylicznego (ryc. 23B). Pole 17 jest również określane, jako pierwszorzędowa kora wzrokowa (primery visual cortex) lub obszar V1 (od pierwszej litery angielskiego słowa vision i podkreślenia, że jest to pierwszy korowy etap szlaku wzrokowego).
W obu półkulach mózgu, w obszarze V1 znajduje się ok. 300 milionów neuronów, czyli 40 razy więcej niż liczba neuronów w LGN (Wandell, 1995). Do V1 płyną impulsy nerwowe wzdłuż promienistości wzrokowej, czyli po aksonach komórek, których ciała znajdują się w LGN.
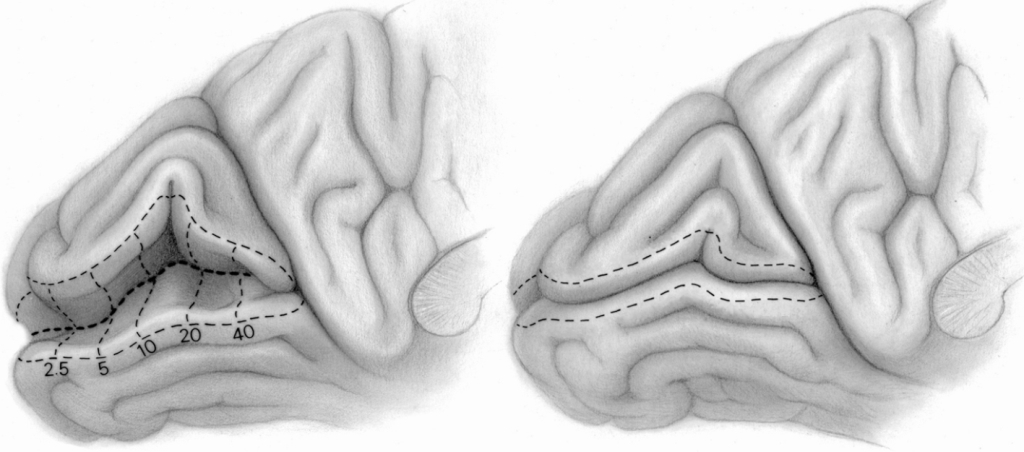
Pozostałe części kory wzrokowej nazywa się korą pozaprążkową. Zasadniczo obejmuje ona brodmannowskie pola 18 i 19, lub zgodnie z inną notacją, obszary: V2, V3, V3A, V4 i V5 (ryc. 22). W analizie danych wzrokowych biorą również udział struktury korowe, znajdujące się we wszystkich płatach mózgu: w płacie ciemieniowym, np. V7 lub bruzda śródciemieniowa (intraparietal sulcus; IPS), w płacie skroniowym, np. dolna kora skroniowa (inferior temporal cortex; ITC) lub górna bruzda skroniowa (superior temporal sulcus; STS) oraz w płacie czołowym, np. korowy ośrodek skojarzonego spojrzenia w bok (frontal eye field; FEF).
Żeby zrozumieć, co mózg robi ze światłem pobudzającym fotoreceptory w siatkówkach oczu trzeba przeanalizować budowę i funkcje wszystkich tych jego części korowych, które są zaangażowane w widzenie.
Skąd się biorą prążki na powierzchni kory V1?
Kora prążkowa bierze swoją nazwę od wyglądu powierzchni, przypominającej nieco umaszczenie zebry (ryc. 24). Ciemniejsze prążki widoczne na jej powierzchni powstały w wyniku wybarwienia komórek za pomocą techniki oksydazy cytochromowej (cytochrome oxidase; COX). Odbierają one sygnały płynące z oka leżącego po przeciwnej stronie głowy niż dany fragment kory V1 (LeVay, Hubel i Wiesel, 1975; Sincich i Horton, 2002). Jak pamiętamy, po skrzyżowaniu wzrokowym, poszczególne warstwy komórek w prawym i w lewym LGN odbierają sygnały płynące zarówno z oka leżącego po tej samej, jak i po przeciwnej stronie głowy. Podobnie jest w korze V1. Do obu jej części, czyli z prawej i z lewej strony mózgu płyną impulsy nerwowe z oczu leżących po obu stronach głowy.
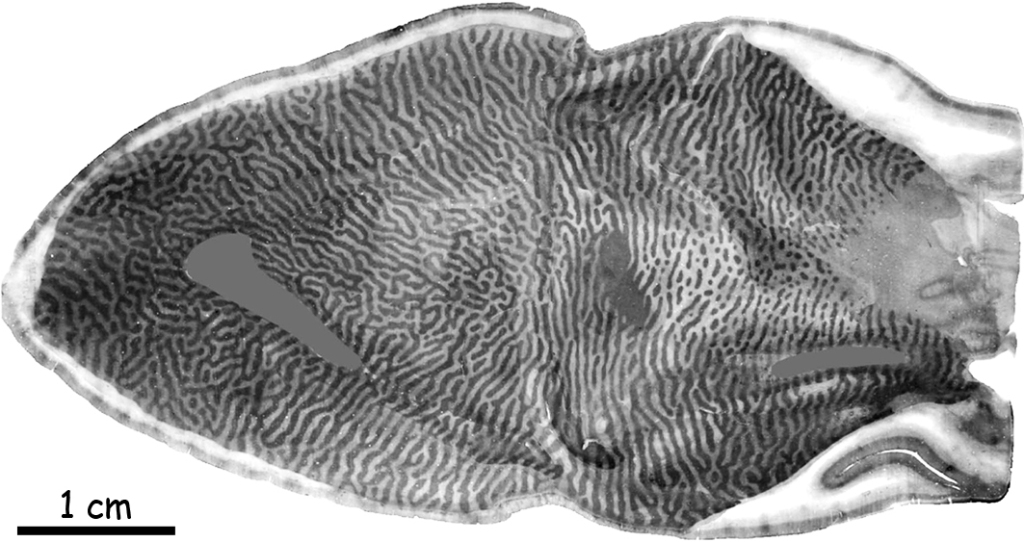
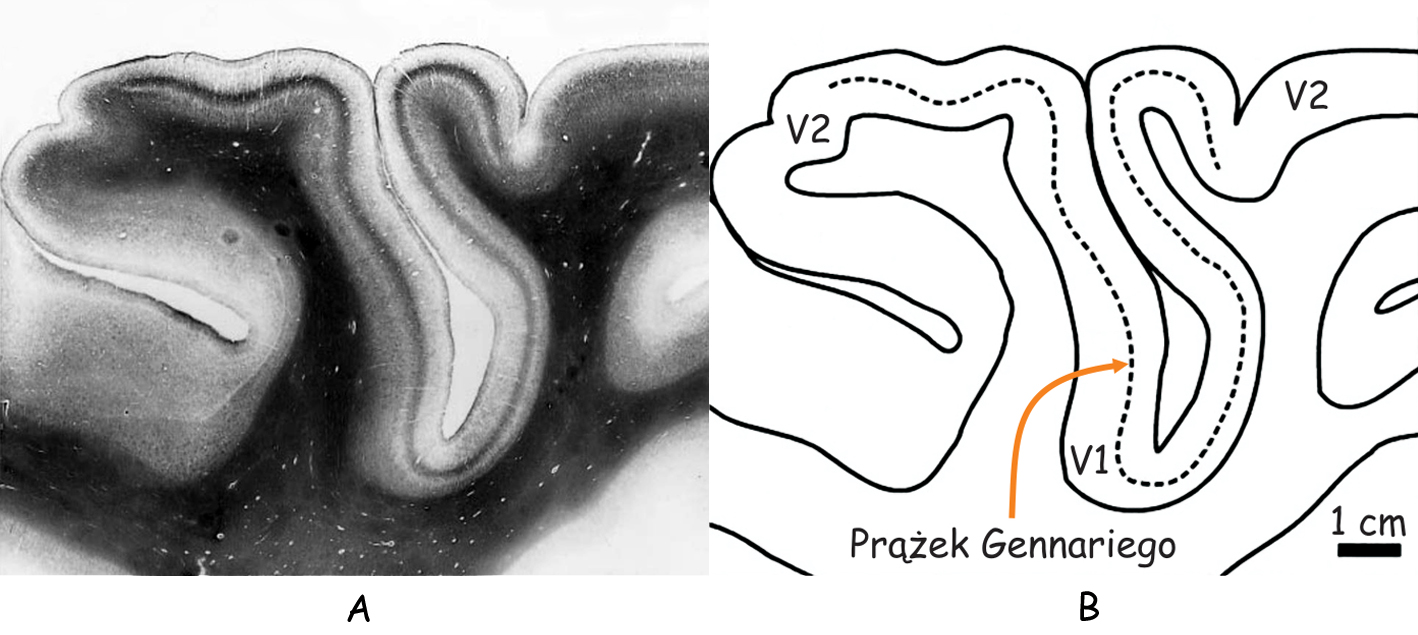
Żeby zrozumieć skąd się biorą prążki na powierzchni pierwszorzędowej kory wzrokowej trzeba zajrzeć do jej wnętrza przecinając ją w poprzek (ryc. 25). Na pierwszy rzut oka, na przekroju kory wzrokowej widać tylko trzy paski, dwa nieco jaśniejsze i jeden ciemniejszy znajdujący się między nim. Ten ciemniejszy zwany jest prążkiem Gennariego (stria of Gennari), od nazwiska jego odkrywcy, włoskiego studenta medycyny, Francesco Gennariego. Bez mikroskopu nie widać innych szczegółów budowy wewnętrznej pierwszorzędowej kory wzrokowej.
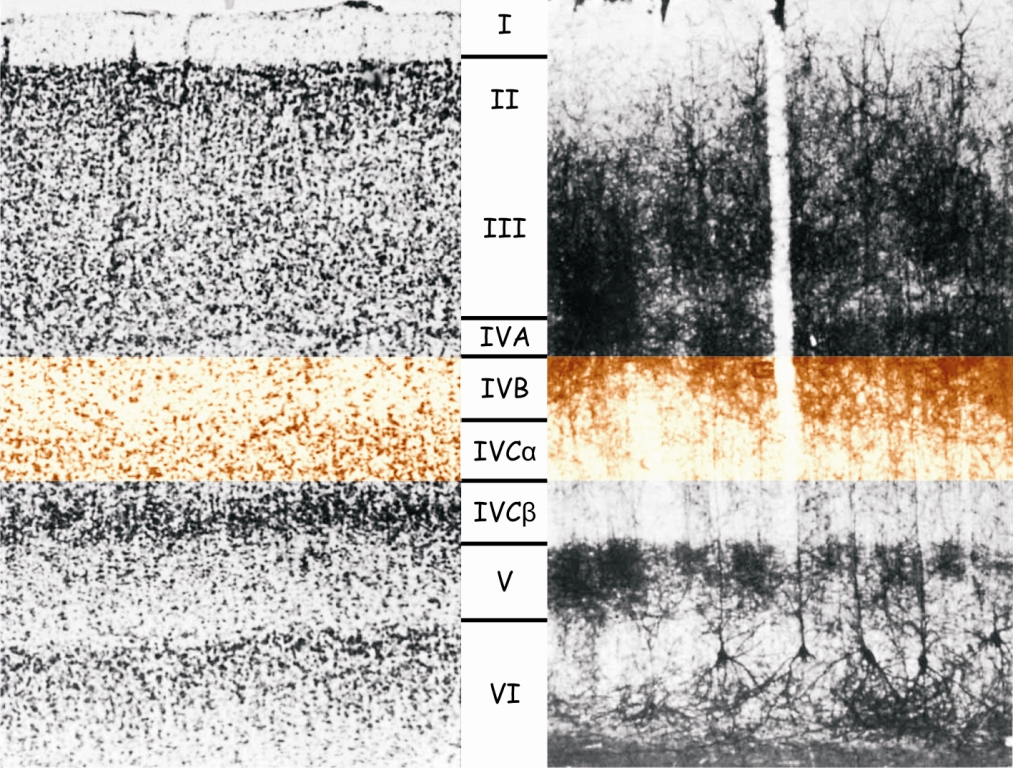
Jeśli jednak obejrzymy ją pod mikroskopem – a zwłaszcza po uprzednim wybarwieniu znajdujących się tam komórek – wówczas zobaczymy coś, co przypomina uporządkowaną strukturę warstw w LGN. Komórki w korze V1 są ułożone w 6 poziomych warstw, oznaczanych rzymskimi cyframi, od I do VI. Najszersza jest warstwa IV, która dzieli się jeszcze na cztery cieńsze warstwy: IVA, IVB, IVCα i IVCβ (ryc. 26).
Widoczny na ryc. 25 ciemny prążek Gennariego to właśnie fragment IV warstwy, a ściślej obszar, w którym znajdują się połączenia między warstwami IVB a IVCα. Warstwa IV pełni funkcję bramy wejściowej do kory wzrokowej mózgu. To przez nią, a zwłaszcza przez warstwy IVCα i IVCβ, docierają do pierwotnej kory wzrokowej impulsy nerwowe z LGN, a wcześniej z siatkówek obu oczu, za pośrednictwem promienistości wzrokowej. Dopiero z warstwy IV dane sensoryczne są rozsyłane dalej do komórek znajdujących się w innych warstwach kory V1.
Islamska architektura kory V1
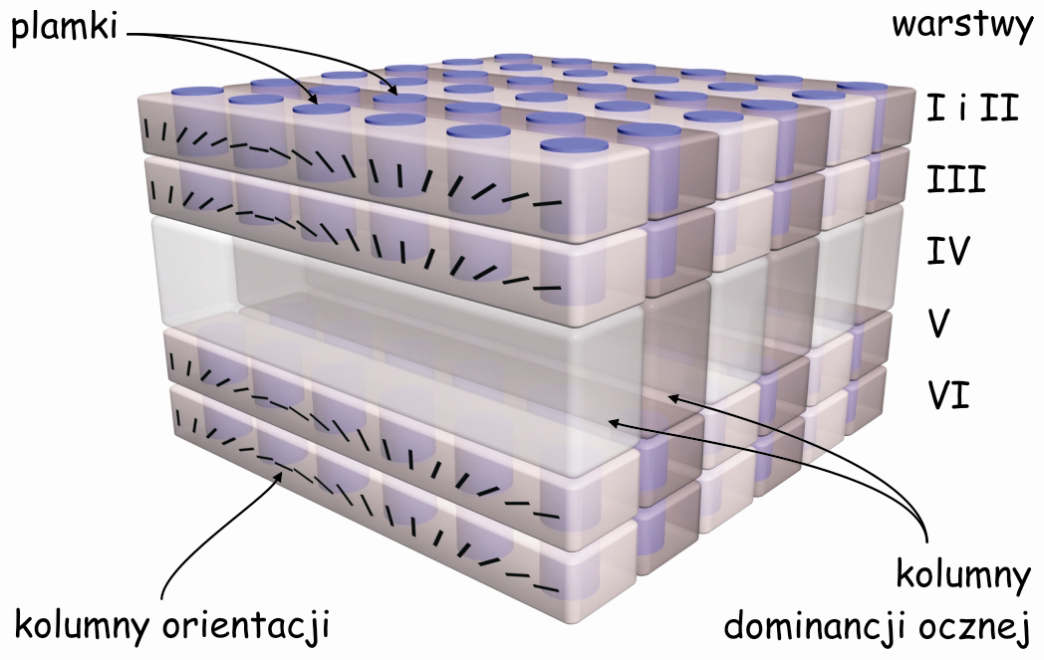
Następną ciekawostką związaną z budową pierwotnej kory wzrokowej jest to, że komórki, które tworzą poszczególne jej warstwy łączą się ze sobą w wyraźne kolumny. Dobrze je widać na zdjęciu wykonanym metodą Golgiego na ryc. 26. Drzewa dendrytyczne komórek znajdujących się w I warstwie są niczym głowice kolumn, których bazę stanowią komórki znajdujące się w warstwie VI, a trzon – komórki leżące w warstwach od II do V.
Patrząc na prążkowaną powierzchnię pierwotnej kory wzrokowej na ryc. 24 widzimy zatem tylko głowice poszczególnych kolumn. Jeżeli jednak zostaną wybarwione kolumny komórek, które odbierają impulsy nerwowe tylko z jednego oka, wówczas wszystkie głowice tych kolumn także przyjmą tę barwę, a na powierzchni kory wzrokowej zobaczymy ciemniejsze prążki (ryc. 27). Wskazują one na miejsca, gdzie w korze wzrokowej znajdują się rzędy komórek odbierających i przetwarzających sygnały z prawego lub lewego oka. Tworzą one coś w rodzaju kolumnad takich, jakie możemy podziwiać w Wielkim Meczecie w Kordobie. Tuż obok jednej kolumnady biegnie następny rząd neuronalnych kolumn, odbierających sygnały z drugiego oka itd.
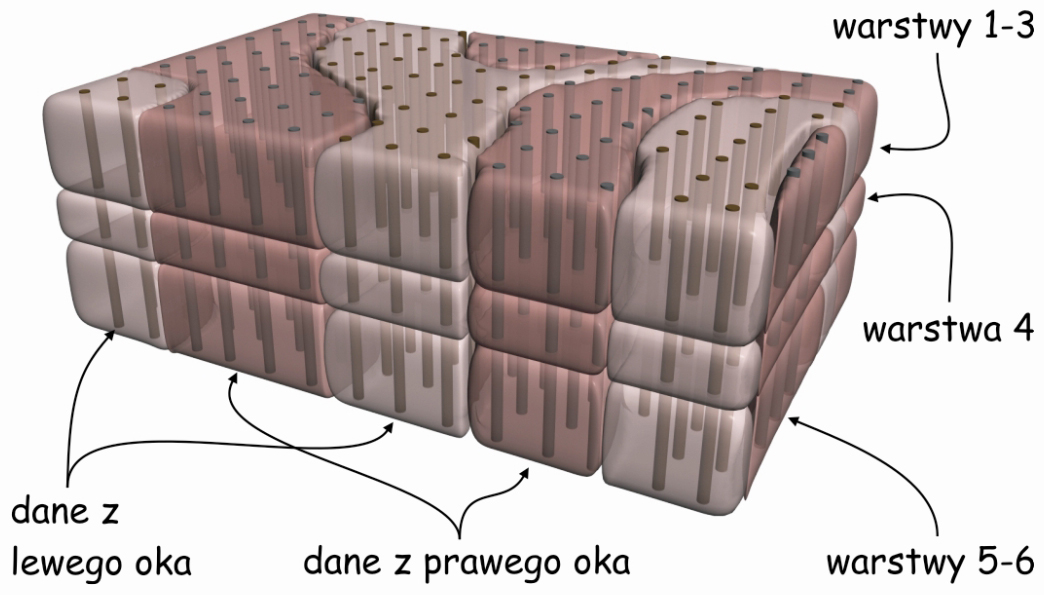
Zorientowane komórki
Odkrycie następnej własności pierwotnej kory wzrokowej zakończyło się przyznaniem Nagrody Nobla w 1981 roku dwóm neurofizjologom Davidowi Hubelowi i Torstenowi Wieselowi. Eksperymentując z korą wzrokową kota stwierdzili oni, że stojące obok siebie kolumny komórek, które reagują na dane płynące z jednego oka są wyspecjalizowane w zakresie orientacji przestrzennej fragmentów konturów rzeczy rejestrowanych przez to oko. Oznacza to, że wewnątrz kory V1 kolumny komórek są uporządkowane w dwóch płaszczyznach.
Jedną płaszczyznę wyznaczają komórki reagujące niezależnie od siebie na dane płynące z prawego i lewego oka. Z kolei druga płaszczyzna leży w poprzek tamtej i obejmuje komórki, które reagują na różne kąty, pod jakimi spostrzegany jest fragment konturu widzianej rzeczy, niezależnie od tego, za pomocą którego oka został on zarejestrowany. Opisując tę zdumiewającą strukturę pierwszorzędowej kory wzrokowej Hubel i Wiesel (1972) zaproponowali funkcjonalny model uporządkowania kolumn komórek w V1, znany jako model kostek lodu (ice-cube model) (ryc. 28).
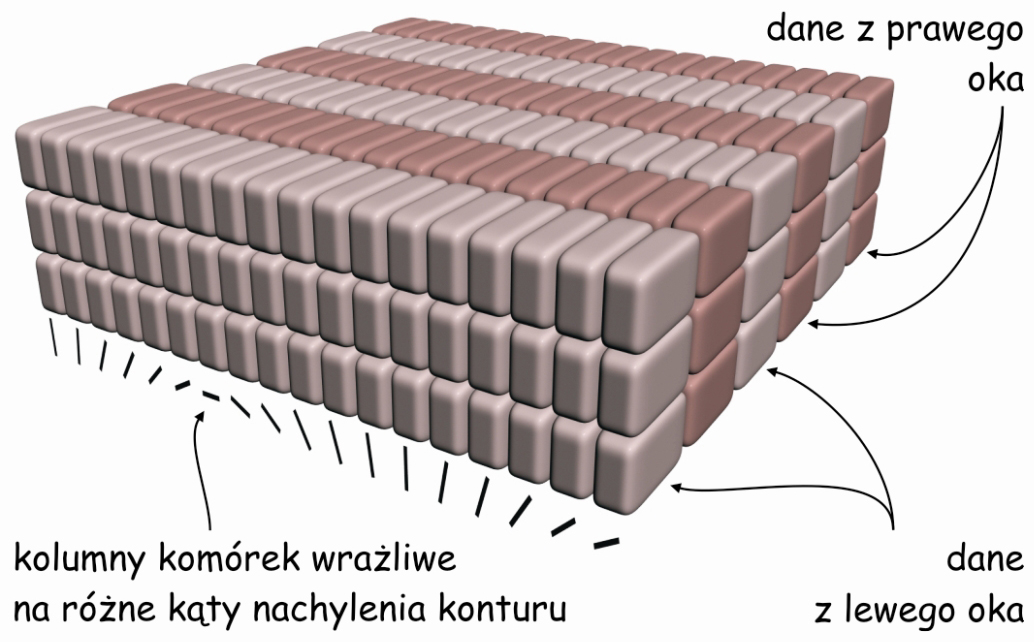
Oczywiście nie należy tego modelu traktować dosłownie, choćby z tego powodu, że – jak przekonaliśmy się oglądając powierzchnię kory V1 – rzędy kolumn neuronów reagujących na sygnały płynące z jednego lub drugiego oka bynajmniej nie są ułożone wzdłuż linii prostych. Tym niemniej model ten znakomicie ilustruje ogólną zasadę funkcjonalnego uporządkowania wewnętrznej struktury pierwotnej kory wzrokowej.
Otóż wygląda na to, że już na wstępnym etapie szlaku wzrokowego, obraz rzutowany na siatkówkę oka jest dzielony przestrzennie na tysiące małych kawałków. Każdy z tych kawałków zawiera informację o swoim położeniu na siatkówce oraz o orientacji krawędzi leżących na styku płaszczyzn różniących się ze względu na intensywność oświetlenia. W pierwotnej korze wzrokowej analizowana jest zawartość wszystkich tych kawałków i w zależności od miejsca na siatkówce oraz od orientacji zarejestrowanych krawędzi, aktywizowana jest określona grupa kolumn komórek. W ten sposób najprawdopodobniej kodowana jest informacja o kształtach rzeczy. Na dalszych etapach szlaku wzrokowego jest ona wykorzystywana do rekonstrukcji obiektów tworzących całą scenę wizualną.
Na pierwszy rzut oka może się wydawać czymś całkowicie irracjonalnym, żeby otrzymując na siatkówce oka kompletny obraz sceny wizualnej, system wzrokowy najpierw rozkładał go na czynniki pierwsze, a następnie z tych elementów składał go ponownie. Otóż po głębszym zastanowieniu musimy jednak dojść do wniosku, że trudno byłoby wymyśleć bardziej ekonomiczny system przetwarzania danych wzrokowych. Wystarczy tylko wziąć pod uwagę niewyobrażalną ilość danych dostarczanych do mózgu przez pobudzane czopki i pręciki w każdej sekundzie, gdy nasze oczy są otwarte. Innymi słowy złożoność i zmienność scen wizualnych w czasie wymagają od systemu wzrokowego podejścia systemowego, opartego na kilku czytelnych zasadach. Sprowadzają się one do analizy danych wzrokowych ze względu na najważniejsze własności zarówno sceny wizualnej, jak i urządzenia które je rejestruje, czyli siatkówki.
Jeżeli bowiem niezliczone kształty wszystkich widzianych rzeczy można wyznaczyć za pomocą różnic w jasności dwuwymiarowych płaszczyzn, na styku których zarysowuje się kontur kształtu, to nieporównywalnie łatwiej jest kodować te kształty za pomocą stosunkowo niewielkiej ilości komórek wrażliwych na orientację konturów w zakresie od 0 do 180o, niż za pomocą niemożliwej do oszacowania ilości komórek i ich połączeń, które pamiętałyby każdy kształt ze wszystkimi jego wyglądami. Chociaż i ten wariant jest „poważnie brany pod uwagę” przez mózg, również ze względów ekonomicznych.
Okazuje się bowiem, że nawet pojedyncze komórki mogą kodować kształty złożonych rzeczy, ale tylko tych, które są bardzo dobrze znane i silnie utrwalone w strukturach mózgu. Oczywiście nie w korze V1, tylko na dalszych etapach korowego szlaku wzrokowego. Są to tzw. komórki babcine (grandmother cells), które reagują wybiórczo na konkretne rzeczy lub ludzi (Gross, 2002; Kreiman, Koch i Fried, 2000; Quiroga, Kraskov, Koch i Fried (2009); Quiroga, Mukamel, Isham, Malach i in (2008). Warto w tym miejscu przypomnieć, że możliwość kodowania złożonych kształtów przez pojedyncze komórki odkrył i opisał już w latach 60. XX wybitny polski neurofizjolog, Jerzy Konorski (1967). Komórki te nazywał neuronami gnostycznymi (gnostic neurons). Zgodnie z jego koncepcją stanowiły one najwyższe piętro przetwarzania danych o kształtach widzianych rzeczy, rejestrowanych przez pole gnostyczne (gnostic fields), złożone z wielu komórek na wcześniejszych etapach szlaku wzrokowego.
Wracając do równie znakomitych odkryć Hubela i Wiesela warto dodać, że zidentyfikowali oni nie jeden, ale dwa rodzaje komórek tworzących kolumny w korze V1. Oprócz kolumn komórek uwrażliwionych na kąt nachylenia konturów, tzw. komórek prostych (simple cells), stwierdzili również obecność komórek, które reagują na kierunek ruchu. Są to tzw. komórki złożone (complex cells). W ramach niniejszej monografii, ruch rzeczy w scenie wizualnej nie będzie przedmiotem analizy, dlatego nie rozwijam tutaj tego wątku.
Retinotopowa mapa w korze prążkowej
Przedstawiony w poprzednim rozdziale opis niezwykłych własności pierwotnej kory wzrokowej bynajmniej nie jest jeszcze kompletny. Znając już nieco wewnętrzną budowę kory V1, wróćmy ponownie na jej powierzchnię. I tu czeka na nas kolejna niespodzianka.
Otóż, rzędy kolumn komórek, które odbierają sygnały z siatkówek prawego i lewego oka odzwierciedlają uporządkowanie znajdujących się w nich fotoreceptorów. Nie jest to odwzorowanie 1:1, ale znany jest algorytm pozwalający przewidzieć, które kolumny neuronów w pierwszorzędowej korze wzrokowej zareagują w odpowiedzi na stymulację określonej części siatkówki. Algorytm złożonej transformacji logarytmicznej (complex logarithm transformation) został opracowany przez Erica L. Schwartza (1980) na podstawie anatomicznej lokalizacji połączeń między komórkami zwojowymi, które zbierają informacje z różnych części siatkówki a różnymi częściami kory V1 w prawym i lewym płacie potylicznym (ryc. 29).
Z ryc. 29 wynika, że ok. 30% kolumn neuronów w pierwszorzędowej korze wzrokowej odbiera dane pochodzące z obszaru plamki żółtej, która obejmuje pole widzenia w zakresie do 5° (barwa żółta). Następna, trzecia część kolumn neuronów w V1 zajmuje się obszarem siatkówki między 5° a 20° pola widzenia (barwa czerwona) i wreszcie pozostałym obszarem siatkówki tj. między 20° a 90° pola widzenia, zajmuje się pozostała część neuronów kory w polu 17 (barwa zielona, jasno- i ciemnoniebieska).
Ponieważ – jak pamiętamy – najwięcej danych płynie wzdłuż aksonów komórek karłowatych i pyłkowych, czyli tzw. szlakiem drobnokomórkowym, dlatego w korze V1 najwięcej kolumn komórek odbiera właśnie te dane. Jeśli przypomnimy sobie jeszcze, że drobne komórki zwojowe obsługują przede wszystkim te okolice siatkówki oka, które znajdują się w okolicy dołka centralnego, wówczas stanie się zrozumiałe, że liczba kolumn komórek zajmujących się tym rodzajem danych jest niewspółmiernie większa niż liczba kolumn odbierających dane z pozostałych części siatkówki.
Jedno z pierwszych badań, w którym zarejestrowano reakcje komórek w korze V1 na bodziec wzrokowy zostało przeprowadzone przez Rogera Tootella i współpracowników na makakach (Tootell, Silverman, Switkes i de Valois, 1982). Zademonstrowali oni efekt odzwierciedlenia w korze V1, wzoru figury oglądanej przez małpę (ryc. 30). Warto dodać, że najwyraźniejsze odwzorowanie uzyskano w warstwie IVC. Jest to zrozumiałe, ponieważ to właśnie na tym poziomie sygnały z LGN docierają do V1.
Drugi przykład jeszcze wyraźniej ilustruje, jak wiele już wiemy na temat retinotopowej organizacji kory V1 nie tylko u makaków, ale również u człowieka i jej aktywności podczas widzenia. W badaniach, na które chciałbym zwrócić uwagę, reakcję kory wzrokowej człowieka rejestrowano za pomocą skanera fMRI 7T (Polimeni, Fischl, Greve i Wald, 2010). Tym razem osoba badana oglądała na ekranie komputera literę „M”, w dwóch wersjach: pozytywowej i negatywowej (ryc. 31B). Jej kształt został odpowiednio przetworzony za pomocą wspomnianego już algorytmu Schwartza, który określa zależności przestrzenne między obrazem rzutowanym na połowę siatkówki oka (visual hemifield), a jej odzwierciedleniem na powierzchni kory wzrokowej (cortical surface; ryc. 31 A).

Eksponując zniekształcony bodziec wzrokowy zamierzano sprawdzić, w jakim stopniu kolumny neuronów, które są wrażliwe na różne kąty konturów powstających na styku kontrastujących ze sobą powierzchni, trafnie odzwierciedlą kształt litery „M”. Podczas fiksowania wzroku przez badanych na środkowym, czerwonym punkcie, mierzono aktywność neuronów w korze V1 i stwierdzono, że na poziomie warstwy IVC całkiem przyzwoicie odzwierciedla się obraz litery „M” (ryc. 32 C; niebieski kształt).
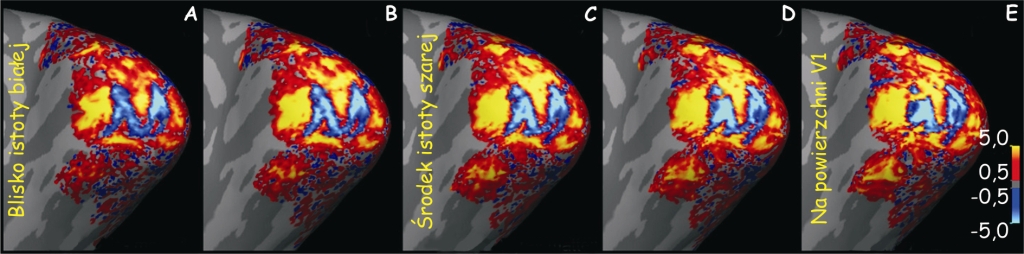
Nie trzeba chyba nikogo przekonywać, jak ogromne możliwości otwierają te odkrycia w zakresie przywracania możliwości widzenia osobom, które utraciły wzrok, w wyniku choroby lub mechanicznego uszkodzenia siatkówek oczu. Zamiast danych wysyłanych przez fotoreceptory znajdujące się w siatkówkach oczu do kory V1, można wysłać do niej sygnał bezpośrednio z kamery wideo. Po jego przetworzeniu za pomocą algorytmu Schwartza oraz stymulowaniu nim komórek w pierwszorzędowej korze wzrokowej za pomocą elektrod można doprowadzić do powstania doświadczenia widzenia. Wiele wskazuje na to, że to już nieodległa przyszłość.
I jeszcze kilka zdań o plamkach i barwach
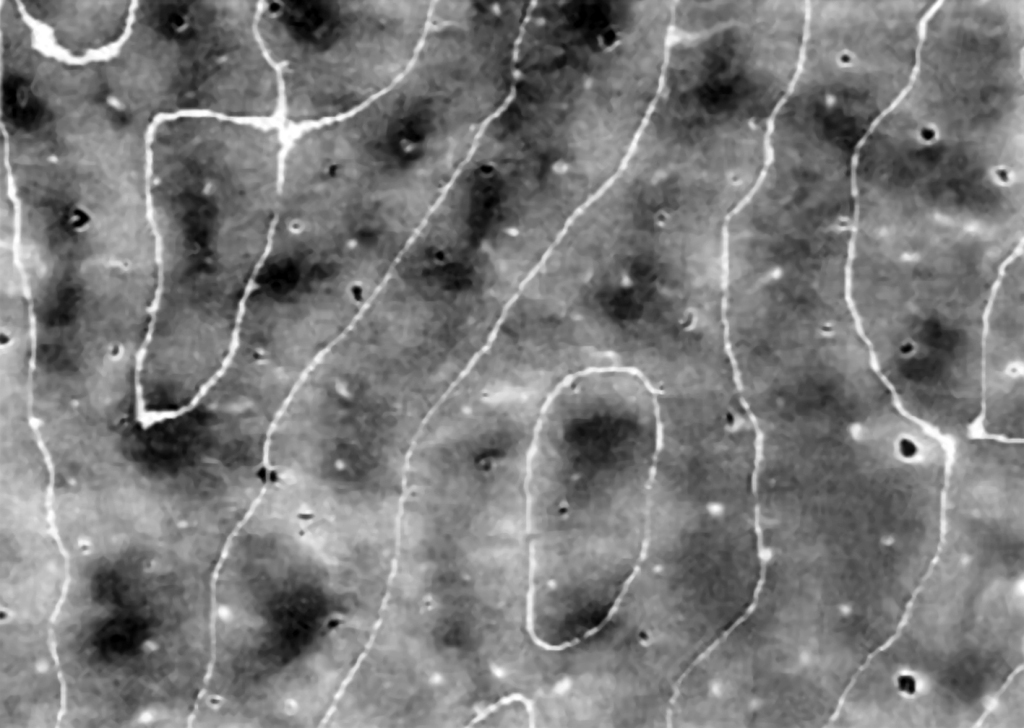
Omawiając budowę i funkcje pierwszorzędowej kory wzrokowej nie można pominąć jeszcze jednego elementu. Otóż pomiędzy kolumnami komórek, które oddzielnie z jednego i z drugiego oka odbierają informacje o orientacji przestrzennej fragmentów konturów, znajdują się niewielkie, cylindryczne skupiska neuronów, które pełnią ważną funkcję, m.in. w percepcji barw (Livingstone i Hubel, 1984). Występują one w zasadzie we wszystkich warstwach kory wzrokowej, za wyjątkiem warstwy IV (ryc. 33).
W polskim tłumaczeniu angielskojęzycznej nazwy „blobs”, określa się je jako „kropelki”, „plamki”, a nawet „kleksy” (Matthews, 2000), natomiast rzadziej używa się oryginalnej nazwy tej struktury, odkrytej przez Jonathana C. Hortona i Davida Hubela (1981), tj. patches, czyli łaty. Nazwy te pochodzą stąd, że po przecięciu wzdłuż kory V1 i wybarwieniu jej za pomocą metody oksydazy cytochromowej, na jej powierzchni można dostrzec dość nieregularnie rozmieszczone plamki znajdujące się między kolumnami komórek, które reagują na orientację krawędzi widzianych rzeczy (ryc. 34).
Wejścia i wyjścia z kory V1
Domykając wycieczkę w głąb pierwotnej kory wzrokowej warto uporządkować wiedzę dotyczącą jej połączeń z innymi strukturami mózgu. Przede wszystkim wiadomo, że do kory V1 najwięcej danych dociera z LGN szerokim traktem, zwanym promienistością wzrokową. Aksony komórek tworzących promienistość wzrokową łączą się z komórkami kory V1 na poziomie warstwy IV. Aksony te tworzą trzy ścieżki wzrokowe: wielko- drobno- i pyłkokomórkową.
Ścieżka wielkokomórkowa łączy się z korą V1 na poziomie warstwy IVCα i przenosi dane dotyczące jasności fragmentów sceny wizualnej. Nie są one kodowane z tak wysoką rozdzielczością, jak dane płynące po ścieżce drobnokomórkowej, ale za to obejmują znacznie większe obszary widzianej sceny. Dane te stanowią podstawę globalnej organizacji przestrzennej obiektów znajdujących się w wykadrowanej scenie. Ponadto, po ścieżce wielokomórkowej płyną sygnały, które stanowią podstawę widzenia ruchu. Zarówno percepcja globalnej organizacji przestrzennej wewnątrz sceny wizualnej, jak i percepcja jej zmienności, związanej z ruchem znajdujących się w niej obiektów i ruchem obserwatora, są kluczem do naszej orientacji w przestrzeni. Dane biegnące z warstwy IVCα po ścieżce wielokomórkowej trafiają do sąsiadującej z nią warstwy IVB. Stąd są one wysyłane w dwóch kierunkach: do kory V2 oraz do kory V5, zwanej również obszarem przyśrodkowym skroniowym (medial temporal area; MT), który specjalizuje się w przetwarzaniu danych dotyczących ruchu w scenie wizualnej (ryc. 35).
Bogata w aksony ścieżka drobnokomórkowa łączy się z V1 na poziomie warstwy IVCβ. Przenosi ona dwa rodzaje informacji: o długości i intensywności fali świetlnej pobudzającej różne grupy czopków w siatkówce, czyli o barwie i o luminancji. Dane te charakteryzują się z jednej strony wysoką rozdzielczością przestrzenną, a z drugiej, są ograniczone do stosunkowo niewielkiego fragmentu pola widzenia. Informacja o długości fali świetlnej, zwłaszcza w zakresie opozycji barwy czerwonej i zielonej, jest kierowana z warstwy IVCβ do skupisk neuronów tworzących plamki, a stamtąd do kory V2. Z kolei informacja o intensywności oświetlenia, która stanowi fundament widzenia konturów płynie z warstwy IVCβ, wzdłuż kolumn wrażliwych na określone kąty fragmentów konturów (zwłaszcza w warstwach II i III), i stąd także jest wyprowadzana do kory V2.
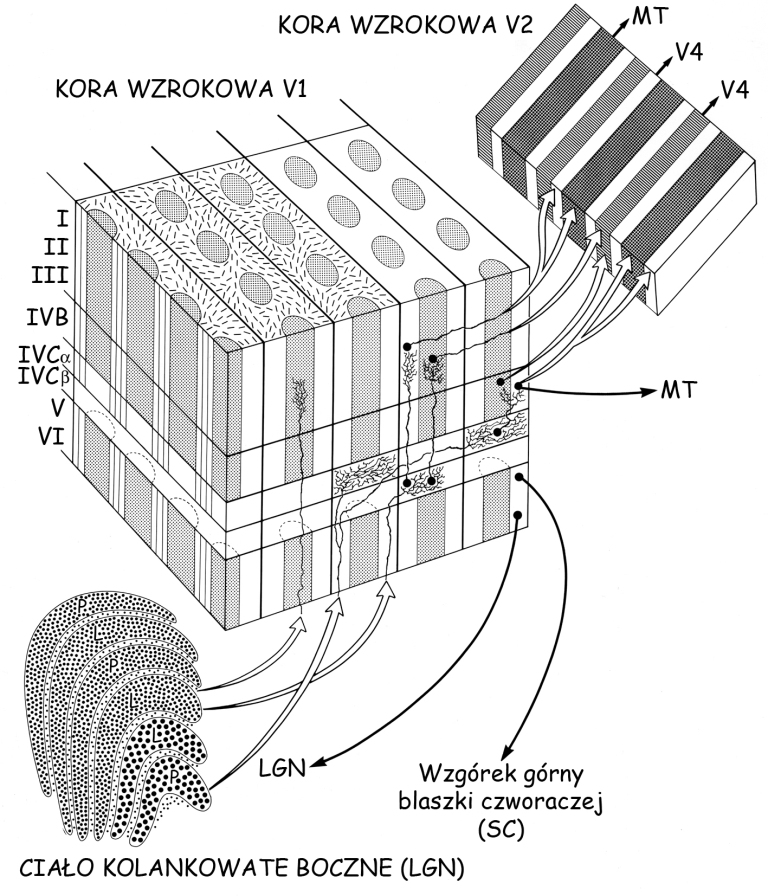
Nieco inaczej jest ze szlakiem pyłkokomórkowym, który w korze V1 łączy się bezpośrednio ze skupiskami neuronów tworzących walcowate plamki, bez pośrednictwa kolumn w warstwie IV. Po ścieżce pyłkokomórkowej przenoszone są dane w zakresie opozycji barwy niebieskiej i żółtej. Z plamek płyną one dalej w kierunku kory V2.
Kora V2
Zdecydowana większość danych docierających do kory V1 z siatkówki przez LGN jest przekazywana dalej do kory V2 lub, według klasyfikacji Brodmanna – pola 18. Podobnie, jak V1 składa się ona z leżących obok siebie struktur komórkowych o różnej budowie anatomicznej. Po ich wybarwieniu można je łatwo od siebie odróżnić, ponieważ tworzą charakterystyczne prążki (ryc. 36). W korze V2 można wyróżnić zasadniczo trzy rodzaje prążków: cienkie (thin stripes), grube (thick stripes), które wybarwiają się na ciemno i tzw. regiony międzyprążkowe (pale stripes), które podczas wybarwiania pozostają jasne (Matthews, 2000). Prążki układają się w tym samym rytmie wzdłuż całej kory V2, czyli: cienki – międzyprążkowy – gruby – międzyprążkowy – cienki – międzyprążkowy, itd.
Ponad połowa komórek w korze V2 reaguje niemal identycznie, jak komórki w V1 (Willmore, Prenger i Gallant, 2010). Najprawdopodobniej oznacza to, że przetwarzają one dane dotyczące prostych cech sceny wizualnej, m.in. takich jak fragmenty krawędzi, ich orientacje, kierunek ruchu i barwy (Sit i Miikkulainen, 2009). Komórki te nie są już jednak zorganizowane topograficznie, tak jak w korze V1. Druga połowa komórek V2 zajmuje się bardziej złożonymi cechami sceny wizualnej. Między innymi są one aktywne w odpowiedzi na kontury iluzoryczne lub kontury definiowane przez fakturę powierzchni (von der Heydt, Peterhans i Baumgartner, 1984; von der Heydt i Peterhans, 1989), a także na skomplikowane kształty i ich orientację (Hegdé i van Essen, 2000; Ito i Komatsu, 2004; Anzai, Peng i van Essen, 2007).
Każdy z trzech rodzajów prążków odbiera inne dane z V1, zgodnie z wielokrotnie już sygnalizowanym podziałem ścieżek wzrokowych na trzy rodzaje ze względu na ich funkcje. I tak, dane z obszarów plamkowych w V1 są przekazywane do komórek tworzących cienkie prążki w V2. W prążkach tych zanikają już anatomiczne różnice między komórkami tworzącymi drobno- i pyłkokomórkową ścieżkę, natomiast dochodzi do integracji wszystkich danych, które stanowią podstawę widzenia barw. Innymi słowy, neurony tworzące cienki prążek w korze V2 są wyspecjalizowane w zakresie organizacji danych o różnych długościach fali elektromagnetycznej tworzącej całe spektrum światła widzianego. Dane te są dalej przekazywane zarówno bezpośrednio, jak i za pośrednictwem kory V3 do kory V4, zwanej korowym ośrodkiem widzenia barw (DeYoe i van Essen, 1985; Shipp i Zeki, 1985; van Essen, 2004). Derrik E. Asher i Alyssa A. Brewer (2009), na podstawie wyników badań fMRI sugerują, że w zakresie przetwarzania barw w polu V4 są istotne różnice międzypółkulowe. Otóż okazuje się, że w prawostronnym korowym ośrodku widzenia barw neurony są znacznie bardziej wrażliwe na bodźce chromatyczne niż achromatyczne, natomiast w polu V4 znajdującym się z lewej strony nie stwierdzono różnic w aktywności neuronów na bodźce chromatyczne i achromatyczne.
Wysokorozdzielcze widzenie kształtów na podstawie kontrastów w zakresie luminacji ma swoje źródło – jak pamiętamy – w danych przekazywanych za pośrednictwem ścieżki drobnokomórkowej, które z kolumnad w V1 trafiają do regionów międzyprążkowych w V2. To jedna z najważniejszych struktur w korze wzrokowej, której aktywność stanowi podstawę organizacji danych umożliwiających rozpoznawanie kształtów rzeczy w scenie wizualnej. Dane z obszarów międzyprążkowych w V2 również trafiają do V4.
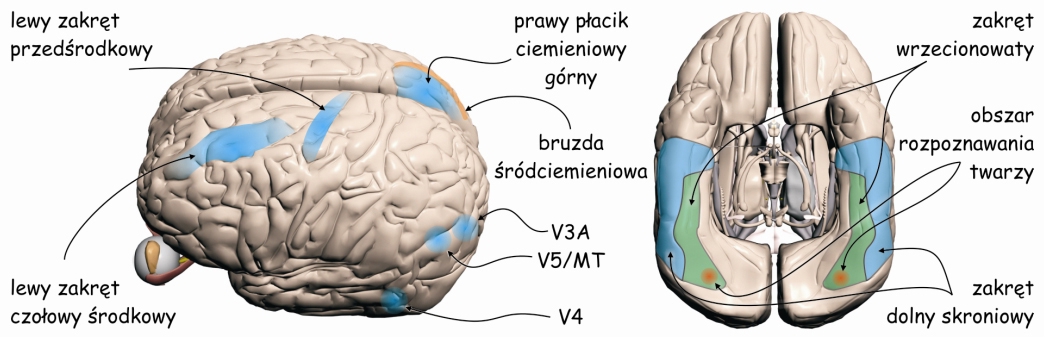
Integracją danych dotyczących kształtów widzianych rzeczy zajmują się te struktury mózgu, które odbierają projekcje z V4, czyli zakręt dolny skroniowy (inferior temporal gyrus; IT) oraz zakręt wrzecionowaty (fusiform gyrus), ze szczególnym miejscem zwanym obszarem rozpoznawania twarzy (fusiform face area; FFA) (ryc. 37).
Trzecim rodzajem prążków w korze V2 są prążki ciemne i grube. Tu z V1 docierają dwie kategorie danych: dotyczące przestrzennej organizacji sceny wizualnej i ruchu. Dane o globalnej organizacji przestrzennej umożliwiają zarówno stwierdzenie obecności takich czy innych obiektów w scenie wizualnej (stanowią więc również podstawę widzenia ich kształtów), jak również ich rozmieszczenia względem siebie. Ze względu na stosunkowo niską rozdzielczość, dane te pełnią funkcję ogólnie orientującą w przestrzeni i – w zależności od sytuacji – stanowią impuls do skierowania uwagi i dokładniejszą analizę na wybranych fragmentach sceny przez systemy odpowiedzialne za widzenie wysokorozdzielcze. Sygnały kodujące informacje dotyczące globalnej orientacji przestrzennej są kierowane do kory V3.
Z kolei druga kategoria danych płynących z V1 do grubych, ciemnych prążków w V2 stanowi podstawę doświadczenia widzenia ruchu. Stąd są one wyprowadzane do wspomnianego już obszaru MT, czyli kory V5 i dalej V3A, będących korowym ośrodkiem percepcji ruchu (Roe i Ts’o, 1995; Shipp i Zeki, 1989) (ryc. 37).
Ścieżka brzuszna i grzbietowa
Oprócz integrowania danych docierających z V1, kora V2 stanowi także niezwykle ważny węzeł na szlaku wzrokowym, w którym biorą początek dwie nowe, częściowo niezależne od siebie ścieżki wzrokowe: brzuszna (ventral path) i grzbietowa (dorsal path) (Milner i Goodale, 2008). Swoje nazwy biorą one od umiejscowienia w korze mózgu. Gdybyśmy przedstawili sobie mózg, jako zwierzę, np. rybę, to struktury leżące na jej górnej powierzchni, czyli płaty ciemieniowe kojarzyły by się z grzbietem, a struktury znajdujące się w dolnej części (np. płaty skroniowe) – z brzuchem (ryc. 38). I tak właśnie jest z nazwami tych szlaków. Podobnie, jak podkorowe ścieżki wielko‑, drobno- i pyłkokomórkowe, leżące na wcześniejszych etapach szlaku wzrokowego, również obie ścieżki korowe (brzuszna i grzbietowa) różnią się od siebie pod względem anatomicznym i funkcjonalnym.
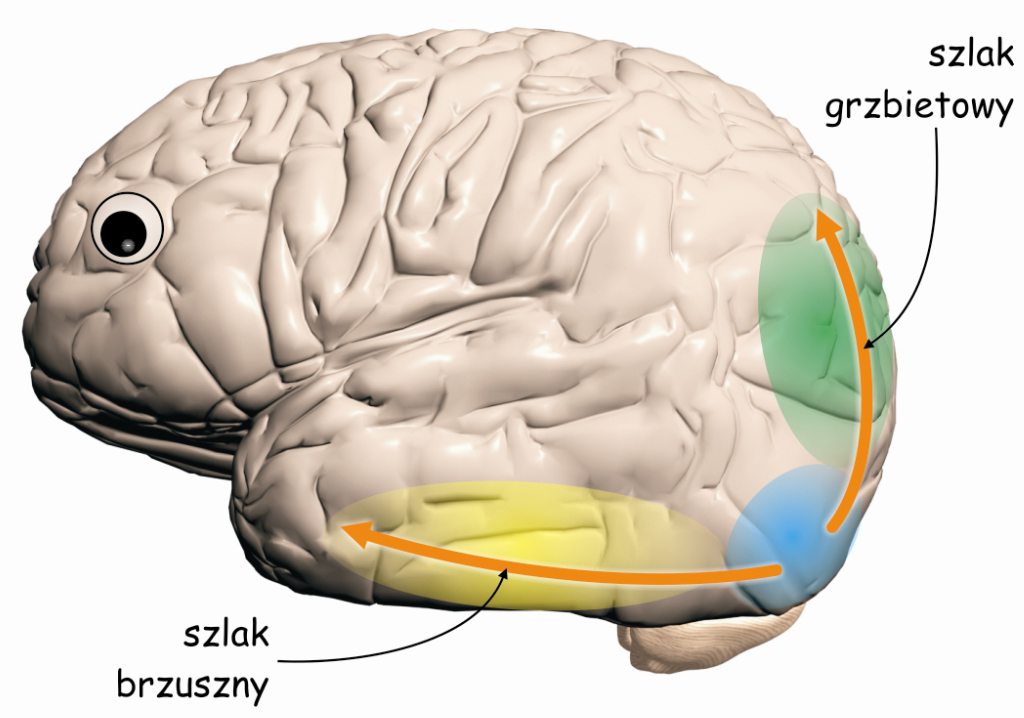
Historia odkrycia tych dwóch szlaków wzrokowych sięga lat 80. ubiegłego stulecia. W 1982 roku Leslie G. Ungerleider i Mortimer Mishkin opublikowali wyniki badań nad aktywnością kory mózgowej rezusów, podczas wykonywania przez nie zadań wymagających, albo różnicowania przedmiotów, albo ich lokalizacji za pomocą wzroku. Oczywiście w tych czasach nie stosowano jeszcze skanerów magnetycznych do lokalizacji aktywności różnych części mózgu podczas wykonywania przez badanych jakiegoś zadania. Hipotezy dotyczące funkcji takiej czy innej części mózgu testowano w ten sposób, że operacyjnie usuwano z mózgu małpy obszar, o którym sądzono, że ma jakieś znaczenie dla poprawnego wykonania określonego zadania, a następnie – oczywiście po okresie rekonwalescencji – małpa wykonywała to zadanie. Jeśli wykonywała je gorzej lub wcale w porównaniu do tych małp, których mózgi nie zostały uszkodzone, wówczas uznawano, że usunięta część jest odpowiedzialna za poprawne wykonanie tego zadania. W ten właśnie sposób Ungerleider i Mishkin ustalili, że jeżeli uszkodzeniu uległa skroniowa część mózgu obejmująca okolice V4 i IT, wówczas małpy miały poważne problemy z prawidłowym rozpoznawaniem znanych sobie przedmiotów, ale całkiem nieźle radziły sobie z zadaniami wymagającymi od nich lokalizacji przedmiotów w przestrzeni. Z kolei małpy z uszkodzeniem płatów ciemieniowych, zwłaszcza w okolicach kory V5/MT, nie potrafiły wykorzystywać wskazówek przestrzennych, natomiast bez trudu rozpoznawały znane przedmioty (Mishkin, Ungerleider i Macko, 1983; Ungerleider, 1985).
Wyniki swoich badań Ungerleider i Mishkin (1982) zawarli w koncepcji, zgodnie z którą dane docierające do kory V2 z centralnych części siatkówek oczu za pośrednictwem ścieżek drobno- i pyłkokomórkowej są przekazywane w kierunku płata skroniowego i stanowią podstawę identyfikacji i rozpoznawania przedmiotów w scenie wizualnej. Z kolei dane płynące po szlaku wielkokomórkowym (czyli z peryferyjnych części siatkówek oczu) są przekazywane w kierunku płata ciemieniowego i stanowią podstawę lokalizacji przedmiotów w tej scenie.
Pierwsza droga została umownie nazwana drogą typu „co”, ponieważ aktywizacja struktur mózgu, które znajdują się wzdłuż tego szlaku pozwala na rozpoznanie przedmiotu, a w szczególności jego kształtu i barwy, czyli prowadzi do odpowiedzi na pytanie: „co to jest?”. Z kolei druga droga została nazwana drogą typu „gdzie”, ponieważ tworzące ją struktury mózgu są aktywne wówczas, gdy zadanie poznawcze wymaga orientacji przestrzennej w odniesieniu do przedmiotów znajdujących się w scenie wizualnej, czyli prowadzi do odpowiedzi na pytanie: „gdzie się to coś znajduje?”.
Dziesięć lat później, Melvyn A. Goodale i A. David Milner (1992) zaproponowali alternatywną koncepcję funkcji obu szlaków wzrokowych. Zasadniczo nie zakwestionowali oni poglądu, zgodnie z którym szlak brzuszny „zajmuje się” takimi własnościami sceny wizualnej, jak kształt i barwa przedmiotów znajdujących się w scenie. Według nich struktury mózgu aktywne na szlaku brzusznym rzeczywiście stanowią podstawę rozpoznawania przedmiotów spostrzeganych w scenie wizualnej na podstawie zarejestrowanych danych sensorycznych dotyczących rozkładu jasności i barw, w tym również tak złożonych obiektów, jak np. twarz ludzka.
Najważniejsza modyfikacja koncepcji Ungerleider i Mishkina dotyczyła natomiast funkcji szlaku grzbietowego. Zdaniem Goodale’a i Milnera, aktywizacja struktur mózgu tworzących ten szlak pozwala obserwatorowi nie tyle orientować się w przestrzeni i rozkładzie widzianych przedmiotów w scenie, ale przede wszystkim pozwala mu kontrolować własne działania podejmowane w tej przestrzeni.
Do takiego wniosku doszli oni obserwując zachowanie pacjentki, znanej pod inicjałami D.F., która cierpiała na tzw. agnozję wzrokową, czyli niezdolność do rozpoznawania widzianych przedmiotów. Źródłem jej problemów były rozległe uszkodzenia struktur mózgu w obrębie szlaku brzusznego. Najbardziej zdumiewające było to, że chociaż D.F. miała znaczne trudności w rozpoznawaniu przedmiotów, to potrafiła się nim całkiem nieźle posługiwać, wykonując precyzyjne zadania motoryczne i ruchowe. Za realizację tych zadań jest bowiem odpowiedzialny szlak grzbietowy, który u tej pacjentki nie był uszkodzony. Szczegółowy opis przypadku pacjentki D.F. oraz wykład swojej koncepcji szlaków wzrokowych Milner i Goodale przedstawili w książce wydanej w 1995 roku (polskie tłumaczenie zostało opublikowane w 2008 roku na podstawie II wydania angielskojęzycznego z roku 2006).
Podsumowując, w ujęciu Ungerleider i Mishkina, szlak grzbietowy pozwala obserwatorowi poznawczo uchwycić lokalizację i relacje przestrzenne między przedmiotami w scenie wizualnej. Ów obserwator przypomina widza oglądającego film 3D w kinie, w którym przestrzeń przedstawia mu się w całej złożoności, a on na bieżąco ujmuje związki między widzianymi obiektami. Z kolei, zgodnie z sugestią Goodale’a i Milnera, wzrokowa orientacja w przestrzeni możliwa dzięki aktywności struktur mózgowych leżących na szlaku grzbietowym jest tylko punktem wyjścia do kontroli własnego działania podejmowanego w tej przestrzeni. Tak rozumiana funkcja szlaku grzbietowego, z biernego obserwatora sceny wizualnej, wobec której zajmuje on pozycję zewnętrzną (np. kinomana), czyni zeń aktora, znajdującego się wewnątrz oglądanej sceny (np. alpinistę). Co więcej, w oglądanej przestrzeni ów aktor zajmuje pozycję centralną (egocentryczną), a wszystkie relacje między oglądanymi rzeczami są relatywizowane do zajmowanego przezeń miejsca w tej przestrzeni oraz do zadań motorycznych, jakie ma on do wykonania.
Integracja danych z obu szlaków wzrokowych
Byłoby dziwne, gdyby dwa omówione szlaki wzrokowe działały w całkowitej izolacji od siebie. Doświadczenia z pacjentką D.F. pokazały, że uszkodzenia szlaku brzusznego, skutkujące niezdolnością do rozpoznawania przedmiotów za pomocą wzroku, nie zaburzają zdolności do manipulacji tymi przedmiotami. Tym niemniej coraz więcej danych wskazuje również na to, że obydwa szlaki są ze sobą skomunikowane, a wyniki ich aktywności integrowane, tworząc subiektywne doświadczenie wieloaspektowego kontaktu z obiektem.
Mark R. Pennick i Rajesh K. Kana (2011) poprosili osoby badane, żeby wykonywały dwa rodzaje zadań. Jedno polegało na rozpoznawaniu i nazywaniu prezentowanych przedmiotów, a drugie na określaniu ich położenia. Podczas wykonywania zadań rejestrowano aktywność ich mózgów za pomocą funkcjonalnego rezonansu magnetycznego (fMRI). Zgodnie z oczekiwaniem okazało się, że podczas wykonywania zadań rozpoznawania szczególnie aktywne były struktury leżące wzdłuż szlaku brzusznego, a podczas wykonywania zadań na lokalizację – wzdłuż szlaku grzbietowego. Badaczy interesowało jednak to, czy są takie struktury mózgu, które są aktywne niezależnie od tego, które zadanie było wykonywane. Okazało się, że jest kilka takich struktur, które najprawdopodobniej integrują dane pochodzące z obu szlaków wzrokowych. Są one zlokalizowane zwłaszcza w płacie czołowym, takie jak lewy zakręt czołowy środkowy (left middle frontal gyrus, LMFG) i lewy zakręt przedśrodkowy (left precentral gyrus, LPRCN), a także w płacie ciemieniowym: prawy płacik ciemieniowy górny (right superior parietal lobule, RSPL) i leżąca tuż pod nim bruzda śródciemieniowa (intraparietal sulcus; IPS (ryc. 37).
Wszystkie te struktury tworzą rodzaj sieci asocjacyjnej, zbierającej dane z różnych źródeł a następnie kompilującej je do takiej postaci, którą odczuwamy, już nie tylko jako doświadczenie widzenia, ale także jako doświadczenie istnienia rzeczy w świecie, w którym żyjemy. Wyniki badań Pennick i Kana potwierdzają wcześniejsze doniesienia dotyczące funkcji wymienionych struktur mózgu (Buchel, Coull i Friston, 1999; Clayes, Dupont, Cornette, Sunaert i in., 2004; Jung i Haier, 2007; Schenk i Milner, 2006).
SYSTEM KADROWANIA SCENY WIZUALNEJ
Kadr, czyli zakres pola widzenia
Wiemy już z grubsza, w jaki sposób jest zbudowany siatkówkowy ekran, na którym światło wpadające do oka odzwierciedla scenę wizualną. Wiemy również trochę na temat układu optycznego oka. Warto zatem uzmysłowić sobie, jaki jest kształt i wielkość pola widzenia, czyli – przywołując znowu metaforę aparatu fotograficznego – jaki jest rozmiar pojedynczego kadru, ograniczonego ramami naświetlanego pola.
W fotografii mówi się o kącie widzenia obiektywu (field of view; FOV), co oznacza kąt między najbardziej oddalonymi od siebie punktami świetlnymi w płaszczyźnie horyzontalnej lub wertykalnej na matrycy światłoczułej, zarejestrowanymi za pomocą obiektywu o określonej ogniskowej. I tak, np. kąt widzenia obiektywu o ogniskowej 50 mm rejestruje obraz na matrycy lub klatce filmowej o wymiarach 24 x 36 mm w zakresie 40° w płaszczyźnie horyzontalnej i 27° w płaszczyźnie wertykalnej.
Koncepcja pola widzenia (field of vision) za pomocą oczu jest analogiczna do pojęcia kąta widzenia obiektywu. Pole widzenia oznacza obszar rejestrowany przez nieruchome oko w unieruchomionej głowie. W płaszczyźnie horyzontalnej wynosi on 150–160° (60–70° w części przynosowej i ok. 90° w części skroniowej), a w płaszczyźnie wertykalnej ok. 130° (50–60° powyżej osi widzenia i 70–80° poniżej osi widzenia) (ryc. 39).
Zakres pola widzenia oka jest znacznie mniej regularny niż prostokątny kształt matrycy fotograficznej. Różnicę w zakresie kształtu i wielkości obu pól widzenia (oka i aparatu fotograficznego) ilustruje ryc. 40. Przedstawia ona schematycznie kształt siatkówki prawego oka, która jest rzutowana na powierzchnię kuli, z zaznaczonym zakresem pola widzenia osoby poddanej badaniu perymetrycznemu. Celem takiego badaniajest wyznaczenie obrysu pola widzenia nieruchomego oka we wszystkich możliwych kierunkach.
Na centralną część siatkówki oka naniosłem zarys małoobrazkowego kadru o wymiarach 24 mm x 36 mm, naświetlanego w aparacie fotograficznym z obiektywem o ogniskowej 50 mm (zaznaczony na pomarańczowo). Pokrywa on niewielką część całego pola widzenia. Jak pamiętamy w odległości ok. 20° pola widzenia od dołka centralnego w każdym kierunku liczba czopków na siatkówce radykalnie się zmniejsza. Oznacza to, że 50-milimetrowy obiektyw znakomicie pokrywa tę część pola widzenia, która charakteryzuje się największą rozdzielczością i najwyższą wrażliwością na różnicowanie długości fali elektromagnetycznej w zakresie światła widzialnego. Z tego względu obiektyw o takiej ogniskowej nazywany jest standardowym.
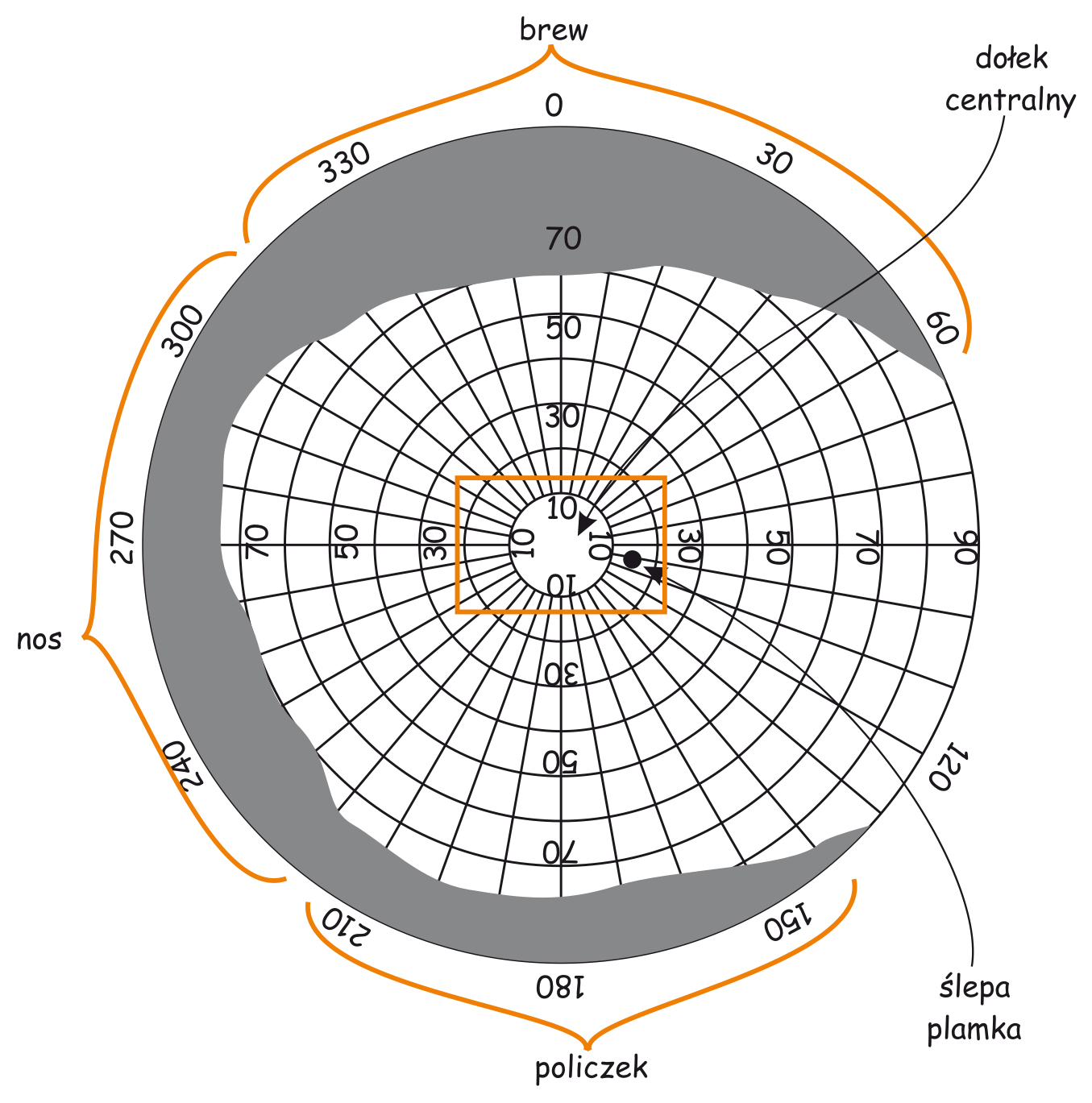
Ponieważ na ogół oglądamy rzeczy za pomocą dwojga oczu (stereoskopowo), zatem nie od rzeczy będzie dołączenie ilustracji zakresu obuocznego pola widzenia (ryc. 41). W płaszczyźnie wertykalnej niewiele się zmienia, ale znacznie poszerza się pole widzenia w płaszczyźnie horyzontalnej do, co najmniej, 180°. Na ten wykres także naniosłem małoobrazkowy kadr odpowiadający zakresowi widzenia obiektywu 50-milimetrowego (zaznaczony na czerwono), jak również szerokokątnego obiektywu o ogniskowej 13 mm, który pozwala na fotografowanie dużych obiektów z małych odległości (zaznaczony na zielono). Dopiero szerokokątny obiektyw o tak niewielkiej ogniskowej pokrywa większą część pola widzenia człowieka, który ogląda scenę za pomocą dwojga oczu.
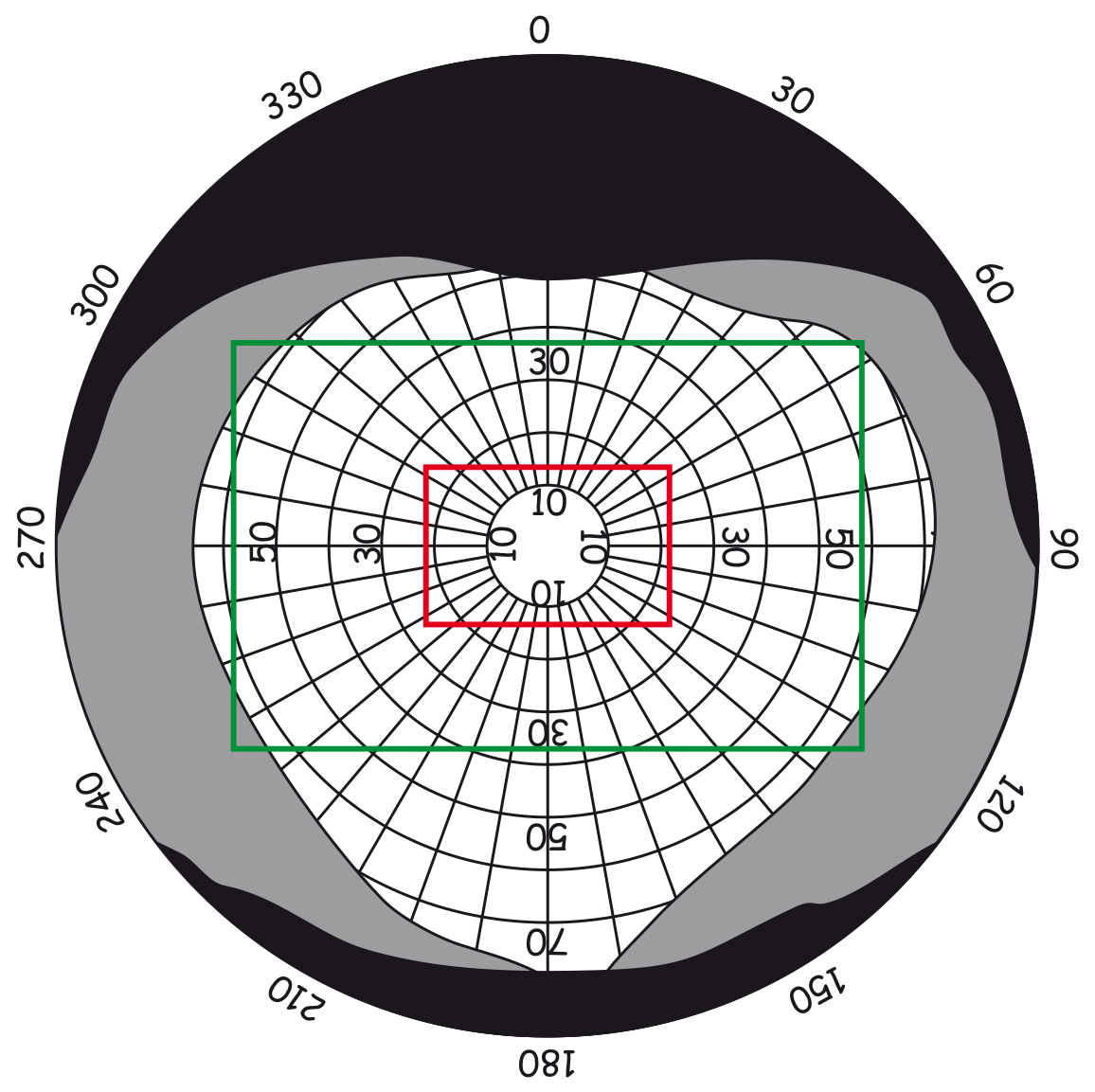
Podsumowując, zakres pola widzenia oczu jest całkiem spory, ale faktycznie – jak już niebawem się przekonamy – nie przekłada się to widzenie sceny równie wyraziście w każdym punkcie tego pola. Przeciwnie, tylko niewielki obszar znajdujący się w okolicy dołka centralnego siatkówki dostarcza do kory mózgu precyzyjnych danych o oglądanych rzeczach. Pozostała (tzw. peryferyczna) część pola widzenia pozwala zaledwie orientować się, co do obecności niezbyt ostro widzianych rzeczy w scenie wizualnej, ale za to jest szczególnie wrażliwa na ich ruch.
Zakres pola widzenia a wielkość obiektu w kadrze sceny wizualnej
Zakres pola widzenia mówi nam coś na temat kształtu i wyrażonej w jednostkach kątowych wielkości wykadrowanej sceny wizualnej, na której przez ułamek sekundy fiksujemy wzrok. Korzystając z opisu pola widzenia za pomocą jednostek kątowych warto zatrzymać się i pobawić w prostą arytmetykę. Pozwoli ona uświadomić sobie, w jaki sposób mózg szacuje odległości lub wielkości widzianych rzeczy w scenie. O wszystkich tych informacjach decydują trzy parametry: (1) rzeczywista wielkość (size; S) oglądanego obiektu (rozumiana jako jego wysokość lub szerokość), wyrażona w milimetrach, centymetrach lub metrach, (2) kąt (angle; A) pola widzenia, wyrażony w stopniach i (3) odległość (distance; D) obiektu od soczewki oka, wyrażona w milimetrach, centymetrach lub metrach (ryc. 42). Ponieważ wielkość siatkówki w oku jest stała, a soczewka automatycznie dopasowuje ogniskową do tego obiektu, który znajduje się na przecięciu osi widzenia, dlatego oba te wskaźniki mogą być pominięte w ustalaniu poszczególnych parametrów rzeczy znajdujących się w kadrze sceny wizualnej.
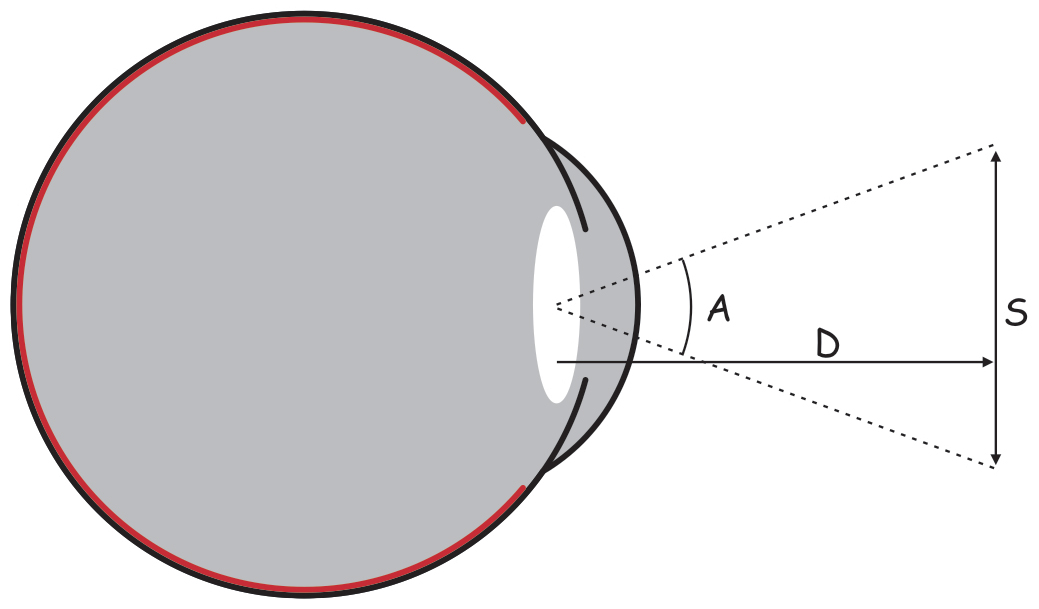
Znając rzeczywistą wielkość obiektu w jednostkach metrycznych oraz jego odległość od oczu obserwatora, bez trudu można wyznaczyć jego wielkość kątową wg następującego wzoru:
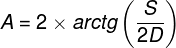
Jeżeli znamy wielkość kątową obiektu i jego odległość od oczu obserwatora, możemy z kolei obliczyć jego wielkość rzeczywistą:
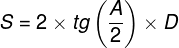
Możemy również wyliczyć, w jakiej odległości od oczu obserwatora znajduje się obiekt, znając jego wielkość rzeczywistą i kątową:
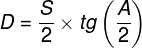
Zastosujmy te wzory w odniesieniu do sytuacji oglądania, np. obrazu w muzeum. Przypuśćmy, że z odległości 200 cm ktoś ogląda obraz o wymiarach 61 cm (wysokość) x 43 cm (szerokość). Na podstawie wzorów możemy obliczyć, że jego wysokość i szerokość kątowa wynoszą, odpowiednio:
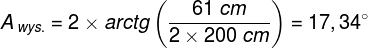
oraz
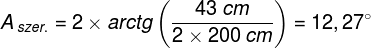
Na podstawie badania perymetrycznego wiadomo, że średni zakres pola widzenia człowieka w płaszczyźnie wertykalnej wynosi ok. 130°, a to oznacza, że cały obraz o wysokości kątowej nieco ponad 17° znajduje się w polu widzenia obserwatora. Niestety, bynajmniej nie znaczy to, że w całości jest on równie ostro widziany.
Jak zostało to już wcześniej zasygnalizowane, ze względu na budowę siatkówki oko człowieka maksymalnie wyraźnie rejestruje tylko do ok. 5° powierzchni sceny wizualnej, to okazuje się, że z odległości 200 cm penetruje ono powierzchnię obrazu w kształcie zbliżonym do koła o średnicy ok. 17,5 cm (dla 5° kąta pola widzenia):
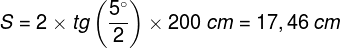
Jeżeli podstawimy obliczoną średnicę do wzoru na powierzchnię koła, czyli:
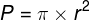
gdzie π jest stałą i wynosi ok. 3,14, a r to promień tego koła, czyli połowa jego średnicy, to okaże się, że z odległości 2 metrów ostro widzimy powierzchnię ok. 240 cm2
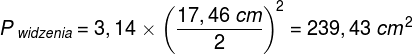
Na pierwszy rzut oka wydaje się to całkiem sporo, ale kiedy porównamy tę powierzchnię z powierzchnia całego obrazu, która wynosi ponad 2600 cm2
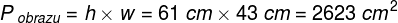
gdzie h to wysokość a w to szerokość prostokątnego obrazu, to okaże się, że pole widzenia o wielkości ok. 240 cm2 pokrywa tylko niespełna 10% powierzchni całego obrazu. Wynika to z następującego stosunku:
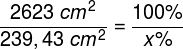
czyli
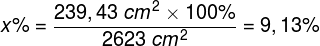
Wypada dodać, że mózg „korzysta” z przytoczonych wzorów do różnych celów, np. do oceny odległości w głąb między dwojgiem ludzi. Jeśli „wie”, że mają oni podobny wzrost (np. 180 cm), ale wielkość kątowa jednego wynosi, np. 21°, a drugiego 12°, to łatwo może dojść do wniosku, że pierwszy znajduje się w odległości niespełna 5 m od oczu obserwatora:
a drugi w odległości ponad 8,5 m od niego:
Do zagadnień związanych z wynikiem badania perymetrycznego i wzorów, za pomocą których można obliczyć zakres pola widzenia lub odległość obiektu od obserwatora jeszcze wrócimy przy okazji omawiania problematyki widzeniem kształtów.
Widzenie holistyczne czy sekwencyjne?
Do tej pory pisałem o widzeniu obrazu w taki sposób, jakby był on nam dany w całości, w jednym rzucie oka. Takie jest nasze subiektywne doświadczenie. Na ogół potrzebujemy chwili by zorientować się, jakie obiekty znajdują się w scenie wizualnej i co ona przedstawia. Mamy wrażenie, że obrazy „chwytamy” momentalnie. Ale właśnie to subiektywne doświadczenie widzenia przysłania nam prawdę na temat sekwencyjności i niekompletności danych, które stanowią jego podstawę. Oglądanie jest bowiem procesem realizowanym w czasie i między innymi dlatego, że jest to czas bardzo krótki, mamy wrażenie, że obraz wyłania się przed naszymi oczyma w jednej chwili.
Nawiasem mówiąc, momentalność całościowego ujęcia obrazu wiąże się także z jednym z najbardziej tajemniczych zjawisk umysłowych, czyli wyobraźnią (imagery). Służy ona, m.in. do przypominania sobie w całości uprzednio widzianych scen pod wpływem chwilowego pobudzenia fotoreceptorów. Jest to mechanizm operowania zasobami pamięci wzrokowej. Czasem rzeczywiście wystarczy jeden rzut oka, żeby pobudzić wyobraźnię do zrekonstruowania całej sceny wizualnej i doświadczenia jej jako widzenie (Francuz, 2007a; 2007b; 2010a; 2010b). Wyobraźnia odgrywa także niebagatelną rolę w procesach kategoryzacji percepcyjnej, leżącej u podłoża formowania się pojęć (Barsalou, 1999; Francuz, 2011).
Na doświadczenie widzenia składają się zatem dwa współdziałające ze sobą mechanizmy. Jeden z nich już z grubsza poznaliśmy. Jest to omówiony w poprzednim rozdziale mechanizm analizy zawartości sceny wizualnej. Jego zadaniem jest rejestrowanie rozkładu światła odbitego od rzeczy znajdujących się w tej scenie lub emitowanego przez nie i przekazanie tych danych do kory mózgu. Jest to oddolny mechanizm widzenia (bottom-up). Drugi mechanizm opiera się na danych dotyczących wyglądów świata, które zostały wcześniej zarejestrowane w różnych strukturach mózgu. To pamięć wizualna (visual memory), która podsuwa możliwe interpretacje dla aktualnie docierających do mózgu danych drogą oddolną. Musimy jednak pamiętać o tym, że znacznie mniej wiemy na temat tych odgórnych mechanizmów widzenia (top-down), niż na temat mechanizmów oddolnych.
Myślę, że dopiero jesteśmy na samym początku drogi, która pozwoli odpowiedzieć na pytanie, w jaki sposób przechowywane są dane w pamięci wizualnej i w jaki sposób są one wykorzystywane do budowania doświadczenia widzenia. W każdym razie, na obecnym poziomie wiedzy o percepcji wzrokowej możemy powiedzieć tylko tyle, że to co subiektywnie odczuwamy jako widzenie kompletnych obrazów (scen lub obiektów) jest raczej wytworem umysłu obserwatora, niż rejestracją rzeczywistości dostępnej za pomocą oczu. Zwracałem już kilka razy na to uwagę i jeszcze będę to nieraz podkreślał. Widziana scena jest efektem złożenia ze sobą dwóch rodzajów danych. Jedne pochodzą z rejestracji rozkładu oświetlenia jej fragmentów ograniczonych zakresem pola widzenia i drugie, zapisane w pamięci wspomnień wizualnych, które wypełniają brakujące części układanki za pomocą mechanizmu wyobrażeniowego. Programy wzrokowe działają tak szybko, że nie dostrzegamy kolejnych faz powstawania obrazu-układanki, tylko mamy wrażenie, że widzimy go od razu w całości. Podobnie jest z oglądaniem filmu w kinie. Na ekranie widzimy płynny ruch a przecież tak naprawdę w ciągu każdej sekundy oglądamy tylko 24 nieruchome zdjęcia. Czynnikiem decydującym o efekcie jest bardzo krótki czas ich ekspozycji.
Dlaczego poruszamy oczami?
Obserwowalnym przejawem sekwencyjności procesu widzenia jest ruch gałek ocznych. Żeby dobrze zrozumieć, jaką rolę odgrywa on podczas oglądania sceny wizualnej, musimy najpierw odpowiedzieć na dwa fundamentalne pytania: dlaczego oczy się w ogóle poruszają i jak się poruszają.
Zakres wysokorozdzielczego pola widzenia za pomocą receptorów skupionych w centralnej części siatkówki oka jest niewielki. Przypomnę, że obejmuje on nie więcej niż 5° kąta pola widzenia, co odpowiada ok. 3% powierzchni ekranu 21 calowego monitora oglądanego z odległości 60 cm. W stosunku do całej powierzchni ekranu to doprawdy niewiele. Żeby zobaczyć, co się znajduje w innych, 3‑procentowych fragmentach powierzchni musimy po prostu skierować na nie wzrok, zmieniając położenie oczu.
Gdyby oczy były na sztywno zamontowane w czaszce, wówczas bylibyśmy zmuszeni nieustannie poruszać głową, a to pochłaniałoby nieproporcjonalnie więcej energii, niż poruszanie oczyma. Byłoby to zatem nieadaptacyjne, a ewolucja raczej nie wzmacnia takich zachowań. Podsumowując, poruszamy oczyma, m.in. dlatego, że zakres pola widzenia jest ograniczony a zmieniając ich położenie jesteśmy w stanie obejrzeć poszczególne fragmenty sceny by z nich złożyć cały obraz. Sens poprzedniego zdania ma bardzo daleko idące konsekwencje, dotyczące rozumienia, w jaki sposób gromadzimy dane dotyczące oglądanej sceny.
Skanowanie różnych fragmentów sceny wizualnej nie jest jedynym powodem ruchu oczu. Innym może być, np. śledzenie poruszającego się obiektu bez zmiany położenia głowy lub utrzymywanie wzroku na stabilnym obiekcie, wtedy, gdy obserwator się porusza. Krótko mówiąc, istnieje wiele rodzajów ruchów oczu, a wszystkie one pełnią ściśle określone funkcje w procesie optymalnego kadrowania sceny wizualnej. Zanim jednak opiszę różne rodzaje ruchów oczu warto dokładniej przyjrzeć się ich neuro-mechanice.
Neuro-mechanika ruchliwego oka
Oko jest osadzone w oczodole wyścielonym kilkumilimetrową warstwą tkanki tłuszczowej. Ponieważ większa część zewnętrznej powłoki gałki ocznej, czyli twardówka jest gładka, dlatego oko bez najmniejszych oporów może poruszać się w oczodole, niczym kulka w dobrze nasmarowanym łożysku. Gałka oczna jest oczywiście mniejsza niż otwór oczodołu i mogłaby łatwo zeń wypaść, gdyby nie mięśnie trzymające ją od wewnętrznej strony czaszki. Ich rola nie sprowadza się jednak bynajmniej tylko do przeciwdziałania wypadaniu oka z oczodołu, ale pełnią one znacznie ważniejsze funkcje. Podobnie, jak mięśnie przyczepione do kości ręki czy nogi umożliwiają ich ruch, również mięśnie przyczepione do gałki ocznej stanowią mechaniczną podstawę zmiany jej położenia.
W ruchach każdego oka uczestniczą po trzy pary antagonistycznych mięśni, przyczepionych do tylnej, zewnętrznej powierzchni każdego z nich. Mięśnie proste boczne, skroniowy (lateral rectus) i przyśrodkowy (medial rectus) pozwalają na ruch oka w prawo lub w lewo, mięśnie proste, górny (superior rectus) i dolny (inferior rectus) poruszają okiem do góry lub w dół, a mięśnie skośne, także górny (superior obliqe) i dolny (inferior obliqe), pozwalają na ruch rotacyjny gałki ocznej, dzięki czemu możliwe jest skierowanie oczu w miejsca leżące między płaszczyzną horyzontalną i wertykalną, np. w prawy górny lub lewy dolny róg obrazu (ryc. 43). Nawiasem mówiąc oczy mogą także cofać się w głąb czaszki. Wykonują wówczas tzw. ruch retrakcyjny, będący wynikiem skurczenia się wszystkich mięśni jednocześnie, np. w sytuacji przewidywanego uderzenia w twarz. Mięśnie poruszające gałką oczną charakteryzują się tym, że kurczą się najszybciej spośród wszystkich mięśni poruszających ciałem człowieka (Matthews, 2000).
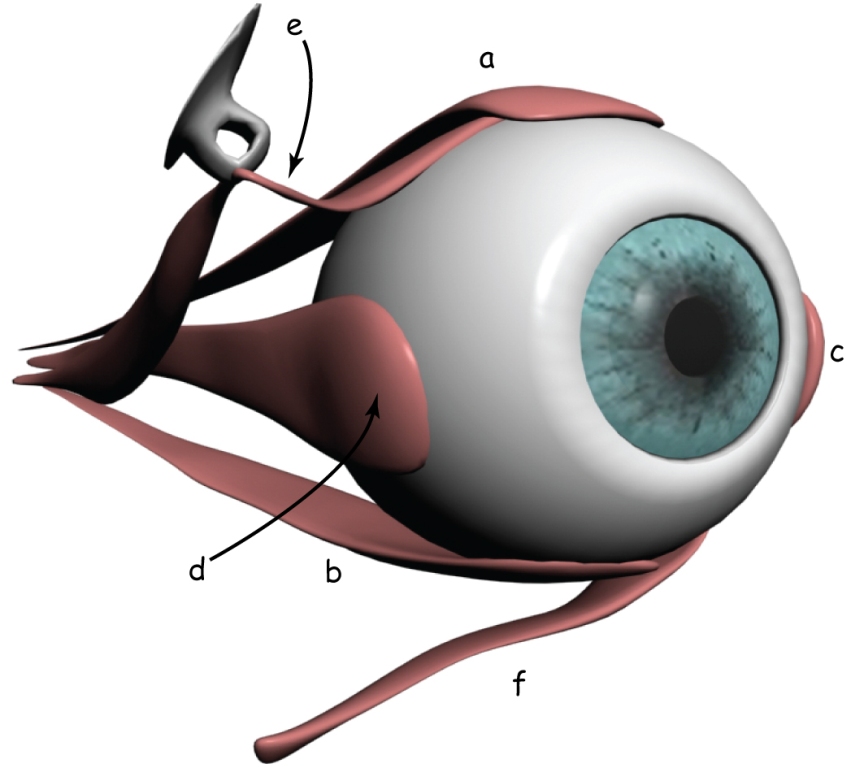
Ze względu na budowę anatomiczną oka i czaszki, sposób osadzenia gałki ocznej w oczodole oraz charakterystykę wymienionych par mięśni zewnątrzgałkowych, zakres ruchów oka jest ograniczony do ok. 90° (maksymalnie do 100°) w płaszczyźnie horyzontalnej oraz ok. 80° (maksymalnie do 125°) w płaszczyźnie wertykalnej.
Warto przy tej okazji zwrócić uwagę na to, że chociaż zakres ruchów gałek ocznych w oczodołach jest całkiem spory, to w praktyce na ogół nie przekracza on 30° w każdej płaszczyźnie. Wynika to z ruchliwości głowy. Patrząc, np. w górę rzadko napinamy mięsień prosty dolny do granic wytrzymałości, tylko raczej przechylimy głowę nieco w tył i w ten sposób bez wysiłku skupimy wzrok na interesującym obiekcie, jednocześnie utrzymując oczy w bardziej naturalnym położeniu w oczodole. Jeśli chcielibyśmy natomiast spojrzeć, np. w lewo bez poruszenia głową, wówczas oś widzenia prawego oka przetnie nos i obraz pochodzący z tego oka będzie ograniczony. Dlatego korzystniej jest dopomóc sobie lekkim skrętem głowy w właśnie w lewo.
I na koniec kilka zdań dotyczących połączeń między mięśniami zewnątrzgałkowymi a najbliższymi strukturami mózgu, z których pochodzą sygnały wpływające na ich pracę. Pary mięśni przyczepionych do gałek ocznych reagują gwałtownym skurczem lub rozluźnieniem pod wpływem impulsów nerwowych płynących wzdłuż nerwów czaszkowych (cranial nerves) z komórek nerwowych (tzw. motoneuronów), zlokalizowanych w rdzeniu kręgowym. Mięśnie proste (oprócz bocznego skroniowego) oraz skośny dolny są aktywizowane przez impulsy płynące wzdłuż aksonów komórek zlokalizowanych w jądrze dodatkowym nerwu okoruchowego (Edinger–Westphal nucleus), za pośrednictwem III nerwu czaszkowego, zwanego okoruchowym (oculomotor nerve) (ryc. 44). Mięsień skośny górny jest kontrolowany przez jądro nerwu bloczkowego (nucleus nervi trochlearis) za pośrednictwem IV (bloczkowego) nerwu czaszkowego natomiast mięsień prosty boczny jest połączony z jądrem nerwu odwodzącego (abducens nucleus) za pośrednictwem VI (odwodzącego) nerwu czaszkowego. Na razie niech wystarczy ustalenie skąd pochodzą sygnały aktywizujące mięśnie zewnątrzgałkowe, ale niebawem dowiemy się skąd płyną sygnały pobudzające z kolei wszystkie trzy wymienione jądra nerwowe. To właśnie ich aktywizacja przekłada się na określony ruch gałki ocznej.
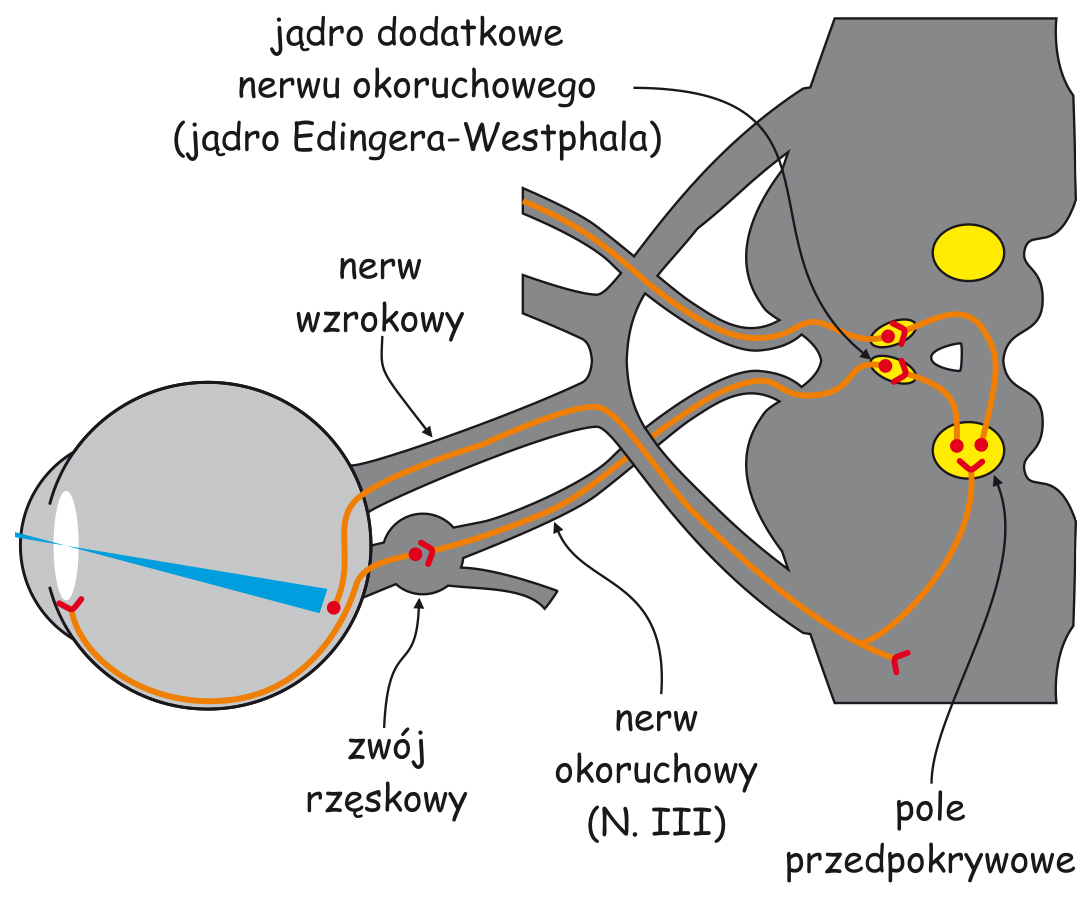
Ogólna klasyfikacja ruchów oczu
Mamy już ogólne pojęcie ruchu oka. Czas przyjrzeć się nieco dokładniej różnym rodzajom ruchów gałek ocznych, zarówno w kontekście ich funkcjonalności, jak i zarządzających nimi neurobiologicznych mechanizmów. Typologia ruchów oczu jest dość bogata, chociaż niektóre są ważniejsze, a inne nieco mniej ważne z punktu widzenia problematyki, podejmowanej w niniejszej książce. Omówię je, poczynając od tych, których znaczenie dla widzenia obrazu jest nieco mniejsze, a kończąc na tych, które stanowią trzon mechanizmu kadrowania sceny wizualnej. W gruncie rzeczy nadrzędnym celem wszystkich typów ruchów gałek ocznych jest podtrzymywanie najwyższej jakości widzenia w różnych warunkach oglądania sceny wizualnej.
Pierwsza grupa ruchów oczu jest związana z pozornym bezruchem gałki ocznej, czyli tym momentem, w którym oko na chwilę fiksuje się na jakimś fragmencie obrazu. To zaskakujące, ale nawet wtedy oczy wykonują co najmniej trzy drobne i całkiem odmienne ze względu na trajektorię mikroruchy, czyli ruchy fiksacyjne: mikrosakady, mikrodryft i mikrodrżenia. Najkrócej mówiąc, przeciwdziałają one adaptacji fotoreceptorów do tego samego oświetlenia podczas fiksacji oka.
Drugą grupę ruchów oczu stanowią odruchy, czyli ruchy mimowolne, których celem jest podtrzymywanie przez dłuższą chwilę spojrzenia na wybranym obiekcie w scenie wizualnej w specyficznych warunkach oglądania. I tak, np. celem odruchu przedsionkowo-ocznego jest utrzymywanie spojrzenia na danym obiekcie wtedy, gdy porusza się głowa. Z taką sytuacją mamy do czynienia codziennie tak często, że w toku ewolucji wytworzył się w pełni zautomatyzowany mechanizm okoruchowy. Pozwala on nam na utrzymywanie wzroku na interesującym nas obiekcie podczas zmiany położenia względem niego.
Innym, w pełni zautomatyzowanym ruchem gałek ocznych jest odruch optokinetyczny. Jego celem jest utrzymywanie spojrzenia na obiekcie wtedy, gdy, albo ten obiekt się porusza bardzo szybko wobec nieruchomego obserwatora, albo obserwator się przemieszcza bardzo szybko względem nieruchomego obiektu. Wreszcie trzeci odruch okoruchowy umożliwia obserwatorowi utrzymywanie spojrzenia na obiekcie, który się doń zbliża lub od niego oddala, albo do którego się zbliża, lub od którego się oddala obserwator. Są to tzw. odruchy wergencyjne, przy czym te, które towarzyszą zmniejszającemu się dystansowi między obiektem a obserwatorem nazywają się konwergencyjne, a te, które towarzyszą zwiększaniu się tego dystansu, nazywają się dywergencyjne.
Trzecia grupa ruchów oczu jest szczególnie ważna dla zrozumienia, czym jest widzenie. Są to ruchy kadrujące. Pierwszy, z nich nazywa się sakadą lub inaczej ruchem skokowym i jego celem jest precyzyjne pozycjonowanie osi widzenia obu gałek ocznych na najważniejszym, z jakiegoś powodu, fragmencie sceny wizualnej. Sakady – jak się niebawem przekonamy – mogą być wykonywane pod wpływem impulsów mających swoje źródło w scenie wizualnej, czyli oddolnie, jak również mogą być sterowane odgórnie, w większym lub mniejszym stopniu zgodnie z wolą obserwatora. Drugim ruchem w tej grupie jest tzw. ruch podążania. Żeby zrozumieć jego istotę wystarczy zwrócić uwagę na to, w jaki sposób mężczyźni (no, może nie wszyscy) przyglądają się mijającej ich atrakcyjnej dziewczynie. Ich wzrok jest niemal przyklejony do którejś jej części ciała. Oczy poruszają się dokładnie z tą sama szybkością, z jaką się ona porusza. To właśnie jest ruch podążania.
Wspólną cechą sakad i ruchów podążania jest to, że w odróżnieniu od wszystkich pozostałych, w znacznie większym stopniu są sterowane dowolnie. Ich celem jest takie wykadrowanie sceny wizualnej, aby pozyskać z niej jak najwięcej danych, które pozwolą na skonstruowanie trafnej reprezentacji poznawczej tej sceny.
Fiksacyjne ruchy oczu
Każda sakada kończy się krótkotrwałą fiksacją, czyli zatrzymaniem ruchu gałek ocznych na tym fragmencie sceny wizualnej, która aktualnie znajduje się na linii wzroku. Zafiksowane oko wygląda na zupełnie nieruchome, ale faktycznie wykonuje ono w tym czasie trzy rodzaje mimowolnych ruchów fiksacyjnych, zwanych mikrodrżeniem (ocular microtremor), mikrodryftem (ocular drift) i mikrosakadą (microsaccade).
Fiksacyjne ruchy oczu są szybkie i krótkie, mają skomplikowaną i wydawać by się mogło, zupełnie chaotyczną trajektorię. Pełnią one jednak bardzo ważne funkcje podczas widzenia. Przede wszystkim zapobiegają adaptacji pobudzonej już grupy fotoreceptorów do działającego na nie światła. Nieznacznie zmieniając położenie ustabilizowanego oka podczas fiksacji powodują, że w rejestrację tego samego obrazu rzutowanego na siatkówkę stale angażowane są nowe, niepobudzone jeszcze fotoreceptory. Ruchy te pozwalają także na zebranie jeszcze większej ilości danych z wykadrowanego fragmentu sceny wizualnej, na którym oczy się fiksują (Leigh i Zee, 2006; Martinez-Conde, Macknik i Hubel, 2004). Wszystkie te trzy rodzaje ruchów zostały po raz pierwszy zarejestrowane, a ich szczegółowy opis opublikowany przez Roy’a M. Pritcharda w 1961 roku (ryc. 45).
Mikrodrżenia, nazywane również tremorem lub oczopląsem fizjologicznym (physiological nystagmus), są stałą i całkowicie mimowolną aktywnością gałek ocznych podczas fiksacji. Mają one najmniejszą ze wszystkich mikroruchów amplitudę o długości nie przekraczającej średnicy pojedynczego czopka znajdującego się w dołku centralnym (Martinez-Conde, Macknik, Troncoso i Hubel, 2009) oraz nieporównywalnie większą niż one częstotliwość, bowiem w granicach 70–100 Hz (Bloger., Bojanic., Sheahan, Coakley. i in., 1999). Trajektoria mikrodrżeń jest inna w każdym oku.
Drugim rodzajem ruchów fiksacyjnych jest mikrodryft. Jest to stosunkowo wolny ruch gałki ocznej, w dość przypadkowym kierunku, który powoduje, że obraz rzutowany na siatkówkę oka stale oświetla nieco inną grupę fotoreceptorów. Amplituda dryftu waha się od 1’ do 8’ (minut kątowych, czyli sześćdziesiątych części stopnia kątowego), a prędkość wynosi poniżej 30’/s (Rolfs, 2009). W odróżnieniu od mikrodrżeń, dryft powoduje globalną zmianę relacji między obrazem rzutowanym na siatkówkę, a znajdującymi się w niej fotoreceptorami. Ten ruch zapobiega adaptacji fotoreceptorów do tej samej intensywności światła, a tym samym, zanikaniu obrazu. Pobudzony już fotoreceptor na moment wyłącza się bowiem z absorbowania nowej porcji światła i przestaje być na nie wrażliwy. Wspomniany Roy M. Pritchard (1961) wykazał, że ustabilizowanie obrazu na tej samej grupie fotoreceptorów powoduje, że z każdą chwilą obraz jest widziany coraz gorzej, aż do jego częściowego lub całkowitego zaniku. Podobnie, jak w odniesieniu do mikrodrżeń, podczas fiksacji oczu na tym samym fragmencie sceny wizualnej, trajektoria dryftu w prawym i w lewym oku jest zupełnie inna (ryc. 46).
Wreszcie trzeci rodzaj ruchów fiksacyjnych oczu stanowią mikrosakady. W ostatnich latach budzą one coraz większe zainteresowanie (np. Engbert, 2006; Engbert, Kliegl, 2004; Martinez-Conde i in., 2004; 2009; Rolfs, 2009). Ich amplituda jest bardzo zróżnicowana i waha się od 3’ (minut kątowych) do 2° kąta pola widzenia, zaś prędkość na ogół jest nieporównywalnie większa niż prędkość mikrodrżeń czy mikrodryftu (Martinez-Conde i in., 2009). Efekt przesunięcia siatkówki w stosunku do rzutowanego nań obrazu wywołany przez mikrosakadę jest analogiczny do mikrodryftu. Mikrosakada jest jednak szybsza i najczęściej przesuwa oś widzenia na większą odległość niż mikrodryft. Mikrosakady, w odróżnieniu od tremoru i mikrodryftu, są wykonywane synchronicznie przez oboje oczu (zob. linia czerwona na ryc. 46).
Martin Rolfs (2009) wskazuje na wiele różnych funkcji, jakie pełnią mikrosakady. Przede wszystkim radykalnie zmieniają one relację rzutowanego obrazu do powierzchni siatkówki zapobiegając jego zanikaniu, a ponadto, sprzyjają utrzymaniu wysokiej ostrości widzenia, służą do skanowania niewielkiej powierzchni fiksacji (m.in. w celu trafniejszej detekcji krawędzi rzeczy w scenie wizualnej) oraz pełnią ważną funkcję w procesie programowania kolejnych sakad, poprzez przesunięcia tzw. uwagi wzrokowej w nowe obszary sceny wizualnej.
Odruchy okoruchowe
Przegląd ruchów oczu uwikłanych w ruch obserwatora lub obiektów w scenie wizualnej zacznę od omówienia trzech rodzajów odruchów, czyli takich reakcji oczu, które niemal całkowicie wymykają się spod kontroli obserwatora. Są to: odruch przedsionkowo-oczny (vestibulo-ocular reflex, VOR), odruch optokinetyczny (optokinetic reflex) oraz odruchy wergencyjne (vergence), konwergencyjny (convergence) i dywergencyjny (divergence).
Już na pierwszy rzut oka widać, że głowa i oczy mogą poruszać się niezależnie od siebie. Ma to oczywiste plusy, ponieważ dzięki temu układ wzrokowy jest znacznie lepiej przystosowany do różnych sytuacji życiowych, które wymagają dobrej orientacji w przestrzeni. Ta sytuacja rodzi jednak również pewien problem, z którym ewolucja znakomicie sobie poradziła. Chodzi o to, że niejednokrotnie chcemy nieco dłużej fiksować wzrok na jakimś szczególe sceny wizualnej, a jednocześnie jesteśmy w ruchu. Wystarczy wyobrazić sobie jak skomplikowaną pracę muszą wykonywać mięśnie oczu, żeby utrzymać wzrok na wybranym miejscu sceny wizualnej przez jeźdźca podczas zawodów hippicznych. Głowa nie tylko porusza się we wszystkich kierunkach, równoważąc zakłócenia równowagi związane z ruchem konia, ale ponadto wciąż zmienia swoje położenie względem oglądanej sceny. Nieco mniej ekstremalną, choć analogiczną, sytuacją jest oglądanie wystaw sklepowych podczas spaceru lub oglądanie w ruchu obrazów wiszących na ścianach w muzeum.
Mechanizmem wzrokowym, który przeciwdziała utracie ostrości widzenia związanym z ruchem głowy jest odruch przedsionkowo-oczny, zwany również – przedsionkowym. Odruch ten można łatwo zaobserwować, gdy poruszając głową w prawo i w lewo, stale spoglądamy na jakiś przedmiot (ryc. 47). Odruch przedsionkowy możemy zaobserwować wykonując proste zadanie. Patrząc w lustro postarajmy się stale utrzymywać wzrok na źrenicach swoich oczu i jednocześnie poruszajmy głową we wszystkich kierunkach. Każdy ruch głową w jedną stronę spowoduje odruchową reakcję oczu w przeciwnym kierunku. Prędkość ruchów głowy i oka jest taka sama.

U podłoża odruchu VOR leży mechanizm fizjologiczny, który w celu usprawnienia działania systemu wzrokowego wykorzystuje dane pochodzące z systemu kinestetycznego, który przede wszystkim jest odpowiedzialny za utrzymywanie równowagi ciała (ryc. 48).
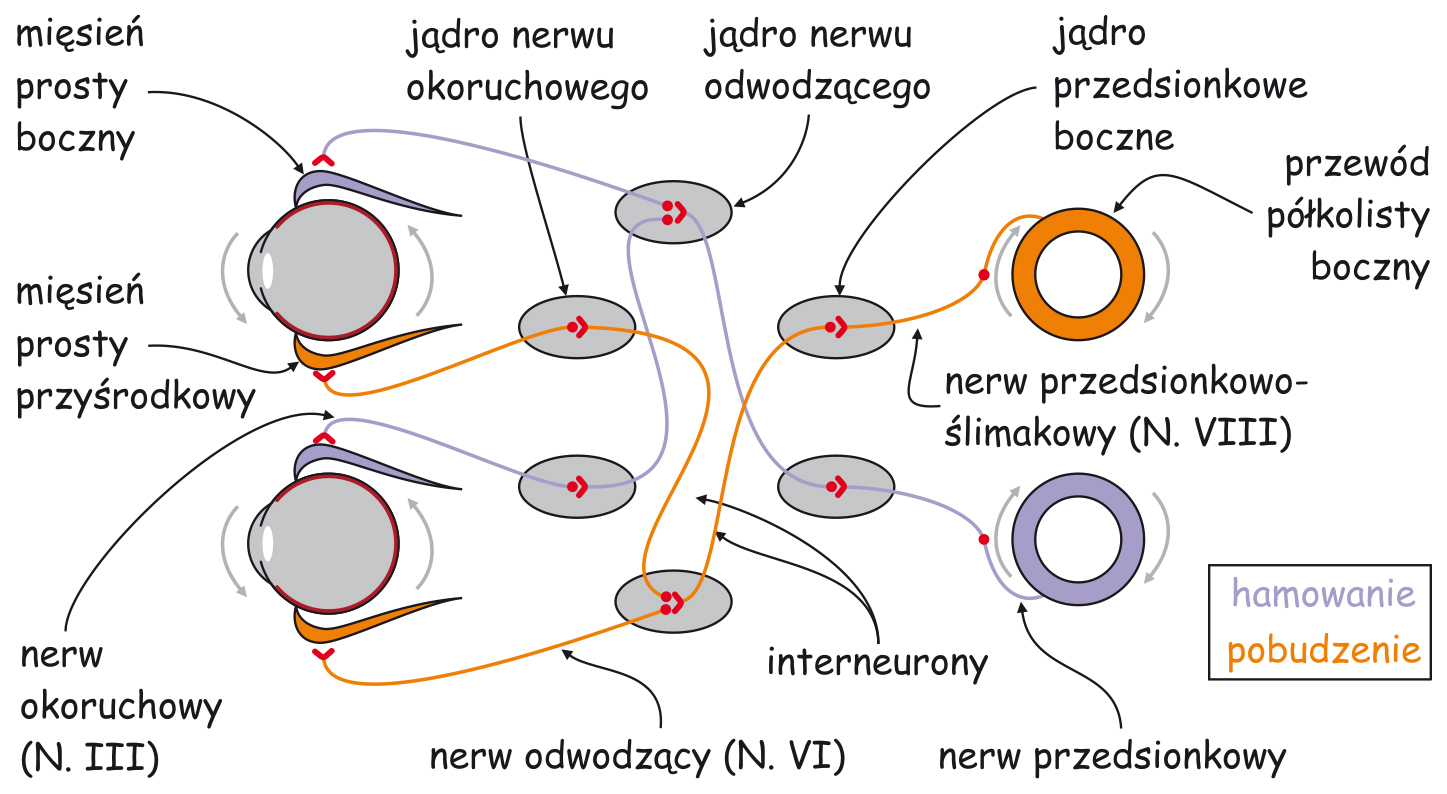
Detekcja położenia i ruchu głowy zachodzi w narządzie przedsionkowym, zlokalizowanym w uchu wewnętrznym. Dane z narządu przedsionkowego są przekazywane do jąder przedsionkowo-bocznych, niewielkich skupisk neuronów znajdujących się po obu stronach pnia mózgu (a dokładniej w części grzbietowo-bocznej rdzenia przedłużonego). Stąd sygnały są przekazywane do dwóch par jąder, które bezpośrednio zawiadują ruchami oczu, czyli wspomnianych już jąder nerwu okoruchowego i odwodzącego (Matthews, 2000; Nolte, 2011).
Podsumowując, nawet najdrobniejsze odchylenie głowy od pionu jest rejestrowane w narządzie przedsionkowym a informacja o tym, skrzętnie wykorzystywana przez system odpowiedzialny za ruchy gałek ocznych. Dzięki odruchowi przedsionkowo-ocznemu możemy stale rzutować wybrany fragment obrazu na centralną część siatkówki bez utraty ostrości widzenia.
Odruch optokinetyczny, pojawia się w sytuacji, gdy głowa jest względnie stabilna, natomiast oczy bezwiednie fiksują się na stosunkowo dużym obiekcie, którego obraz szybko zmienia swoje położenie na siatkówce. Na przykład, jadąc pociągiem od czasu do czasu zatrzymujemy spojrzenie na jakimś elemencie tej dynamicznej sceny i kiedy znika z pola widzenia, oczy znowu „przyklejają się” do innego obiektu. Odruch optokinetyczny może współwystępować z odruchem przedsionkowo-ocznym, czyli wtedy gdy dodatkowo porusza się głowa (Mustari i Ono, 2009). Ma on krótki czas latencji (poniżej 100 ms), stosunkowo dużą prędkość (nawet powyżej 180°/sek.) i naprawdę trudno jest go kontrolować (Büttner i Kremmyda, 2007). Zasadniczo ma on niewielkie znaczenie podczas oglądania stabilnych obrazów.
Podstawową funkcją obu odruchów (przedsionkowego i optokinetycznego) jest kompensowanie utraty ostrości widzenia obiektu znajdującego się w scenie wizualnej, spowodowanej ruchem obserwatora lub obiektu znajdujących się w płaszczyźnie prostopadłej do osi widzenia. Z kolei tzw. odruch wergencyjny występuje podczas oglądania sceny wizualnej, w której obiekty (lub obserwator) zmieniają położenie względem siebie w linii równoległej do osi widzenia, czyli zbliżają się lub oddalają od siebie.
Odruchy wergencyjne występują w dwóch formach, jako odruch konwergencyjny, czyli zbieżny lub dywergencyjny, czyli rozbieżny. Ich prędkość jest podobna i wynosi ok. 25°/s. Celem odruchów wergencyjnych jest utrzymywanie osi widzenia na obiekcie, w zależności od jego dystansu od obserwatora. Gdy odległość między nimi zmniejsza się, wówczas źrenice gałek ocznych zbliżają się do siebie (konwergencja), a gdy odległość się zwiększa, oddalają się od siebie (dywergencja) (ryc. 49).
Odruch ten przypomina trochę robienie zeza, zbieżnego lub rozbieżnego. Kiedy obiekt znajduje się w odległości większej niż 5–6 m od obserwatora, wówczas osie widzenia obu oczu ustawiają się niemal równoległe do siebie. Jest to granica, powyżej której odruchy wergencyjne oczu odgrywają coraz mniejszą rolę w stereoskopowym, czyli dwuocznym widzeniu głębi. Podobnie, jak poprzedni, odruch ten ma stosunkowo niewielkie znaczenie dla rozpoznawania głębi w sytuacji oglądania płaskiej powierzchni obrazu.
Podstawowy mechanizm kadrowania sceny wizualnej
Ruchy sakadowe (saccadic) oczu zasadniczo służą do przeniesienia spojrzenia z jednego punktu względnie stabilnej sceny wizualnej na inny. Można je łatwo obserwować, spoglądając w oczy komuś, kto się czemuś przygląda. Zobaczymy wówczas, że źrenice gałek ocznych obserwatora co pewien czas, równocześnie zmieniają swoje położenie, ustawiając osie widzenia na kolejnych fragmentach oglądanego obrazu.
Po każdym skoku, czyli sakadzie oczy nieruchomieją na krótszą lub dłuższą chwilę. Ten moment nazywa się fiksacją wzroku i jest jednym z najważniejszych aktów w procesie widzenia. Właśnie wtedy rejestrowane są dane o poziomie pobudzenia fotoreceptorów w siatkówkach oczu, a już chwilę później przekazywane do mózgu, jako informacja o aktualnie widzianym fragmencie sceny wizualnej. To jest moment „naświetlania kadru”.
Na ryc. 50B zaznaczyłem ruchy sakadowe (żółte linie) i miejsca fiksacji wzroku (żółte punkty) zarejestrowane podczas oglądania portretu Krystyny Potockiej, namalowanego przez Angelicę Kauffmann z kolekcji wilanowskiej (ryc. 50A). Obraz był oglądany przez 24 osoby badane na monitorze komputerowym, a ruch ich gałek ocznych zarejestrowałem za pomocą okulografu SMI HighSpeed 1250 Hz. Wyniki tego eksperymentu zostaną omówione w ostatnim rozdziale książki, który jest poświęcony percepcji piękna.


Mózg „nie jest zainteresowany” tymi danymi i dlatego krótkotrwale wyłącza niektóre podzespoły, a dokładniej mówiąc, te części kory wzrokowej, które są odpowiedzialne za odbiór danych o stanie pobudzenia fotoreceptorów (Paus, Marrett, Worsley i Evans, 1995; Burr, Morrone i Ross, 1994). Zjawisko to nazywa się wygaszanianiem sakadowym (saccadic suppression) lub maskowaniem sakadowym (saccadic masking). Działanie tego mechanizmu jest podobne do działania migawki w kamerze filmowej (ryc. 51).
Nagrywanie filmu polega na naświetlaniu sekwencji kadrów na unieruchomionej taśmie celuloidowej, pokrytej światłoczułą błoną. Podczas przesuwania taśmy o jedną klatkę, obracająca się migawka na moment całkowicie ją zasłania. W ten sposób błona fotograficzna nie jest naświetlana podczas ruchu taśmy tylko wtedy, gdy jest ona nieruchoma. Rejestrowanie sceny wizualnej za pomocą oczu przebiega podobnie. Mózg analizuje tylko te obrazy, które zostały zarejestrowane przez fotoreceptory podczas fiksacji wzroku, a nie podczas sakady. Dzięki temu scena wizualna, doświadczana przez nas jako widzenie jest konstruowana przede wszystkim w oparciu o wyraźne i stabilne (tzn. nierozmyte i nieporuszone) obrazy. Czasy sakad podobnie, jak czasy przesunięcia taśmy nie należą do czasu trwania zarejestrowanej sceny wizualnej. Na szczęście są one o rząd wielkości krótsze niż fiksacje.
W ciągu każdej sekundy oczy wykonują 3–5 sakad. W chwilach podwyższonego pobudzenia może być ich jednak znacznie więcej. Ruchy sakadowe są gwałtowne – zaczynają i kończą się równie nagle, i w zależności od sytuacji trwają od 10 do 200 ms, np. podczas czytania wynoszą średnio, ok. 30 ms (Duchowski, 2007; Leigh i Zee 2006). Różnią się od siebie długością, czyli amplitudą, a także prędkością. Amplituda sakady jest uzależniona od wielu czynników, m.in. od wielkości sceny wizualnej lub położenia znajdujących się w niej obiektów, ale na ogół nie przekracza 15° kąta pola widzenia (maksymalnie może wynosić do 40°). Czas jej wykonania jest proporcjonalny do amplitudy, choć nie jest to zależność prostoliniowa. Podobnie, prędkość sakady wzrasta proporcjonalnie (choć także nie liniowo) w stosunku do amplitudy i u człowieka może wynosić nawet do 900°/sek. (Fischer i Ramsperger, 1984). To najszybszy ruch ludzkiego ciała. Zależności między amplitudą, czasem i prędkością każdej sakady są względnie stałe. Tę cechę ruchów sakadowych nazywa się stereotypowością sakady (Bahill, Clark i Stark, 1975).
Balistyczność jest drugą, obok stereotypowości, cechą sakad (Duchowski, 2007). Jest ona rozumiana jako bezwładność, a zarazem niezmienność kierunku ruchu gałki ocznej po rozpoczęciu sakady. Podobnie, jak nie można zmienić parametrów lotu kamienia od momentu jego wyrzucenia, tak też sakada, której prędkość, przyspieszenie i kierunek zostaną zaprogramowane przed jej rozpoczęciem, zasadniczo nie mogą być już zmienione w trakcie wykonania (Carpenter, 1977).
Istnieje wiele rodzajów ruchów sakadowych (pełną klasyfikację zob. Leigh i Zee, 2006, s. 109–110), ale dwa z nich są szczególnie ważne z punktu widzenia problematyki przedstawianej w niniejszej książce. Są to odruchy sakadowe (reflexive saccades) oraz sakady wolicjonalne (voluntary saccades). Odruchowe, czy inaczej mimowolne sakady pojawiają się w odpowiedzi na specyficzne elementy sceny wizualnej takie, jak np. nagłe pojawienie się jakiegoś obiektu, gwałtowny ruch, wydatność (saliency) różnych jej części, kontrast, błyski lub migotania, a nawet dźwięki, w stronę których odruchowo kierują się oczy. Z kolei sakady wolicjonalne (dowolne) są sterowane odgórnie, tzn. ich trajektoria jest podporządkowana takim czynnikom, jak np. wiedza, nastawienie, świadome poszukiwanie czegoś w obrazie lub oczekiwanie obserwatora.
Neuronalna podstawa ruchów sakadycznych
Najważniejsze struktury neuronalne, które biorą udział w kontroli ruchów gałek ocznych (zarówno sakadycznych, jak i podążania) zostały przedstawione na ryc. 52. Ich wielość oraz skomplikowana sieć łączących je dróg znakomicie uświadamiają, jak złożony mechanizm steruje zwyczajnym spojrzeniem w prawo lub w lewo. Nie ma tu miejsca na przypadek, choć czasem ta maszyneria może nie nadążać za biegiem wydarzeń.
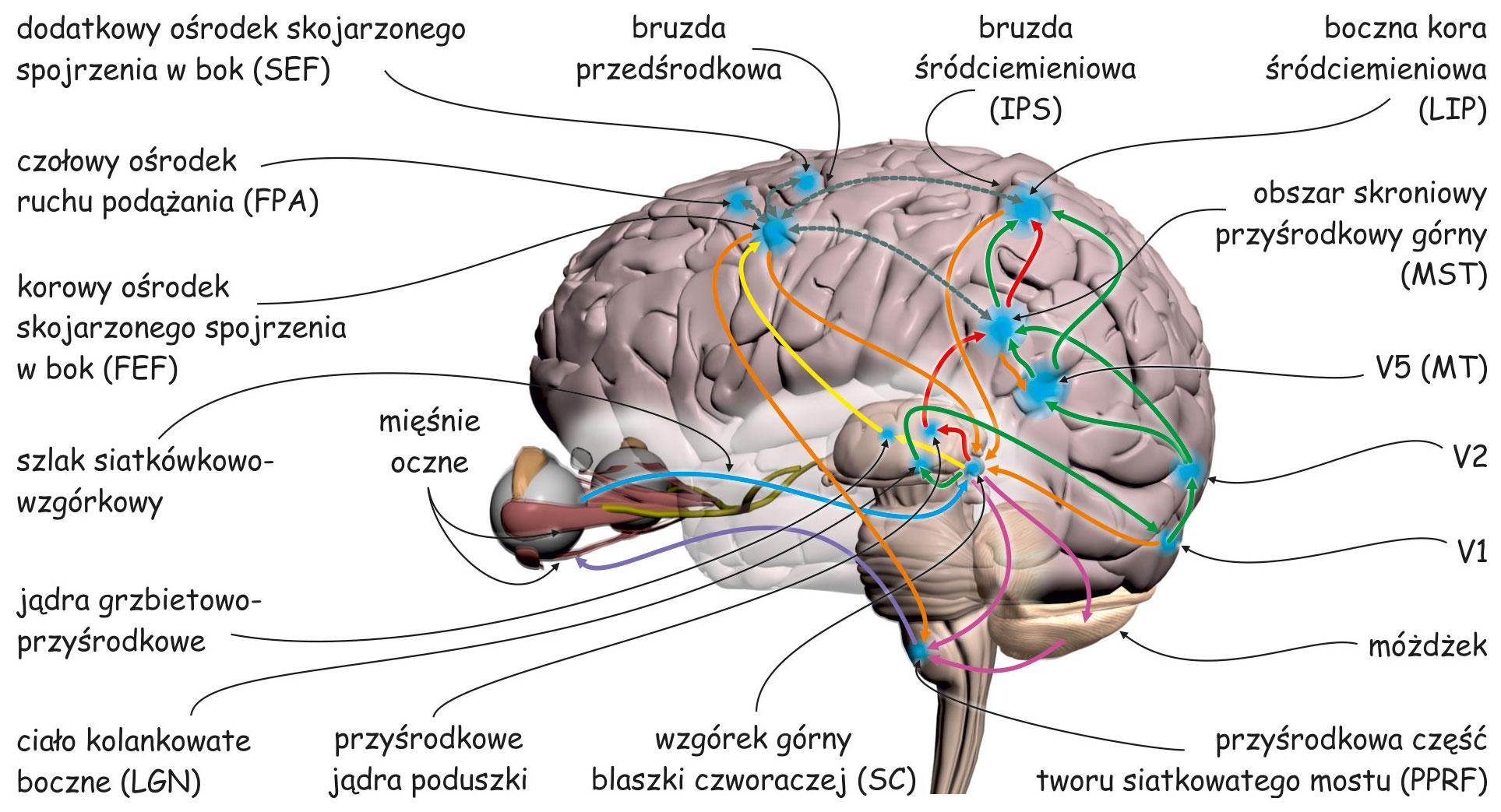
Zacznijmy od tych struktur systemu kontroli ruchu gałek ocznych, które znajdują się na wczesnych etapach szlaku wzrokowego. Jedną z najważniejszych jest wzgórek górny blaszki czworaczej (superior colliculus; SC), znajdujący się w pokrywie śródmózgowia. Impulsy nerwowe docierają do zewnętrznych warstw tej struktury z siatkówki za pośrednictwem wiązki włókien nerwu wzrokowego, zwanej szlakiem siatkówkowo-wzgórkowym (retino-collicular pathway) (ryc. 52, ścieżka niebieska).
Podstawowym zadaniem SC jest ustawienie pozycji gałek ocznych w taki sposób, aby ich osie widzenia znalazły się dokładnie naprzeciwko najbardziej interesującego fragmentu sceny wizualnej. Budowa i funkcjonowanie tej zdumiewającej struktury przypomina nieco celownik nowoczesnego karabinu strzelca wyborowego. Jest zbudowany warstwowo, podobnie, jak wiele struktur podkorowych (np. LGN) lub korowych (np. V1) mózgu (ryc. 53).
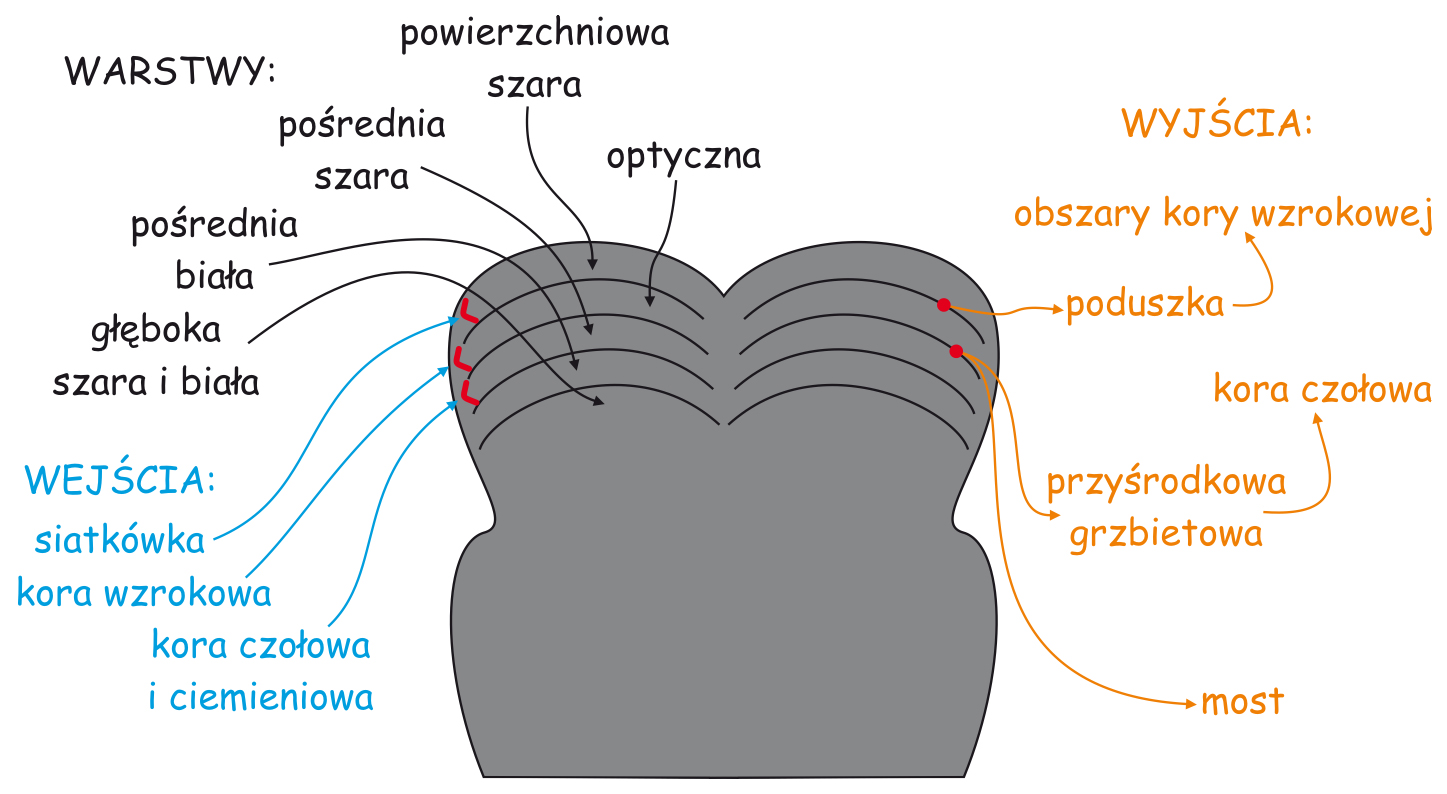
Przede wszystkim wierzchnia warstwa SC, do której docierają zakończenia synaptyczne aksonów komórek zwojowych z siatkówek oczu obserwatora (droga siatkówkowo-wzgórkowa), ma retinotopową organizację, analogiczną do pierwszorzędowej kory wzrokowej, czyli V1 (Nakahara, Morita, Wurtz i Optican, 2006).
Między reakcjami fotoreceptorów umieszczonych w określonych miejscach siatkówki a reakcjami komórek tworzących zewnętrzną warstwę SC zachodzi topograficzny związek (zob. ryc. 54).
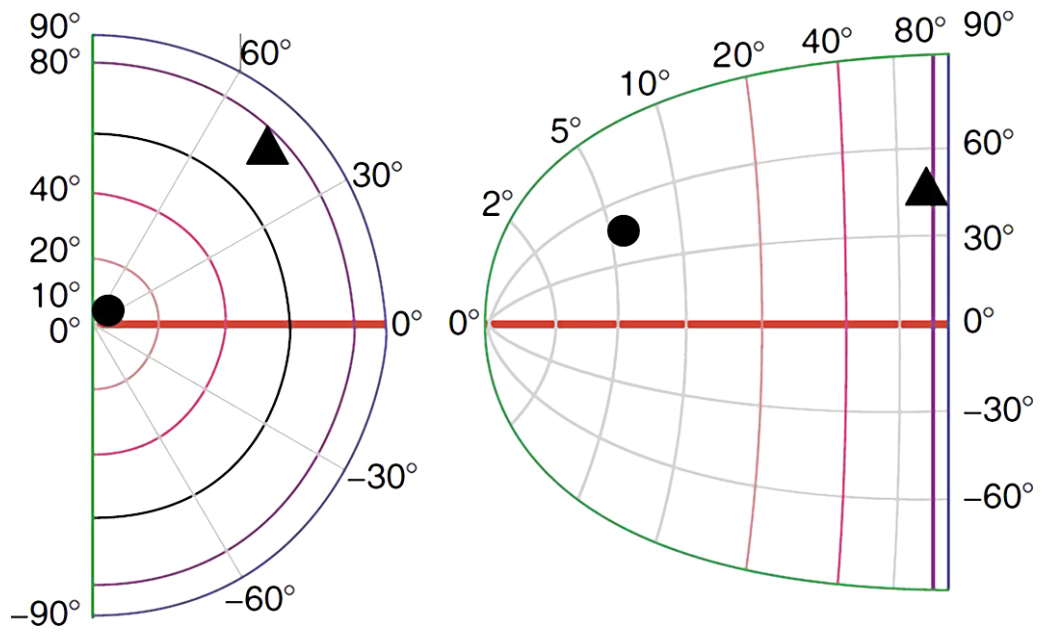
Podobnie, jak w V1 również w SC, największą część mapy zajmuje reprezentacja okolic dołka centralnego siatkówki. Znakomicie ilustrują to zaznaczone na ryc. 54 dwie figury: koło i trójkąt. Kółko, którego pozycję trudno jest precyzyjnie ustalić na podstawie wykresu siatkówki, bez trudu i dokładnie można zlokalizować na jej retinotopowej mapie w SC. Topograficznie zorientowana reprezentacja danych siatkówkowych w SC ma takie znaczenie dla wykonania kolejnej sakady, jak mapa w sztabie dowodzenia operacją wojskową, dla precyzyjnego określenia celu następnego ataku.
Drugą niezwykle interesującą cechą SC jest to, że komórki znajdujące się w jej głębszych warstwach reagują nie tylko na bodźce wzrokowe, ale również słuchowe (Jay i Sparks, 1984) i czuciowe (Groh i Sparks, 1996). Tłumaczy to, m.in. dlaczego nagły dźwięk lub zapach mogą skierować oczy na ich źródło. Wzgórkowy celownik wzrokowy nie jest więc narządem odizolowanym od innych zmysłów, wyspecjalizowanym tylko w zakresie reakcji na bodźce wizualne, ale urządzeniem biologicznym wrażliwym na znacznie szersze spektrum stymulacji zmysłowej. To dzięki takim strukturom mózgowym mamy poczucie, że nasze zmysły nie działają w izolacji od siebie, ale tworzą w pełni zintegrowany system reagujący w skoordynowany sposób na różne przejawy rzeczywistości (Cuppini, Ursino, Magosso, Rowland i in., 2010).
Wreszcie po trzecie, SC koordynuje pracę kilku różnych struktur mózgowych, wysyłając do nich i odbierając od nich impulsy nerwowe, w celu ostatecznego ustalenia miejsca kolejnej sakady. Po otrzymaniu danych z siatkówki o aktualnym położeniu oka względem sceny wizualnej, SC przesyła je w kierunku dwóch struktur, znajdujących się w korze mózgu (ryc. 52).
Pierwsza droga, a właściwie kilka odrębnych ścieżek, biegnie w kierunku płatów ciemieniowych, a dokładniej do bocznej kory śródciemieniowej (lateral intraparietal cortex; LIP), wyścielającej powierzchnię bruzdy śródciemieniowej (intraparietal sulcus; IPS). Jedna ze ścieżek prowadzi do tego miejsca przez LGN, pierwotną korę wzrokową (V1) i dalej przez okolicę skroniową przyśrodkową (medial temporal; MT), czyli sygnalizowany już obszar odpowiedzialny za widzenie ruchu V5 oraz obszar skroniowy przyśrodkowy górny (medial superior temporal; MST), które znajdują się w głębi bruzdy skroniowej górnej (superior temporal sulcus) (ryc. 52, ścieżka zielona).
Inna ścieżka biegnie krótszą drogą przez przyśrodkowe jądra poduszki (pulvinar medial nuclei), a stamtąd już bezpośrednio do bruzdy skroniowej górnej i dalej do IPS (Wurtz, 2008) (ryc. 52, ścieżka czerwona).
Druga ważna struktura, do której SC wysyła dane dotyczące aktualnej pozycji oka znajduje się w korze czołowej (frontal cortex), a dokładniej, w tylnej części zakrętu czołowego środkowego (middle frontal gyrus) i w przylegającej do niego bruzdy przedśrodkowej (precentral sulcus). Struktura ta jest znana pod dosyć osobliwą nazwą korowego ośrodka skojarzonego spojrzenia w bok (frontal eye field; FEF). W rzeczywistości ośrodek ten jest odpowiedzialny za dowolny ruch sakadowy oka znajdującego się po przeciwnej stronie głowy oraz za płynny ruch gałek ocznych. Droga z SC do FEF prowadzi przez jądra grzbietowo-przyśrodkowe (dorsomedial nucleus), zlokalizowane we wzgórzu (ryc. 52, ścieżka żółta).
Obydwa te ośrodki, czyli IPS i FEF, po uzyskaniu wszystkich potrzebnych danych z jąder wzgórza, poduszki i struktur zlokalizowanych na wzrokowym szlaku grzbietowym (a zwłaszcza MT i MST), zajmują się: analizą danych dotyczących aktualnego położenia oka w stosunku do kadru sceny wizualnej, uzgadnianiem wyników tych analiz między sobą, a następnie zwrotnie, przekazaniem decyzji o zmianie położenia oka do SC (Gottlieb i Balan, 2010; Kable i Glimcher, 2009; Noudoost, Chang, Steinmetz i Moore, 2010; Wen, Yao, Liu i Ding, 2012) (ryc. 52, ścieżki pomarańczowe). Dane dotyczące współrzędnych nowej pozycji oka są nanoszone na retinotopową mapę siatkówki w wierzchniej warstwie SC i przekazywane dalej w formie instrukcji do wykonania.
Z SC informacja biegnie do niewielkiej grupy jąder, zlokalizowanych w przypośrodkowej części tworu siatkowatego mostu (paramedian pontine reticular formation; PPRF) dwoma ścieżkami. Jedna prowadzi bezpośrednio z SC do PPRF, a druga pośrednio, przez móżdżek (cerebellum), który bierze udział we wszystkich operacjach związanych z ruchem organizmu (Grossberg, Srihasam i Bullock, 2012) (ryc. 52, ścieżki purpurowe). Poprzez połączenia PPRF z jądrami nerwu okoruchowego, bloczkowego i odwodzącego sygnał jest w końcu wysyłany do trzech par mięśni zewnątrzgałkowych, za pośrednictwem III, IV i VI nerwu czaszkowego (ryc. 52, ścieżka filetowa). Mięśnie kurcząc się lub rozluźniając powodują ruch oka, czyli sakadę i tym samym ustanawiają nową pozycję środka kadru. Tak oto dobiega końca operacja wykonania pojedynczego ruchu gałek ocznych, która w normalnych warunkach na ogół nie zajmuje więcej niż 1/3 sekundy.
Ruch podążania
Spośród ruchów oczu, których celem jest utrzymywanie w kadrze niezbyt szybko poruszającego się obiektu w płaszczyźnie prostopadłej do osi widzenia, najważniejszy jest ruch podążania (smooth pursuit). Uzasadnieniem dla jego omówienia w książce poświęconej płaskiemu, nieruchomemu obrazowi jest to, że coraz częściej oglądamy takie właśnie obrazy na karoseriach tramwajów lub autobusów, a także na bilbordach ciągniętych na lawetach za samochodem.
Średnia prędkość ruchu podążania jest znacznie mniejsza niż prędkość sakad i za wyjątkiem jego pierwszej fazy na ogół nie przekracza 30°/sek. Ruch podążania rozpoczyna się ok. 100–150 ms po detekcji ruchu obiektu (Büttner i Kremmyda, 2007). Od tego momentu przez 40 ms oko rozpędza się w kierunku zgodnym z kierunkiem ruchu obiektu, usiłując go „dogonić”. W tym czasie prędkość oka może zwiększyć się nawet do 50°/sek. i w zależności od prędkości obiektu oraz odległości z jakiej jest oglądany, oś widzenia może przesunąć się przed obiekt lub pozostać nieco w tyle za nim. Tak czy inaczej, przez następne 60 ms oko z grubsza dopasowuje swoją prędkość do prędkości obiektu. Jest to pierwsza, tzw. swobodna faza ruchu podążania (open-loop pursuit). Jej celem jest po prostu zainicjowanie ruchu gałek ocznych i przesunięcie osi widzenia w tym kierunku, w którym przemieszcza się obiekt oraz w miarę możliwości doprowadzenie do tego, aby znalazł się na ich przecięciu. Przebieg tej fazy jest niemal identyczny u ludzi, jak i u małp (Carl i Gellman, 1987; Krauzlis i Lisberger, 1994).
Druga faza ruchu podążania polega na stałym utrzymywaniu spojrzenia na poruszającym się obiekcie. Przebiega ona na zasadzie powtarzających się pętli sprzężeń zwrotnych (closed-loop pursuit). Kilka razy na sekundę system wzrokowy sprawdza wielkości różnicy między pozycją poruszającego się obiektu a pozycją oka, a ściślej dołka centralnego. Początkowo korekta obu pozycji odbywa się 3–4 razy na sekundę i jeżeli obiekt porusza się mniej więcej ze stałą prędkością, zmniejsza się do 2–3 razy na sekundę (Leigh i Zee, 2006). W ten sposób, za pomocą krótkich skoków, osie widzenia stale przecinają poruszający się obiekt mniej więcej w tym samym miejscu. Ponieważ skoki oczu są niewielkie, a im dalej znajduje się przedmiot od obserwatora tym są krótsze, dlatego ruch podążania sprawia wrażenie, jakby był wygładzony (smooth) lub płynny, a nie skokowy.
Ciekawą własnością ruchu podążania jest jego inercja. Gdy śledzony obiekt zniknie nagle z pola widzenia (np. obserwowany samochód zostanie przysłonięty przez kępę przydrożnych drzew), wówczas przez ok. 4 sekundy oczy będą kontynuować ruch podążania w kierunku ustalonym przed zniknięciem tego obiektu (pomimo jego nieobecności w scenie), a ich prędkość powoli zacznie się zmniejszać, jednak nie mniej niż do 60% prędkości początkowej. Jeżeli po czterech sekundach od zniknięcia obiekt nie pojawi się ponownie w kadrze, wówczas ruch podążania wygasa (Barnes, 2008; Becker i Fuchs, 1985).
Mechanizm inercji ruchu podążania szacuje najbardziej prawdopodobny czas i miejsce wyłonienia się obiektu zza przeszkody po to, aby oczy mogły nadal utrzymywać na nim spojrzenie. Oczywiście warunkiem wystąpienia tego efektu jest stała prędkość i znany kierunek ruchu obiektu, a także możliwość obserwowania go przez pewien czas zanim zniknie z pola widzenia.
Warto również dodać, że system wzrokowy człowieka znacznie lepiej radzi sobie z utrzymywaniem spojrzenia na ruchomych obiektach, które w płaszczyźnie prostopadłej do osi widzenia przesuwają się horyzontalnie niż wertykalnie, a jeśli już wertykalnie to lepiej, gdy opadają niż się wznoszą (Grasse i Lisberger, 1992). Ten porządek odzwierciedla częstość, z jaką mamy do czynienia z określonym rodzajem ruchu obiektu w scenie wizualnej. Najczęściej widzimy obiekty poruszające się w płaszczyźnie horyzontalnej (w prawo lub w lewo), rzadziej w płaszczyźnie wertykalnej, z góry w dół (np. spadające przedmioty), a jeszcze rzadziej – w płaszczyźnie wertykalnej, z dołu do góry.
Neurofizjologiczny model ruchów podążania
Neurofizjologiczny mechanizm ruchu podążania łączy w sobie aż trzy programy okoruchowe: odruch przedsionkowy, ruch sakadyczny i specyficzny program podążania. Z odruchem przedsionkowym łączą go struktury podkorowe, zlokalizowane zwłaszcza w pniu mózgu (Cullen, 2009). Najczęściej bowiem, śledząc wolno przemieszczający się obiekt nie tylko wodzimy za nim wzrokiem, ale również poruszamy głową. Ruch podążania różni się jednak od odruchowego utrzymywania wzroku na obiekcie podczas poruszania głową przede wszystkim tym, że w znacznie większym stopniu jest on dowolny.
Podobnie, ruch podążania i sakadowy są kontrolowane przez wiele tych samych struktur, leżących na szlaku wzrokowym, począwszy od LGN, przez V1, MT i MST, a na FEF – kończąc (Grossberg, Srihasam i Bullock, 2012; Ilg, 2009). W odróżnieniu od ruchu sakadycznego, ruch podążania nie wymaga pośrednictwa struktur znajdujących się w górnym wzgórku blaszki czworaczej pnia mózgu (SC).
Wreszcie trzeci mechanizm, który odgrywa najważniejszą rolę w procesie dowolnej inicjacji i podtrzymywaniu ruchu podążania angażuje specyficzne struktury korowe związane ze znanym już z ruchów sakadowych, czołowym ośrodkiem skojarzonego spojrzenia w bok (FEF), takie jak czołowy ośrodek ruchu podążania (frontal pursuit area; FPA) i dodatkowy ośrodek skojarzonego spojrzenia w bok (supplementary eye field; SEF) (ryc. 52).